 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProject and Generate: Divergence-Free Neural Operators for Incompressible Flows
Mar 25, 2026Learning-based models for fluid dynamics often operate in unconstrained function spaces, leading to physically inadmissible, unstable simulations. While penalty-based methods offer soft regularization, they provide no structural guarantees, resulting in spurious divergence and long-term collapse. In this work, we introduce a unified framework that enforces the incompressible continuity equation as a hard, intrinsic constraint for both deterministic and generative modeling. First, to project deterministic models onto the divergence-free subspace, we integrate a differentiable spectral Leray projection grounded in the Helmholtz-Hodge decomposition, which restricts the regression hypothesis space to physically admissible velocity fields. Second, to generate physically consistent distributions, we show that simply projecting model outputs is insufficient when the prior is incompatible. To address this, we construct a divergence-free Gaussian reference measure via a curl-based pushforward, ensuring the entire probability flow remains subspace-consistent by construction. Experiments on 2D Navier-Stokes equations demonstrate exact incompressibility up to discretization error and substantially improved stability and physical consistency.
Developing Foundation Models for Universal Segmentation from 3D Whole-Body Positron Emission Tomography
Mar 12, 2026Positron emission tomography (PET) is a key nuclear medicine imaging modality that visualizes radiotracer distributions to quantify in vivo physiological and metabolic processes, playing an irreplaceable role in disease management. Despite its clinical importance, the development of deep learning models for quantitative PET image analysis remains severely limited, driven by both the inherent segmentation challenge from PET's paucity of anatomical contrast and the high costs of data acquisition and annotation. To bridge this gap, we develop generalist foundational models for universal segmentation from 3D whole-body PET imaging. We first build the largest and most comprehensive PET dataset to date, comprising 11041 3D whole-body PET scans with 59831 segmentation masks for model development. Based on this dataset, we present SegAnyPET, an innovative foundational model with general-purpose applicability to diverse segmentation tasks. Built on a 3D architecture with a prompt engineering strategy for mask generation, SegAnyPET enables universal and scalable organ and lesion segmentation, supports efficient human correction with minimal effort, and enables a clinical human-in-the-loop workflow. Extensive evaluations on multi-center, multi-tracer, multi-disease datasets demonstrate that SegAnyPET achieves strong zero-shot performance across a wide range of segmentation tasks, highlighting its potential to advance the clinical applications of molecular imaging.
PIT: A Dynamic Personalized Item Tokenizer for End-to-End Generative Recommendation
Feb 09, 2026Generative Recommendation has revolutionized recommender systems by reformulating retrieval as a sequence generation task over discrete item identifiers. Despite the progress, existing approaches typically rely on static, decoupled tokenization that ignores collaborative signals. While recent methods attempt to integrate collaborative signals into item identifiers either during index construction or through end-to-end modeling, they encounter significant challenges in real-world production environments. Specifically, the volatility of collaborative signals leads to unstable tokenization, and current end-to-end strategies often devolve into suboptimal two-stage training rather than achieving true co-evolution. To bridge this gap, we propose PIT, a dynamic Personalized Item Tokenizer framework for end-to-end generative recommendation, which employs a co-generative architecture that harmonizes collaborative patterns through collaborative signal alignment and synchronizes item tokenizer with generative recommender via a co-evolution learning. This enables the dynamic, joint, end-to-end evolution of both index construction and recommendation. Furthermore, a one-to-many beam index ensures scalability and robustness, facilitating seamless integration into large-scale industrial deployments. Extensive experiments on real-world datasets demonstrate that PIT consistently outperforms competitive baselines. In a large-scale deployment at Kuaishou, an online A/B test yielded a substantial 0.402% uplift in App Stay Time, validating the framework's effectiveness in dynamic industrial environments.
Alleviating Sparse Rewards by Modeling Step-Wise and Long-Term Sampling Effects in Flow-Based GRPO
Feb 06, 2026Deploying GRPO on Flow Matching models has proven effective for text-to-image generation. However, existing paradigms typically propagate an outcome-based reward to all preceding denoising steps without distinguishing the local effect of each step. Moreover, current group-wise ranking mainly compares trajectories at matched timesteps and ignores within-trajectory dependencies, where certain early denoising actions can affect later states via delayed, implicit interactions. We propose TurningPoint-GRPO (TP-GRPO), a GRPO framework that alleviates step-wise reward sparsity and explicitly models long-term effects within the denoising trajectory. TP-GRPO makes two key innovations: (i) it replaces outcome-based rewards with step-level incremental rewards, providing a dense, step-aware learning signal that better isolates each denoising action's "pure" effect, and (ii) it identifies turning points-steps that flip the local reward trend and make subsequent reward evolution consistent with the overall trajectory trend-and assigns these actions an aggregated long-term reward to capture their delayed impact. Turning points are detected solely via sign changes in incremental rewards, making TP-GRPO efficient and hyperparameter-free. Extensive experiments also demonstrate that TP-GRPO exploits reward signals more effectively and consistently improves generation. Demo code is available at https://github.com/YunzeTong/TurningPoint-GRPO.
