 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenVideo: One-shot Target-image and Shape Aware Video Editing using T2I Diffusion Models
Apr 18, 2024



Video editing methods based on diffusion models that rely solely on a text prompt for the edit are hindered by the limited expressive power of text prompts. Thus, incorporating a reference target image as a visual guide becomes desirable for precise control over edit. Also, most existing methods struggle to accurately edit a video when the shape and size of the object in the target image differ from the source object. To address these challenges, we propose "GenVideo" for editing videos leveraging target-image aware T2I models. Our approach handles edits with target objects of varying shapes and sizes while maintaining the temporal consistency of the edit using our novel target and shape aware InvEdit masks. Further, we propose a novel target-image aware latent noise correction strategy during inference to improve the temporal consistency of the edits. Experimental analyses indicate that GenVideo can effectively handle edits with objects of varying shapes, where existing approaches fail.
CoralStyleCLIP: Co-optimized Region and Layer Selection for Image Editing
Mar 09, 2023



Edit fidelity is a significant issue in open-world controllable generative image editing. Recently, CLIP-based approaches have traded off simplicity to alleviate these problems by introducing spatial attention in a handpicked layer of a StyleGAN. In this paper, we propose CoralStyleCLIP, which incorporates a multi-layer attention-guided blending strategy in the feature space of StyleGAN2 for obtaining high-fidelity edits. We propose multiple forms of our co-optimized region and layer selection strategy to demonstrate the variation of time complexity with the quality of edits over different architectural intricacies while preserving simplicity. We conduct extensive experimental analysis and benchmark our method against state-of-the-art CLIP-based methods. Our findings suggest that CoralStyleCLIP results in high-quality edits while preserving the ease of use.
Instantaneous Physiological Estimation using Video Transformers
Feb 24, 2022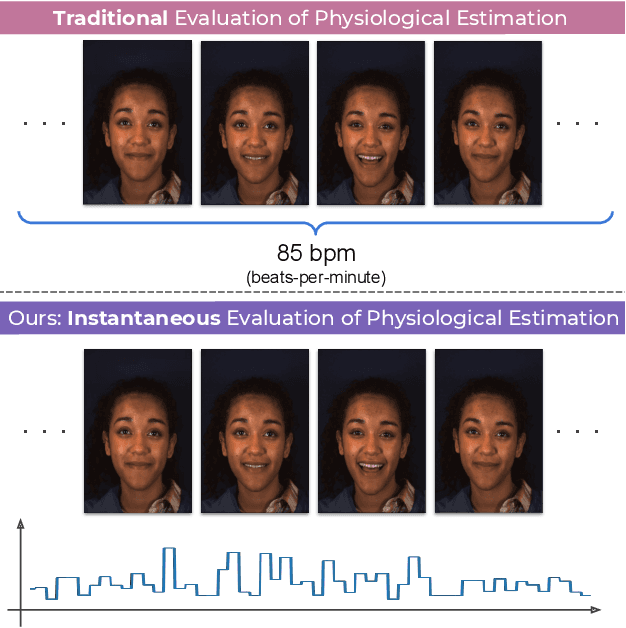
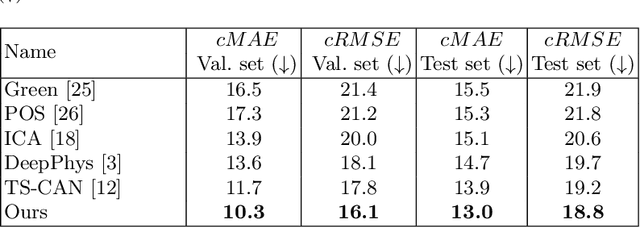
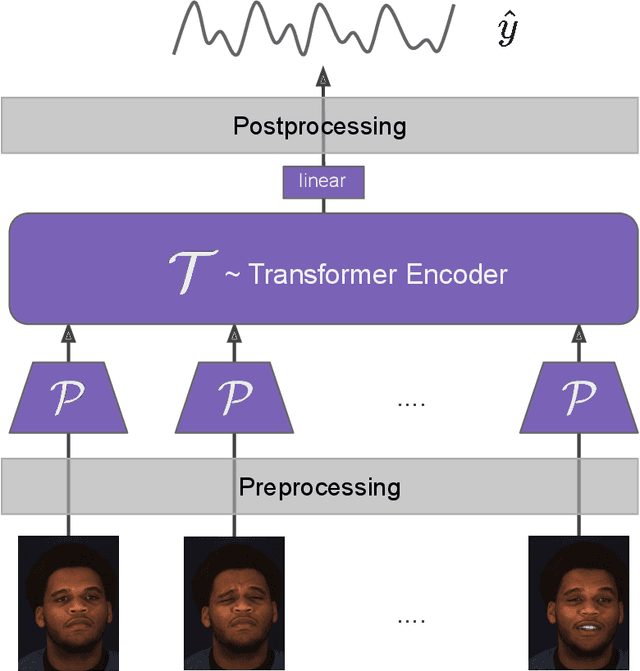
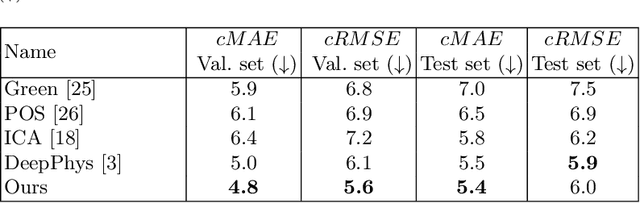
Video-based physiological signal estimation has been limited primarily to predicting episodic scores in windowed intervals. While these intermittent values are useful, they provide an incomplete picture of patients' physiological status and may lead to late detection of critical conditions. We propose a video Transformer for estimating instantaneous heart rate and respiration rate from face videos. Physiological signals are typically confounded by alignment errors in space and time. To overcome this, we formulated the loss in the frequency domain. We evaluated the method on the large scale Vision-for-Vitals (V4V) benchmark. It outperformed both shallow and deep learning based methods for instantaneous respiration rate estimation. In the case of heart-rate estimation, it achieved an instantaneous-MAE of 13.0 beats-per-minute.
