 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenVideo: One-shot Target-image and Shape Aware Video Editing using T2I Diffusion Models
Apr 18, 2024



Video editing methods based on diffusion models that rely solely on a text prompt for the edit are hindered by the limited expressive power of text prompts. Thus, incorporating a reference target image as a visual guide becomes desirable for precise control over edit. Also, most existing methods struggle to accurately edit a video when the shape and size of the object in the target image differ from the source object. To address these challenges, we propose "GenVideo" for editing videos leveraging target-image aware T2I models. Our approach handles edits with target objects of varying shapes and sizes while maintaining the temporal consistency of the edit using our novel target and shape aware InvEdit masks. Further, we propose a novel target-image aware latent noise correction strategy during inference to improve the temporal consistency of the edits. Experimental analyses indicate that GenVideo can effectively handle edits with objects of varying shapes, where existing approaches fail.
CoralStyleCLIP: Co-optimized Region and Layer Selection for Image Editing
Mar 09, 2023



Edit fidelity is a significant issue in open-world controllable generative image editing. Recently, CLIP-based approaches have traded off simplicity to alleviate these problems by introducing spatial attention in a handpicked layer of a StyleGAN. In this paper, we propose CoralStyleCLIP, which incorporates a multi-layer attention-guided blending strategy in the feature space of StyleGAN2 for obtaining high-fidelity edits. We propose multiple forms of our co-optimized region and layer selection strategy to demonstrate the variation of time complexity with the quality of edits over different architectural intricacies while preserving simplicity. We conduct extensive experimental analysis and benchmark our method against state-of-the-art CLIP-based methods. Our findings suggest that CoralStyleCLIP results in high-quality edits while preserving the ease of use.
Directional GAN: A Novel Conditioning Strategy for Generative Networks
May 13, 2021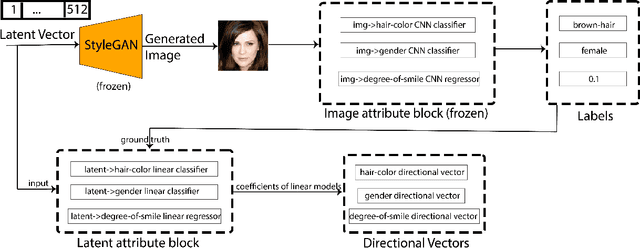

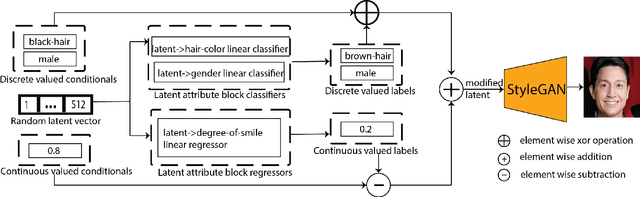
Image content is a predominant factor in marketing campaigns, websites and banners. Today, marketers and designers spend considerable time and money in generating such professional quality content. We take a step towards simplifying this process using Generative Adversarial Networks (GANs). We propose a simple and novel conditioning strategy which allows generation of images conditioned on given semantic attributes using a generator trained for an unconditional image generation task. Our approach is based on modifying latent vectors, using directional vectors of relevant semantic attributes in latent space. Our method is designed to work with both discrete (binary and multi-class) and continuous image attributes. We show the applicability of our proposed approach, named Directional GAN, on multiple public datasets, with an average accuracy of 86.4% across different attributes.