Co-Sight: Enhancing LLM-Based Agents via Conflict-Aware Meta-Verification and Trustworthy Reasoning with Structured Facts
Oct 24, 2025Long-horizon reasoning in LLM-based agents often fails not from generative weakness but from insufficient verification of intermediate reasoning. Co-Sight addresses this challenge by turning reasoning into a falsifiable and auditable process through two complementary mechanisms: Conflict-Aware Meta-Verification (CAMV) and Trustworthy Reasoning with Structured Facts (TRSF). CAMV reformulates verification as conflict identification and targeted falsification, allocating computation only to disagreement hotspots among expert agents rather than to full reasoning chains. This bounds verification cost to the number of inconsistencies and improves efficiency and reliability. TRSF continuously organizes, validates, and synchronizes evidence across agents through a structured facts module. By maintaining verified, traceable, and auditable knowledge, it ensures that all reasoning is grounded in consistent, source-verified information and supports transparent verification throughout the reasoning process. Together, TRSF and CAMV form a closed verification loop, where TRSF supplies structured facts and CAMV selectively falsifies or reinforces them, yielding transparent and trustworthy reasoning. Empirically, Co-Sight achieves state-of-the-art accuracy on GAIA (84.4%) and Humanity's Last Exam (35.5%), and strong results on Chinese-SimpleQA (93.8%). Ablation studies confirm that the synergy between structured factual grounding and conflict-aware verification drives these improvements. Co-Sight thus offers a scalable paradigm for reliable long-horizon reasoning in LLM-based agents. Code is available at https://github.com/ZTE-AICloud/Co-Sight/tree/cosight2.0_benchmarks.
Prompt-based Multimodal Semantic Communication for Multi-spectral Image Segmentation
Aug 25, 2025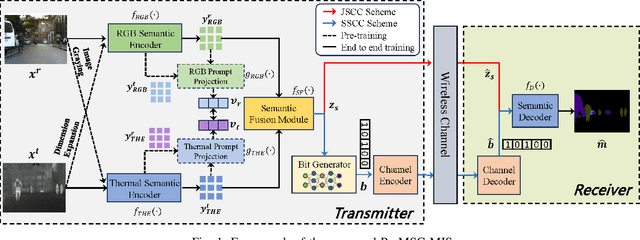
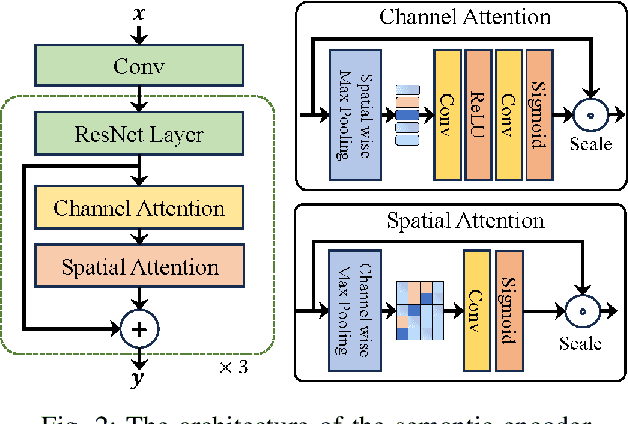
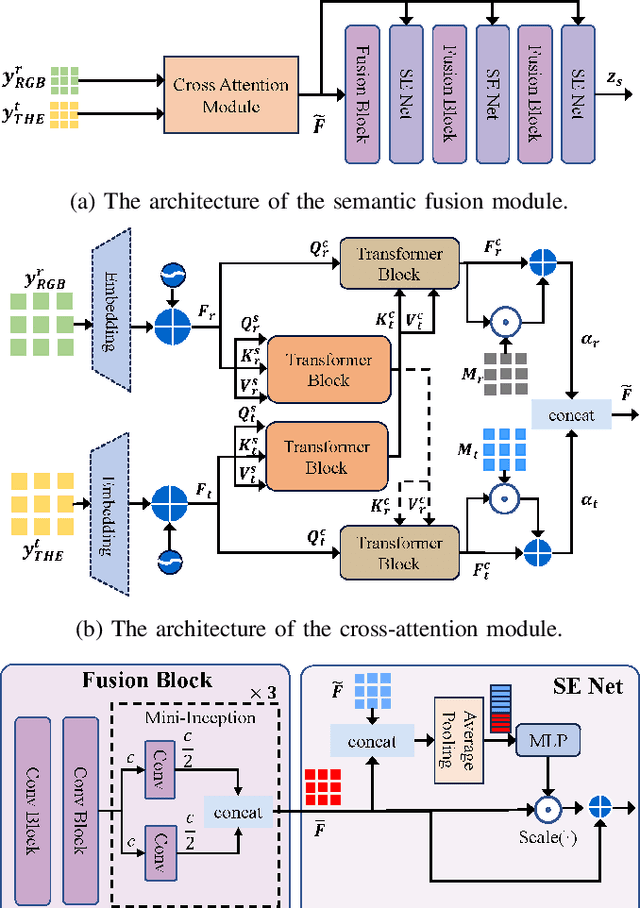
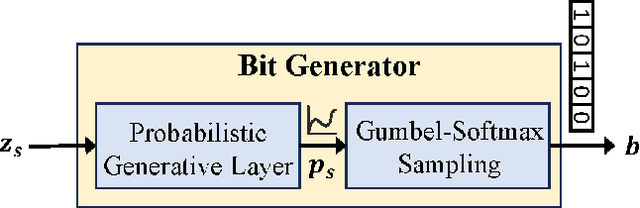
Multimodal semantic communication has gained widespread attention due to its ability to enhance downstream task performance. A key challenge in such systems is the effective fusion of features from different modalities, which requires the extraction of rich and diverse semantic representations from each modality. To this end, we propose ProMSC-MIS, a Prompt-based Multimodal Semantic Communication system for Multi-spectral Image Segmentation. Specifically, we propose a pre-training algorithm