 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRight Is Not Enough: The Pitfalls of Outcome Supervision in Training LLMs for Math Reasoning
Jun 07, 2025Outcome-rewarded Large Language Models (LLMs) have demonstrated remarkable success in mathematical problem-solving. However, this success often masks a critical issue: models frequently achieve correct answers through fundamentally unsound reasoning processes, a phenomenon indicative of reward hacking. We introduce MathOlympiadEval, a new dataset with fine-grained annotations, which reveals a significant gap between LLMs' answer correctness and their low process correctness. Existing automated methods like LLM-as-a-judge struggle to reliably detect these reasoning flaws. To address this, we propose ParaStepVerifier, a novel methodology for meticulous, step-by-step verification of mathematical solutions. ParaStepVerifier identifies incorrect reasoning steps. Empirical results demonstrate that ParaStepVerifier substantially improves the accuracy of identifying flawed solutions compared to baselines, especially for complex, multi-step problems. This offers a more robust path towards evaluating and training LLMs with genuine mathematical reasoning.
Your Graph Recommender is Provably a Single-view Graph Contrastive Learning
Jul 25, 2024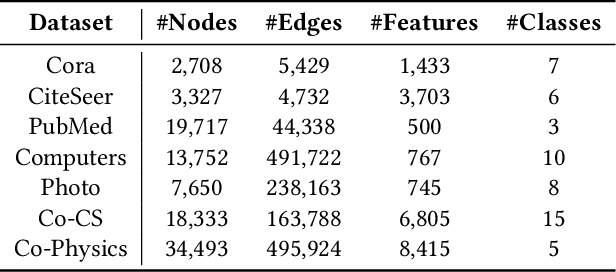
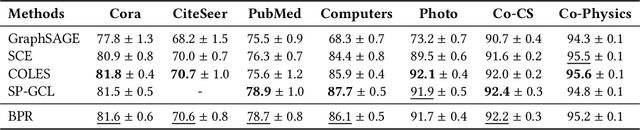
Graph recommender (GR) is a type of graph neural network (GNNs) encoder that is customized for extracting information from the user-item interaction graph. Due to its strong performance on the recommendation task, GR has gained significant attention recently. Graph contrastive learning (GCL) is also a popular research direction that aims to learn, often unsupervised, GNNs with certain contrastive objectives. As a general graph representation learning method, GCLs have been widely adopted with the supervised recommendation loss for joint training of GRs. Despite the intersection of GR and GCL research, theoretical understanding of the relationship between the two fields is surprisingly sparse. This vacancy inevitably leads to inefficient scientific research. In this paper, we aim to bridge the gap between the field of GR and GCL from the perspective of encoders and loss functions. With mild assumptions, we theoretically show an astonishing fact that graph recommender is equivalent to a commonly-used single-view graph contrastive model. Specifically, we find that (1) the classic encoder in GR is essentially a linear graph convolutional network with one-hot inputs, and (2) the loss function in GR is well bounded by a single-view GCL loss with certain hyperparameters. The first observation enables us to explain crucial designs of GR models, e.g., the removal of self-loop and nonlinearity. And the second finding can easily prompt many cross-field research directions. We empirically show a remarkable result that the recommendation loss and the GCL loss can be used interchangeably. The fact that we can train GR models solely with the GCL loss is particularly insightful, since before this work, GCLs were typically viewed as unsupervised methods that need fine-tuning. We also discuss some potential future works inspired by our theory.
Understanding Community Bias Amplification in Graph Representation Learning
Dec 08, 2023In this work, we discover a phenomenon of community bias amplification in graph representation learning, which refers to the exacerbation of performance bias between different classes by graph representation learning. We conduct an in-depth theoretical study of this phenomenon from a novel spectral perspective. Our analysis suggests that structural bias between communities results in varying local convergence speeds for node embeddings. This phenomenon leads to bias amplification in the classification results of downstream tasks. Based on the theoretical insights, we propose random graph coarsening, which is proved to be effective in dealing with the above issue. Finally, we propose a novel graph contrastive learning model called Random Graph Coarsening Contrastive Learning (RGCCL), which utilizes random coarsening as data augmentation and mitigates community bias by contrasting the coarsened graph with the original graph. Extensive experiments on various datasets demonstrate the advantage of our method when dealing with community bias amplification.
