 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTabCF: Distributional Control Function Estimation with Tabular Foundation Models
May 07, 2026Instrumental variable (IV) and control function (CF) methods are powerful tools for causal effect estimation in the presence of unmeasured confounding, yet most existing approaches target only mean effects and/or demand substantial fitting and tuning effort. In this paper, we introduce a simple method, TabCF, for control function regression using tabular foundation models, which enables accurate, fast, identification-transparent, and tuning-light causal estimation of distributional quantities, such as interventional means and quantiles; we also propose a copula-based approximation for multivariate outcomes. TabCF performs favorably against representative methods across a broad range of small- to medium-sized synthetic and real data scenarios. The central message is two-fold: for practitioners, it highlights that TabCF is an effective tool for distributional causal inference; for researchers, it suggests that the proposed approach could be considered a strong baseline for future method development. Code is available at https://github.com/GepingChen/TabCF.
LLMTaxo: Leveraging Large Language Models for Constructing Taxonomy of Factual Claims from Social Media
Apr 11, 2025With the vast expansion of content on social media platforms, analyzing and comprehending online discourse has become increasingly complex. This paper introduces LLMTaxo, a novel framework leveraging large language models for the automated construction of taxonomy of factual claims from social media by generating topics from multi-level granularities. This approach aids stakeholders in more effectively navigating the social media landscapes. We implement this framework with different models across three distinct datasets and introduce specially designed taxonomy evaluation metrics for a comprehensive assessment. With the evaluations from both human evaluators and GPT-4, the results indicate that LLMTaxo effectively categorizes factual claims from social media, and reveals that certain models perform better on specific datasets.
ReVeal: A Physics-Informed Neural Network for High-Fidelity Radio Environment Mapping
Feb 27, 2025Accurately mapping the radio environment (e.g., identifying wireless signal strength at specific frequency bands and geographic locations) is crucial for efficient spectrum sharing, enabling secondary users (SUs) to access underutilized spectrum bands while protecting primary users (PUs). However, current models are either not generalizable due to shadowing, interference, and fading or are computationally too expensive, limiting real-world applicability. To address the shortcomings of existing models, we derive a second-order partial differential equation (PDE) for the Received Signal Strength Indicator (RSSI) based on a statistical model used in the literature. We then propose ReVeal (Re-constructor and Visualizer of Spectrum Landscape), a novel Physics-Informed Neural Network (PINN) that integrates the PDE residual into a neural network loss function to accurately model the radio environment based on sparse RF sensor measurements. ReVeal is validated using real-world measurement data from the rural and suburban areas of the ARA testbed and benchmarked against existing methods.ReVeal outperforms the existing methods in predicting the radio environment; for instance, with a root mean square error (RMSE) of only 1.95 dB, ReVeal achieves an accuracy that is an order of magnitude higher than existing methods such as the 3GPP and ITU-R channel models, ray-tracing, and neural networks. ReVeal achieves both high accuracy and low computational complexity while only requiring sparse RF sampling, for instance, only requiring 30 training sample points across an area of 514 square kilometers.
MuRAR: A Simple and Effective Multimodal Retrieval and Answer Refinement Framework for Multimodal Question Answering
Aug 16, 2024



Recent advancements in retrieval-augmented generation (RAG) have demonstrated impressive performance in the question-answering (QA) task. However, most previous works predominantly focus on text-based answers. While some studies address multimodal data, they still fall short in generating comprehensive multimodal answers, particularly for explaining concepts or providing step-by-step tutorials on how to accomplish specific goals. This capability is especially valuable for applications such as enterprise chatbots and settings such as customer service and educational systems, where the answers are sourced from multimodal data. In this paper, we introduce a simple and effective framework named MuRAR (Multimodal Retrieval and Answer Refinement). MuRAR enhances text-based answers by retrieving relevant multimodal data and refining the responses to create coherent multimodal answers. This framework can be easily extended to support multimodal answers in enterprise chatbots with minimal modifications. Human evaluation results indicate that multimodal answers generated by MuRAR are more useful and readable compared to plain text answers.