where features from one modality serve as prompts for another, guiding unimodal semantic encoders to learn diverse and complementary semantic representations. We further introduce a semantic fusion module that combines cross-attention mechanisms and squeeze-and-excitation (SE) networks to effectively fuse cross-modal features. Simulation results show that ProMSC-MIS significantly outperforms benchmark methods across various channel-source compression levels, while maintaining low computational complexity and storage overhead. Our scheme has great potential for applications such as autonomous driving and nighttime surveillance.
PET2Rep: Towards Vision-Language Model-Drived Automated Radiology Report Generation for Positron Emission Tomography
Aug 06, 2025Positron emission tomography (PET) is a cornerstone of modern oncologic and neurologic imaging, distinguished by its unique ability to illuminate dynamic metabolic processes that transcend the anatomical focus of traditional imaging technologies. Radiology reports are essential for clinical decision making, yet their manual creation is labor-intensive and time-consuming. Recent advancements of vision-language models (VLMs) have shown strong potential in medical applications, presenting a promising avenue for automating report generation. However, existing applications of VLMs in the medical domain have predominantly focused on structural imaging modalities, while the unique characteristics of molecular PET imaging have largely been overlooked. To bridge the gap, we introduce PET2Rep, a large-scale comprehensive benchmark for evaluation of general and medical VLMs for radiology report generation for PET images. PET2Rep stands out as the first dedicated dataset for PET report generation with metabolic information, uniquely capturing whole-body image-report pairs that cover dozens of organs to fill the critical gap in existing benchmarks and mirror real-world clinical comprehensiveness. In addition to widely recognized natural language generation metrics, we introduce a series of clinical efficiency metrics to evaluate the quality of radiotracer uptake pattern description in key organs in generated reports. We conduct a head-to-head comparison of 30 cutting-edge general-purpose and medical-specialized VLMs. The results show that the current state-of-the-art VLMs perform poorly on PET report generation task, falling considerably short of fulfilling practical needs. Moreover, we identify several key insufficiency that need to be addressed to advance the development in medical applications.
