 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYour Graph Recommender is Provably a Single-view Graph Contrastive Learning
Paper and Code
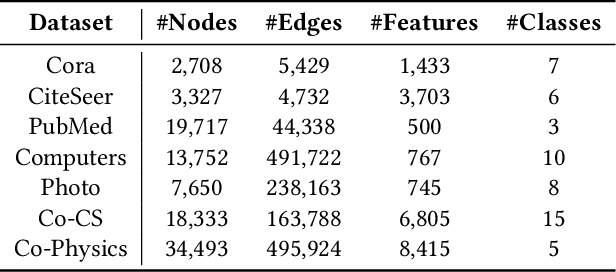
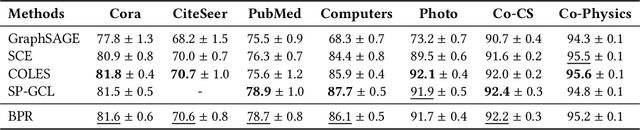
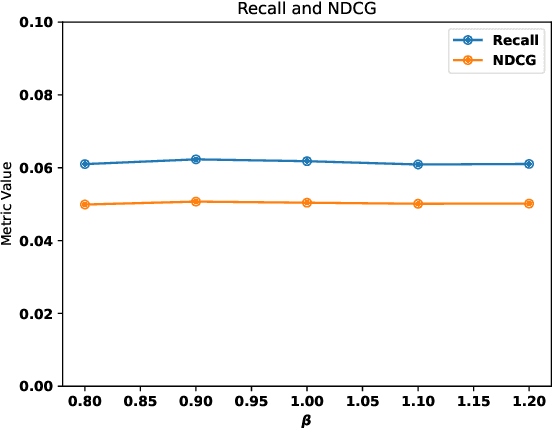
Graph recommender (GR) is a type of graph neural network (GNNs) encoder that is customized for extracting information from the user-item interaction graph. Due to its strong performance on the recommendation task, GR has gained significant attention recently. Graph contrastive learning (GCL) is also a popular research direction that aims to learn, often unsupervised, GNNs with certain contrastive objectives. As a general graph representation learning method, GCLs have been widely adopted with the supervised recommendation loss for joint training of GRs. Despite the intersection of GR and GCL research, theoretical understanding of the relationship between the two fields is surprisingly sparse. This vacancy inevitably leads to inefficient scientific research. In this paper, we aim to bridge the gap between the field of GR and GCL from the perspective of encoders and loss functions. With mild assumptions, we theoretically show an astonishing fact that graph recommender is equivalent to a commonly-used single-view graph contrastive model. Specifically, we find that (1) the classic encoder in GR is essentially a linear graph convolutional network with one-hot inputs, and (2) the loss function in GR is well bounded by a single-view GCL loss with certain hyperparameters. The first observation enables us to explain crucial designs of GR models, e.g., the removal of self-loop and nonlinearity. And the second finding can easily prompt many cross-field research directions. We empirically show a remarkable result that the recommendation loss and the GCL loss can be used interchangeably. The fact that we can train GR models solely with the GCL loss is particularly insightful, since before this work, GCLs were typically viewed as unsupervised methods that need fine-tuning. We also discuss some potential future works inspired by our theory.