StructComp: Substituting propagation with Structural Compression in Training Graph Contrastive Learning
Dec 08, 2023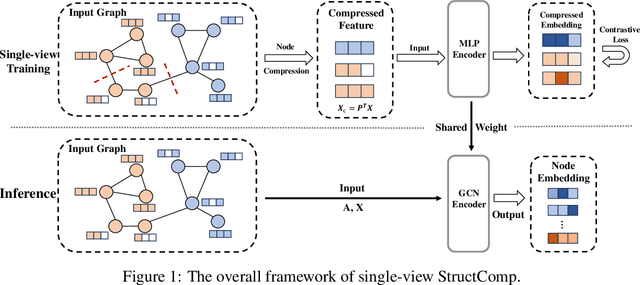
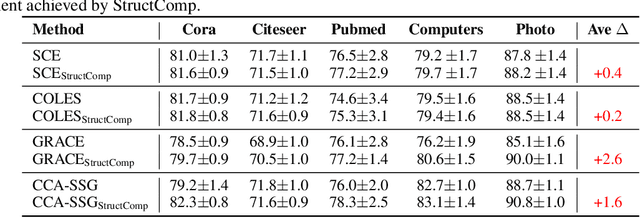
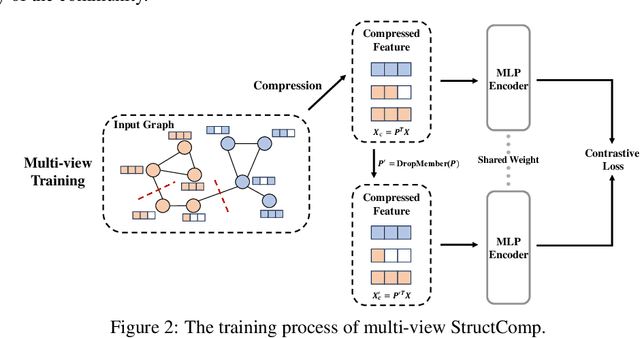
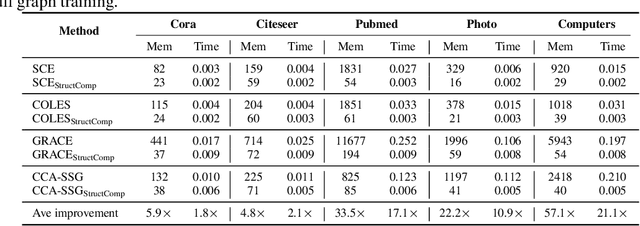
Graph contrastive learning (GCL) has become a powerful tool for learning graph data, but its scalability remains a significant challenge. In this work, we propose a simple yet effective training framework called Structural Compression (StructComp) to address this issue. Inspired by a sparse low-rank approximation on the diffusion matrix, StructComp trains the encoder with the compressed nodes. This allows the encoder not to perform any message passing during the training stage, and significantly reduces the number of sample pairs in the contrastive loss. We theoretically prove that the original GCL loss can be approximated with the contrastive loss computed by StructComp. Moreover, StructComp can be regarded as an additional regularization term for GCL models, resulting in a more robust encoder. Empirical studies on seven benchmark datasets show that StructComp greatly reduces the time and memory consumption while improving model performance compared to the vanilla GCL models and scalable training methods.
Rethinking Semi-Supervised Imbalanced Node Classification from Bias-Variance Decomposition
Oct 28, 2023


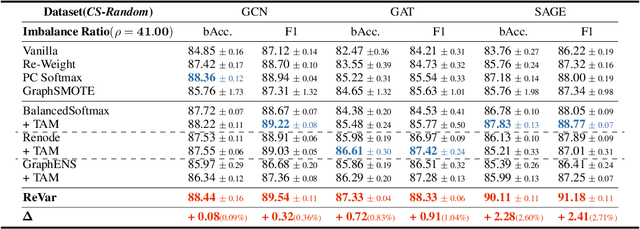
This paper introduces a new approach to address the issue of class imbalance in graph neural networks (GNNs) for learning on graph-structured data. Our approach integrates imbalanced node classification and Bias-Variance Decomposition, establishing a theoretical framework that closely relates data imbalance to model variance. We also leverage graph augmentation technique to estimate the variance, and design a regularization term to alleviate the impact of imbalance. Exhaustive tests are conducted on multiple benchmarks, including naturally imbalanced datasets and public-split class-imbalanced datasets, demonstrating that our approach outperforms state-of-the-art methods in various imbalanced scenarios. This work provides a novel theoretical perspective for addressing the problem of imbalanced node classification in GNNs.
