 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Retrieval Augmented Generation for Multi-Product Question Answering
Jan 25, 2025



Recent advancements in Large Language Models and Retrieval-Augmented Generation have boosted interest in domain-specific question-answering for enterprise products. However, AI Assistants often face challenges in multi-product QA settings, requiring accurate responses across diverse domains. Existing multi-domain RAG-QA approaches either query all domains indiscriminately, increasing computational costs and LLM hallucinations, or rely on rigid resource selection, which can limit search results. We introduce MKP-QA, a novel multi-product knowledge-augmented QA framework with probabilistic federated search across domains and relevant knowledge. This method enhances multi-domain search quality by aggregating query-domain and query-passage probabilistic relevance. To address the lack of suitable benchmarks for multi-product QAs, we also present new datasets focused on three Adobe products: Adobe Experience Platform, Target, and Customer Journey Analytics. Our experiments show that MKP-QA significantly boosts multi-product RAG-QA performance in terms of both retrieval accuracy and response quality.
Enhancing Discoverability in Enterprise Conversational Systems with Proactive Question Suggestions
Dec 14, 2024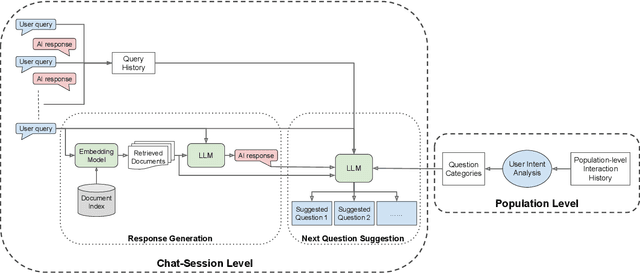

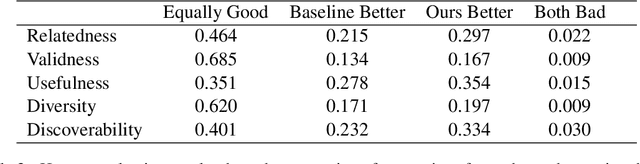

Enterprise conversational AI systems are becoming increasingly popular to assist users in completing daily tasks such as those in marketing and customer management. However, new users often struggle to ask effective questions, especially in emerging systems with unfamiliar or evolving capabilities. This paper proposes a framework to enhance question suggestions in conversational enterprise AI systems by generating proactive, context-aware questions that try to address immediate user needs while improving feature discoverability. Our approach combines periodic user intent analysis at the population level with chat session-based question generation. We evaluate the framework using real-world data from the AI Assistant for Adobe Experience Platform (AEP), demonstrating the improved usefulness and system discoverability of the AI Assistant.
RETAIN: Interactive Tool for Regression Testing Guided LLM Migration
Sep 05, 2024



Large Language Models (LLMs) are increasingly integrated into diverse applications. The rapid evolution of LLMs presents opportunities for developers to enhance applications continuously. However, this constant adaptation can also lead to performance regressions during model migrations. While several interactive tools have been proposed to streamline the complexity of prompt engineering, few address the specific requirements of regression testing for LLM Migrations. To bridge this gap, we introduce RETAIN (REgression Testing guided LLM migrAtIoN), a tool designed explicitly for regression testing in LLM Migrations. RETAIN comprises two key components: an interactive interface tailored to regression testing needs during LLM migrations, and an error discovery module that facilitates understanding of differences in model behaviors. The error discovery module generates textual descriptions of various errors or differences between model outputs, providing actionable insights for prompt refinement. Our automatic evaluation and empirical user studies demonstrate that RETAIN, when compared to manual evaluation, enabled participants to identify twice as many errors, facilitated experimentation with 75% more prompts, and achieves 12% higher metric scores in a given time frame.
MuRAR: A Simple and Effective Multimodal Retrieval and Answer Refinement Framework for Multimodal Question Answering
Aug 16, 2024



Recent advancements in retrieval-augmented generation (RAG) have demonstrated impressive performance in the question-answering (QA) task. However, most previous works predominantly focus on text-based answers. While some studies address multimodal data, they still fall short in generating comprehensive multimodal answers, particularly for explaining concepts or providing step-by-step tutorials on how to accomplish specific goals. This capability is especially valuable for applications such as enterprise chatbots and settings such as customer service and educational systems, where the answers are sourced from multimodal data. In this paper, we introduce a simple and effective framework named MuRAR (Multimodal Retrieval and Answer Refinement). MuRAR enhances text-based answers by retrieving relevant multimodal data and refining the responses to create coherent multimodal answers. This framework can be easily extended to support multimodal answers in enterprise chatbots with minimal modifications. Human evaluation results indicate that multimodal answers generated by MuRAR are more useful and readable compared to plain text answers.
GenVideo: One-shot Target-image and Shape Aware Video Editing using T2I Diffusion Models
Apr 18, 2024



Video editing methods based on diffusion models that rely solely on a text prompt for the edit are hindered by the limited expressive power of text prompts. Thus, incorporating a reference target image as a visual guide becomes desirable for precise control over edit. Also, most existing methods struggle to accurately edit a video when the shape and size of the object in the target image differ from the source object. To address these challenges, we propose "GenVideo" for editing videos leveraging target-image aware T2I models. Our approach handles edits with target objects of varying shapes and sizes while maintaining the temporal consistency of the edit using our novel target and shape aware InvEdit masks. Further, we propose a novel target-image aware latent noise correction strategy during inference to improve the temporal consistency of the edits. Experimental analyses indicate that GenVideo can effectively handle edits with objects of varying shapes, where existing approaches fail.
LEAD: Self-Supervised Landmark Estimation by Aligning Distributions of Feature Similarity
Apr 06, 2022
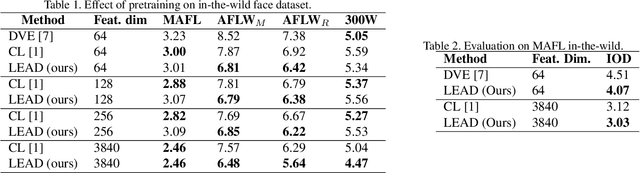


In this work, we introduce LEAD, an approach to discover landmarks from an unannotated collection of category-specific images. Existing works in self-supervised landmark detection are based on learning dense (pixel-level) feature representations from an image, which are further used to learn landmarks in a semi-supervised manner. While there have been advances in self-supervised learning of image features for instance-level tasks like classification, these methods do not ensure dense equivariant representations. The property of equivariance is of interest for dense prediction tasks like landmark estimation. In this work, we introduce an approach to enhance the learning of dense equivariant representations in a self-supervised fashion. We follow a two-stage training approach: first, we train a network using the BYOL objective which operates at an instance level. The correspondences obtained through this network are further used to train a dense and compact representation of the image using a lightweight network. We show that having such a prior in the feature extractor helps in landmark detection, even under drastically limited number of annotations while also improving generalization across scale variations.