Wireless Spectrum in Rural Farmlands: Status, Challenges and Opportunities
Jul 05, 2024



Due to factors such as low population density and expansive geographical distances, network deployment falls behind in rural regions, leading to a broadband divide. Wireless spectrum serves as the blood and flesh of wireless communications. Shared white spaces such as those in the TVWS and CBRS spectrum bands offer opportunities to expand connectivity, innovate, and provide affordable access to high-speed Internet in under-served areas without additional cost to expensive licensed spectrum. However, the current methods to utilize these white spaces are inefficient due to very conservative models and spectrum policies, causing under-utilization of valuable spectrum resources. This hampers the full potential of innovative wireless technologies that could benefit farmers, small Internet Service Providers (ISPs) or Mobile Network Operators (MNOs) operating in rural regions. This study explores the challenges faced by farmers and service providers when using shared spectrum bands to deploy their networks while ensuring maximum system performance and minimizing interference with other users. Additionally, we discuss how spatiotemporal spectrum models, in conjunction with database-driven spectrum-sharing solutions, can enhance the allocation and management of spectrum resources, ultimately improving the efficiency and reliability of wireless networks operating in shared spectrum bands.
NET-FLEET: Achieving Linear Convergence Speedup for Fully Decentralized Federated Learning with Heterogeneous Data
Aug 17, 2022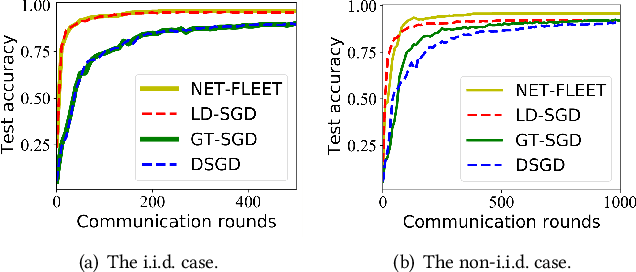
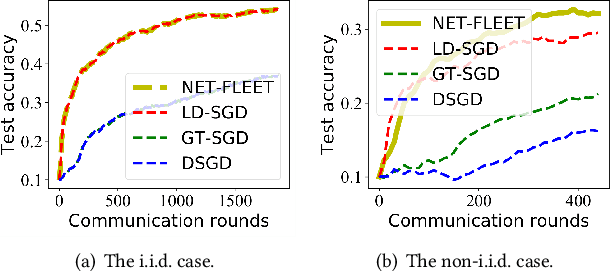
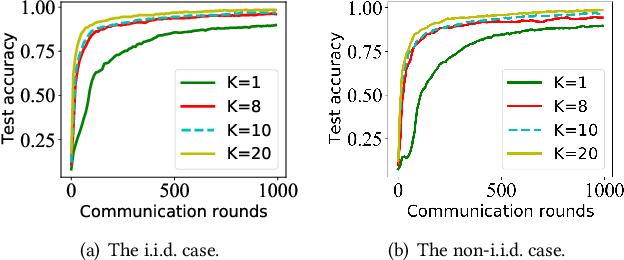
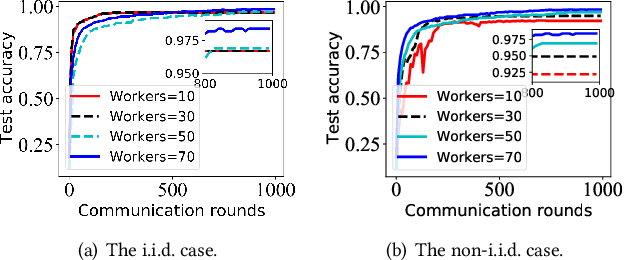
Federated learning (FL) has received a surge of interest in recent years thanks to its benefits in data privacy protection, efficient communication, and parallel data processing. Also, with appropriate algorithmic designs, one could achieve the desirable linear speedup for convergence effect in FL. However, most existing works on FL are limited to systems with i.i.d. data and centralized parameter servers and results on decentralized FL with heterogeneous datasets remains limited. Moreover, whether or not the linear speedup for convergence is achievable under fully decentralized FL with data heterogeneity remains an open question. In this paper, we address these challenges by proposing a new algorithm, called NET-FLEET, for fully decentralized FL systems with data heterogeneity. The key idea of our algorithm is to enhance the local update scheme in FL (originally intended for communication efficiency) by incorporating a recursive gradient correction technique to handle heterogeneous datasets. We show that, under appropriate parameter settings, the proposed NET-FLEET algorithm achieves a linear speedup for convergence. We further conduct extensive numerical experiments to evaluate the performance of the proposed NET-FLEET algorithm and verify our theoretical findings.