UNREAL:Unlabeled Nodes Retrieval and Labeling for Heavily-imbalanced Node Classification
Mar 18, 2023Extremely skewed label distributions are common in real-world node classification tasks. If not dealt with appropriately, it significantly hurts the performance of GNNs in minority classes. Due to its practical importance, there have been a series of recent research devoted to this challenge. Existing over-sampling techniques smooth the label distribution by generating ``fake'' minority nodes and synthesizing their features and local topology, which largely ignore the rich information of unlabeled nodes on graphs. In this paper, we propose UNREAL, an iterative over-sampling method. The first key difference is that we only add unlabeled nodes instead of synthetic nodes, which eliminates the challenge of feature and neighborhood generation. To select which unlabeled nodes to add, we propose geometric ranking to rank unlabeled nodes. Geometric ranking exploits unsupervised learning in the node embedding space to effectively calibrates pseudo-label assignment. Finally, we identify the issue of geometric imbalance in the embedding space and provide a simple metric to filter out geometrically imbalanced nodes. Extensive experiments on real-world benchmark datasets are conducted, and the empirical results show that our method significantly outperforms current state-of-the-art methods consistent on different datasets with different imbalance ratios.
BSAL: A Framework of Bi-component Structure and Attribute Learning for Link Prediction
Apr 18, 2022

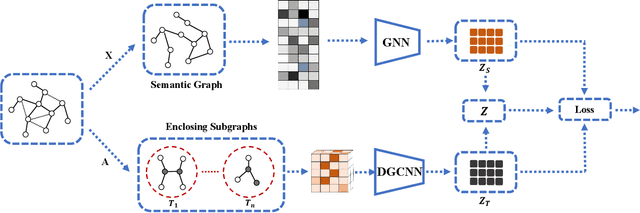

Given the ubiquitous existence of graph-structured data, learning the representations of nodes for the downstream tasks ranging from node classification, link prediction to graph classification is of crucial importance. Regarding missing link inference of diverse networks, we revisit the link prediction techniques and identify the importance of both the structural and attribute information. However, the available techniques either heavily count on the network topology which is spurious in practice or cannot integrate graph topology and features properly. To bridge the gap, we propose a bicomponent structural and attribute learning framework (BSAL) that is designed to adaptively leverage information from topology and feature spaces. Specifically, BSAL constructs a semantic topology via the node attributes and then gets the embeddings regarding the semantic view, which provides a flexible and easy-to-implement solution to adaptively incorporate the information carried by the node attributes. Then the semantic embedding together with topology embedding is fused together using an attention mechanism for the final prediction. Extensive experiments show the superior performance of our proposal and it significantly outperforms baselines on diverse research benchmarks.
Scaling Up Graph Neural Networks Via Graph Coarsening
Jun 09, 2021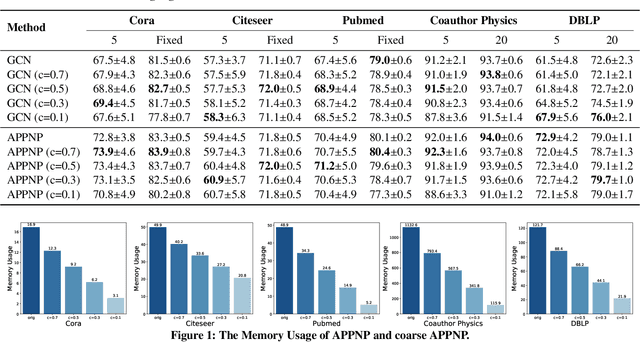
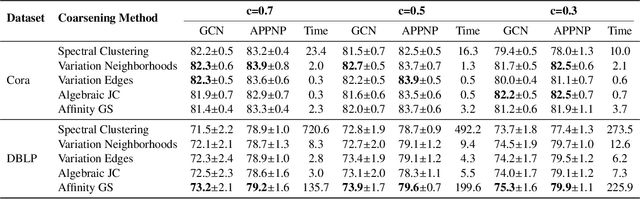
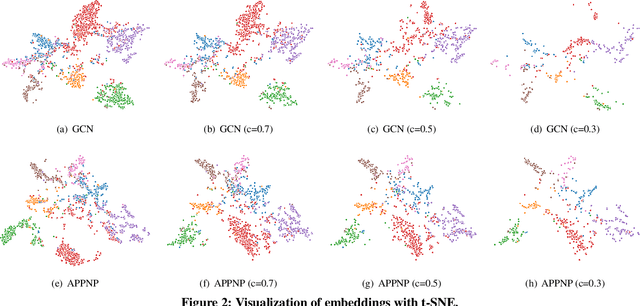
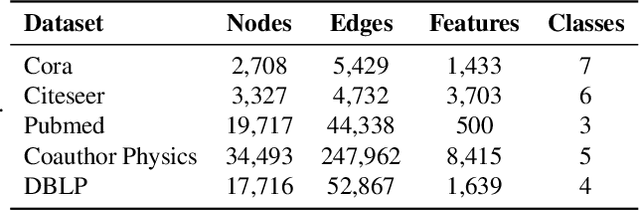