Efficient Network Automatic Relevance Determination
Jun 14, 2025



We propose Network Automatic Relevance Determination (NARD), an extension of ARD for linearly probabilistic models, to simultaneously model sparse relationships between inputs $X \in \mathbb R^{d \times N}$ and outputs $Y \in \mathbb R^{m \times N}$, while capturing the correlation structure among the $Y$. NARD employs a matrix normal prior which contains a sparsity-inducing parameter to identify and discard irrelevant features, thereby promoting sparsity in the model. Algorithmically, it iteratively updates both the precision matrix and the relationship between $Y$ and the refined inputs. To mitigate the computational inefficiencies of the $\mathcal O(m^3 + d^3)$ cost per iteration, we introduce Sequential NARD, which evaluates features sequentially, and a Surrogate Function Method, leveraging an efficient approximation of the marginal likelihood and simplifying the calculation of determinant and inverse of an intermediate matrix. Combining the Sequential update with the Surrogate Function method further reduces computational costs. The computational complexity per iteration for these three methods is reduced to $\mathcal O(m^3+p^3)$, $\mathcal O(m^3 + d^2)$, $\mathcal O(m^3+p^2)$, respectively, where $p \ll d$ is the final number of features in the model. Our methods demonstrate significant improvements in computational efficiency with comparable performance on both synthetic and real-world datasets.
Fast on the Easy, Deep on the Hard: Efficient Reasoning via Powered Length Penalty
Jun 12, 2025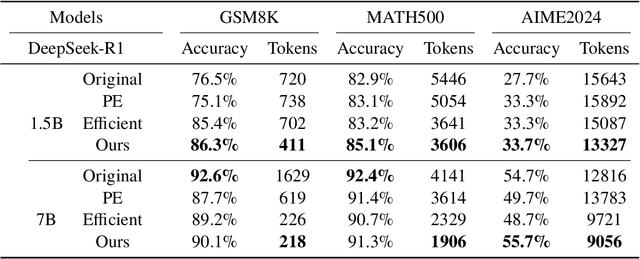
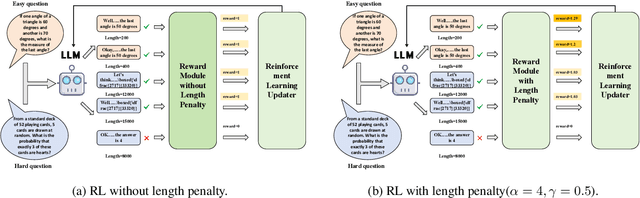

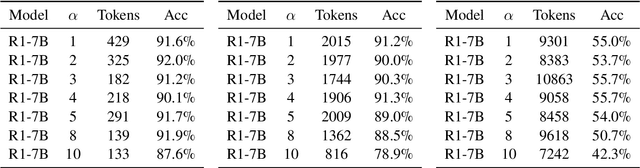
Large language models (LLMs) have demonstrated significant advancements in reasoning capabilities, performing well on various challenging benchmarks. Techniques like Chain-of-Thought prompting have been introduced to further improve reasoning. However, these approaches frequently generate longer outputs, which in turn increase computational latency. Although some methods use reinforcement learning to shorten reasoning, they often apply uniform penalties without considering the problem's complexity, leading to suboptimal outcomes. In this study, we seek to enhance the efficiency of LLM reasoning by promoting conciseness for simpler problems while preserving sufficient reasoning for more complex ones for accuracy, thus improving the model's overall performance. Specifically, we manage the model's reasoning efficiency by dividing the reward function and including a novel penalty for output length. Our approach has yielded impressive outcomes in benchmark evaluations across three datasets: GSM8K, MATH500, and AIME2024. For the comparatively simpler datasets GSM8K and MATH500, our method has effectively shortened output lengths while preserving or enhancing accuracy. On the more demanding AIME2024 dataset, our approach has resulted in improved accuracy.
ChromFound: Towards A Universal Foundation Model for Single-Cell Chromatin Accessibility Data
May 19, 2025The advent of single-cell Assay for Transposase-Accessible Chromatin using sequencing (scATAC-seq) offers an innovative perspective for deciphering regulatory mechanisms by assembling a vast repository of single-cell chromatin accessibility data. While foundation models have achieved significant success in single-cell transcriptomics, there is currently no foundation model for scATAC-seq that supports zero-shot high-quality cell identification and comprehensive multi-omics analysis simultaneously. Key challenges lie in the high dimensionality and sparsity of scATAC-seq data, as well as the lack of a standardized schema for representing open chromatin regions (OCRs). Here, we present \textbf{ChromFound}, a foundation model tailored for scATAC-seq. ChromFound utilizes a hybrid architecture and genome-aware tokenization to effectively capture genome-wide long contexts and regulatory signals from dynamic chromatin landscapes. Pretrained on 1.97 million cells from 30 tissues and 6 disease conditions, ChromFound demonstrates broad applicability across 6 diverse tasks. Notably, it achieves robust zero-shot performance in generating universal cell representations and exhibits excellent transferability in cell type annotation and cross-omics prediction. By uncovering enhancer-gene links undetected by existing computational methods, ChromFound offers a promising framework for understanding disease risk variants in the noncoding genome.