GT-STORM: Taming Sample, Communication, and Memory Complexities in Decentralized Non-Convex Learning
May 19, 2021
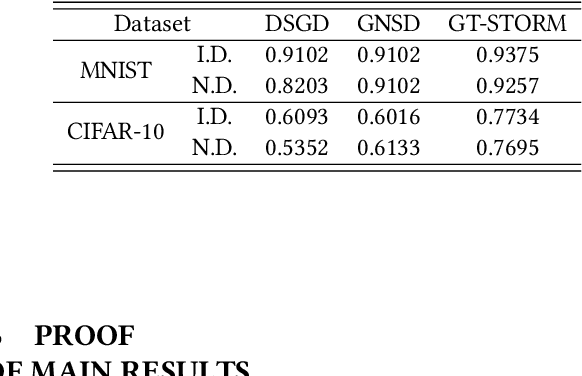
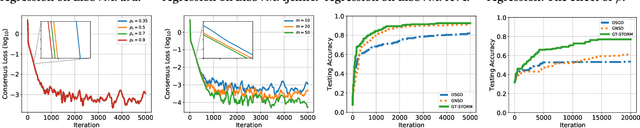
Decentralized nonconvex optimization has received increasing attention in recent years in machine learning due to its advantages in system robustness, data privacy, and implementation simplicity. However, three fundamental challenges in designing decentralized optimization algorithms are how to reduce their sample, communication, and memory complexities. In this paper, we propose a \underline{g}radient-\underline{t}racking-based \underline{sto}chastic \underline{r}ecursive \underline{m}omentum (GT-STORM) algorithm for efficiently solving nonconvex optimization problems. We show that to reach an $\epsilon^2$-stationary solution, the total number of sample evaluations of our algorithm is $\tilde{O}(m^{1/2}\epsilon^{-3})$ and the number of communication rounds is $\tilde{O}(m^{-1/2}\epsilon^{-3})$, which improve the $O(\epsilon^{-4})$ costs of sample evaluations and communications for the existing decentralized stochastic gradient algorithms. We conduct extensive experiments with a variety of learning models, including non-convex logistical regression and convolutional neural networks, to verify our theoretical findings. Collectively, our results contribute to the state of the art of theories and algorithms for decentralized network optimization.
Private and Communication-Efficient Edge Learning: A Sparse Differential Gaussian-Masking Distributed SGD Approach