Scalability of graph neural networks remains one of the major challenges in graph machine learning. Since the representation of a node is computed by recursively aggregating and transforming representation vectors of its neighboring nodes from previous layers, the receptive fields grow exponentially, which makes standard stochastic optimization techniques ineffective. Various approaches have been proposed to alleviate this issue, e.g., sampling-based methods and techniques based on pre-computation of graph filters. In this paper, we take a different approach and propose to use graph coarsening for scalable training of GNNs, which is generic, extremely simple and has sublinear memory and time costs during training. We present extensive theoretical analysis on the effect of using coarsening operations and provides useful guidance on the choice of coarsening methods. Interestingly, our theoretical analysis shows that coarsening can also be considered as a type of regularization and may improve the generalization. Finally, empirical results on real world datasets show that, simply applying off-the-shelf coarsening methods, we can reduce the number of nodes by up to a factor of ten without causing a noticeable downgrade in classification accuracy.
SCE: Scalable Network Embedding from Sparsest Cut
Jul 17, 2020
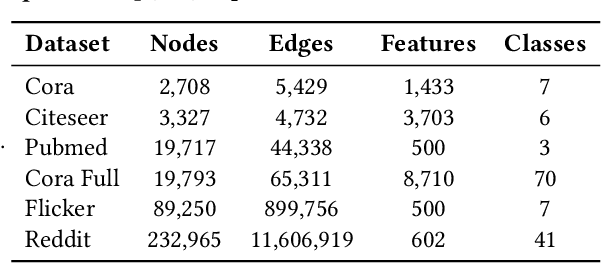
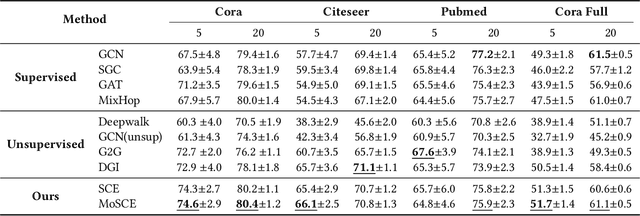
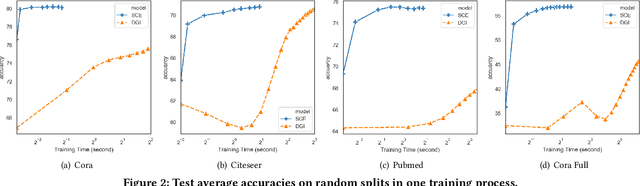
Large-scale network embedding is to learn a latent representation for each node in an unsupervised manner, which captures inherent properties and structural information of the underlying graph. In this field, many popular approaches are influenced by the skip-gram model from natural language processing. Most of them use a contrastive objective to train an encoder which forces the embeddings of similar pairs to be close and embeddings of negative samples to be far. A key of success to such contrastive learning methods is how to draw positive and negative samples. While negative samples that are generated by straightforward random sampling are often satisfying, methods for drawing positive examples remains a hot topic. In this paper, we propose SCE for unsupervised network embedding only using negative samples for training. Our method is based on a new contrastive objective inspired by the well-known sparsest cut problem. To solve the underlying optimization problem, we introduce a Laplacian smoothing trick, which uses graph convolutional operators as low-pass filters for smoothing node representations. The resulting model consists of a GCN-type structure as the encoder and a simple loss function. Notably, our model does not use positive samples but only negative samples for training, which not only makes the implementation and tuning much easier, but also reduces the training time significantly. Finally, extensive experimental studies on real world data sets are conducted. The results clearly demonstrate the advantages of our new model in both accuracy and scalability compared to strong baselines such as GraphSAGE, G2G and DGI.