Jan 19, 2020
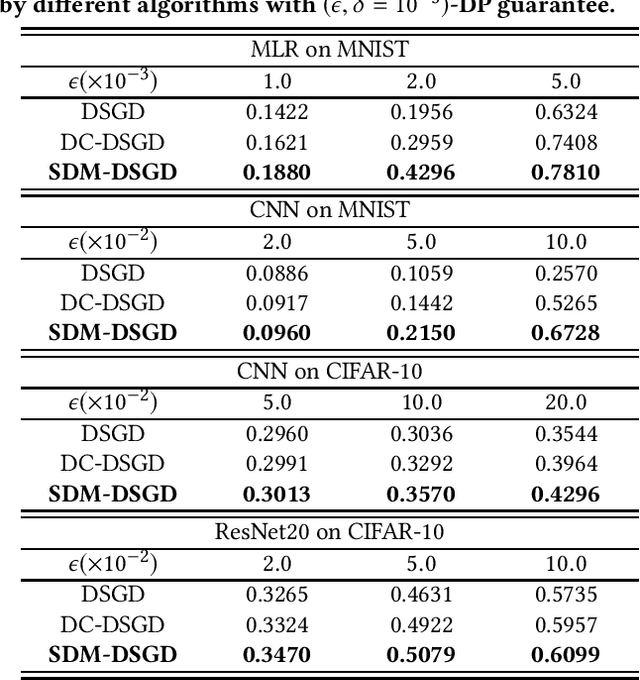
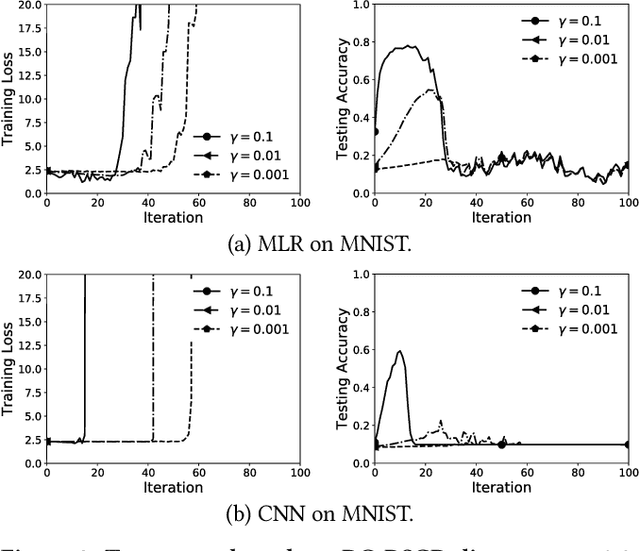
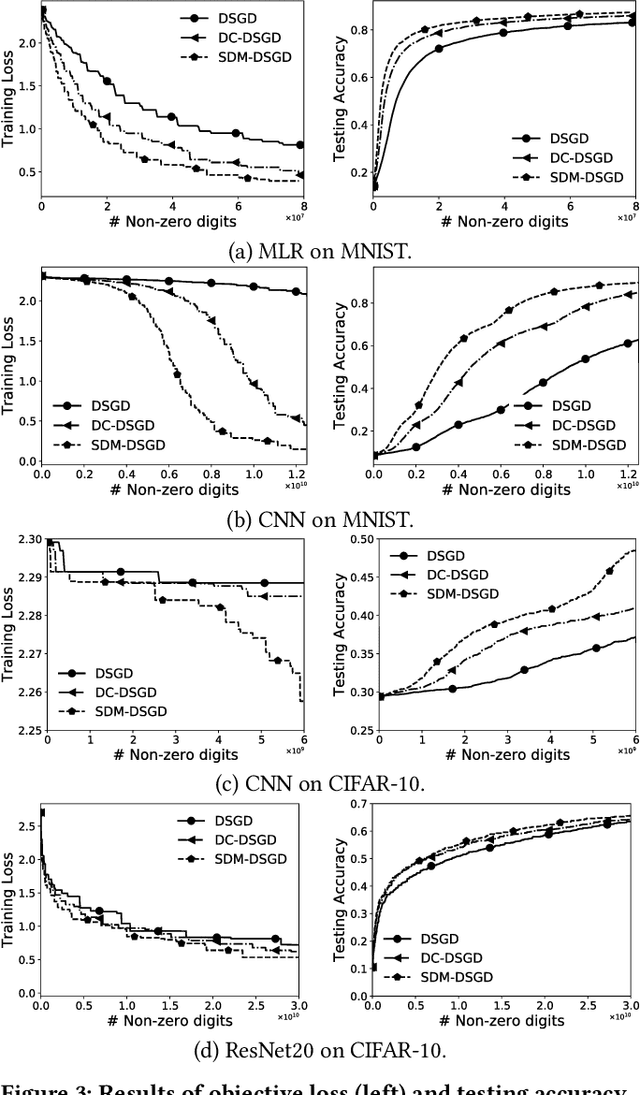
With rise of machine learning (ML) and the proliferation of smart mobile devices, recent years have witnessed a surge of interest in performing ML in wireless edge networks. In this paper, we consider the problem of jointly improving data privacy and communication efficiency of distributed edge learning, both of which are critical performance metrics in wireless edge network computing. Toward this end, we propose a new decentralized stochastic gradient method with sparse differential Gaussian-masked stochastic gradients (SDM-DSGD) for non-convex distributed edge learning. Our main contributions are three-fold: i) We theoretically establish the privacy and communication efficiency performance guarantee of our SDM-DSGD method, which outperforms all existing works; ii) We show that SDM-DSGD improves the fundamental training-privacy trade-off by {\em two orders of magnitude} compared with the state-of-the-art. iii) We reveal theoretical insights and offer practical design guidelines for the interactions between privacy preservation and communication efficiency, two conflicting performance goals. We conduct extensive experiments with a variety of learning models on MNIST and CIFAR-10 datasets to verify our theoretical findings. Collectively, our results contribute to the theory and algorithm design for distributed edge learning.
Distributed Linear Model Clustering over Networks: A Tree-Based Fused-Lasso ADMM Approach
May 28, 2019

In this work, we consider to improve the model estimation efficiency by aggregating the neighbors' information as well as identify the subgroup membership for each node in the network. A tree-based $l_1$ penalty is proposed to save the computation and communication cost. We design a decentralized generalized alternating direction method of multiplier algorithm for solving the objective function in parallel. The theoretical properties are derived to guarantee both the model consistency and the algorithm convergence. Thorough numerical experiments are also conducted to back up our theory, which also show that our approach outperforms in the aspects of the estimation accuracy, computation speed and communication cost.
Regression-Enhanced Random Forests
Apr 23, 2019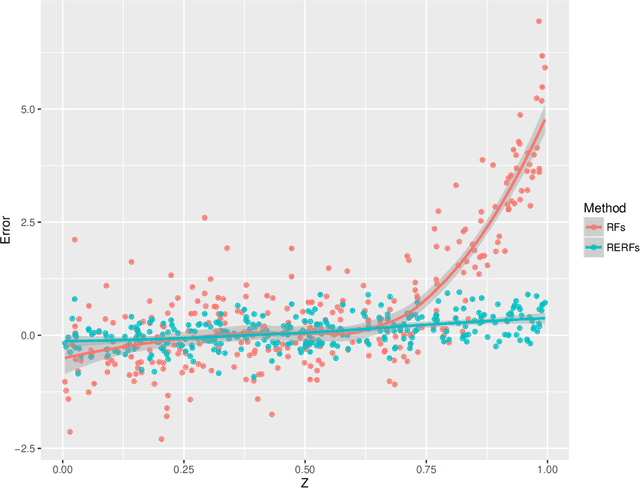

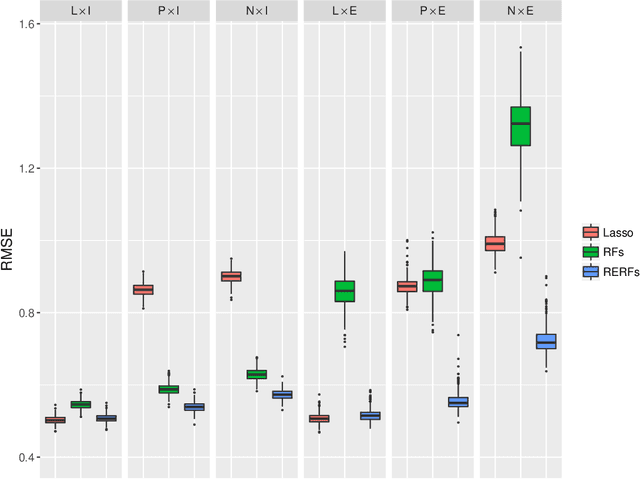
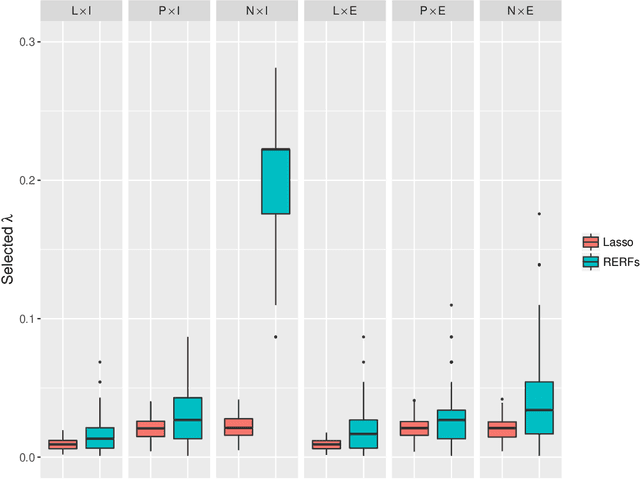
Random forest (RF) methodology is one of the most popular machine learning techniques for prediction problems. In this article, we discuss some cases where random forests may suffer and propose a novel generalized RF method, namely regression-enhanced random forests (RERFs), that can improve on RFs by borrowing the strength of penalized parametric regression. The algorithm for constructing RERFs and selecting its tuning parameters is described. Both simulation study and real data examples show that RERFs have better predictive performance than RFs in important situations often encountered in practice. Moreover, RERFs may incorporate known relationships between the response and the predictors, and may give reliable predictions in extrapolation problems where predictions are required at points out of the domain of the training dataset. Strategies analogous to those described here can be used to improve other machine learning methods via combination with penalized parametric regression techniques.
* 12 pages, 5 figures