The First Vision For Vitals Challenge for Non-Contact Video-Based Physiological Estimation
Sep 22, 2021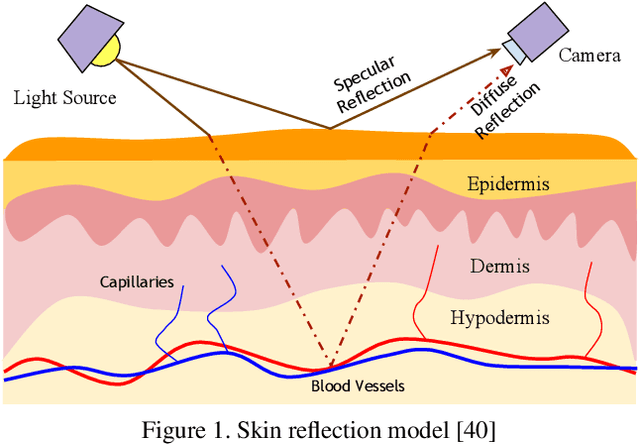
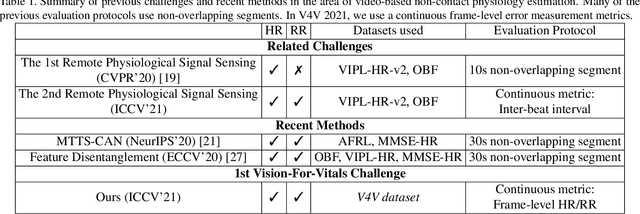
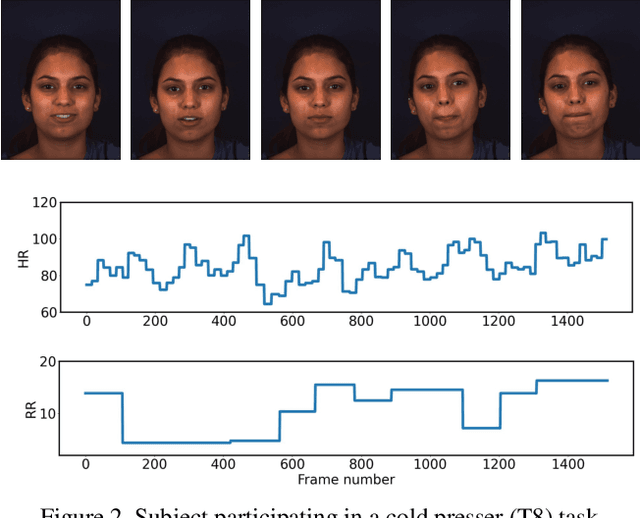
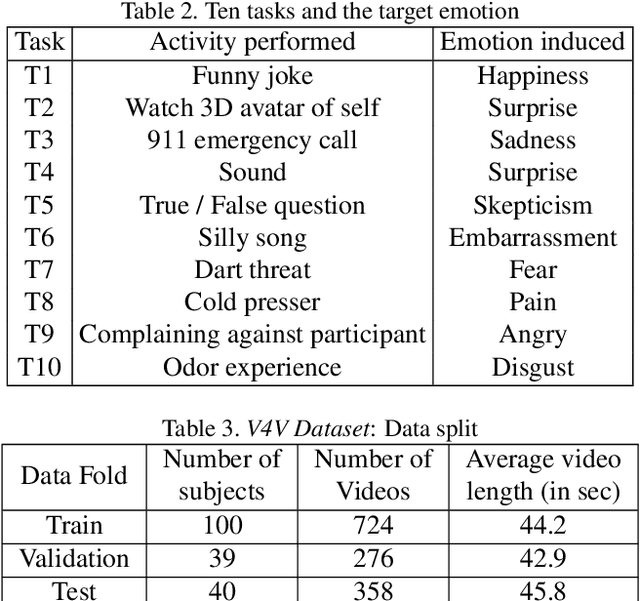
Telehealth has the potential to offset the high demand for help during public health emergencies, such as the COVID-19 pandemic. Remote Photoplethysmography (rPPG) - the problem of non-invasively estimating blood volume variations in the microvascular tissue from video - would be well suited for these situations. Over the past few years a number of research groups have made rapid advances in remote PPG methods for estimating heart rate from digital video and obtained impressive results. How these various methods compare in naturalistic conditions, where spontaneous behavior, facial expressions, and illumination changes are present, is relatively unknown. To enable comparisons among alternative methods, the 1st Vision for Vitals Challenge (V4V) presented a novel dataset containing high-resolution videos time-locked with varied physiological signals from a diverse population. In this paper, we outline the evaluation protocol, the data used, and the results. V4V is to be held in conjunction with the 2021 International Conference on Computer Vision.
Semi-Supervised Visual Representation Learning for Fashion Compatibility
Sep 16, 2021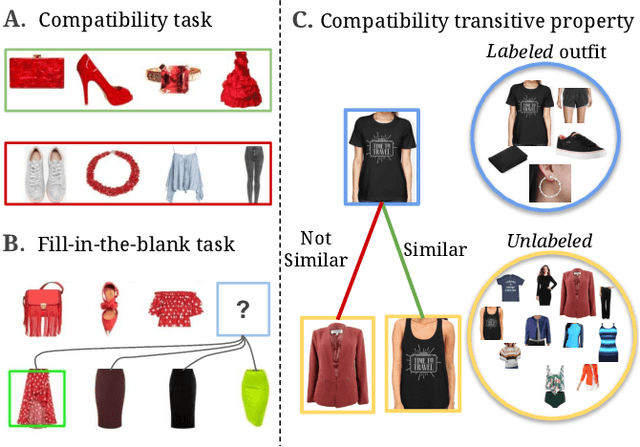

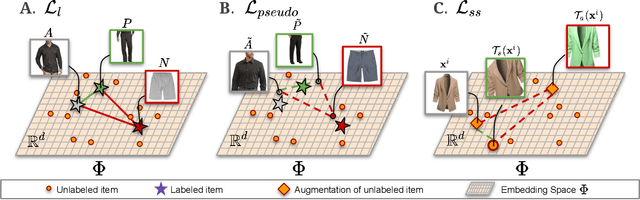
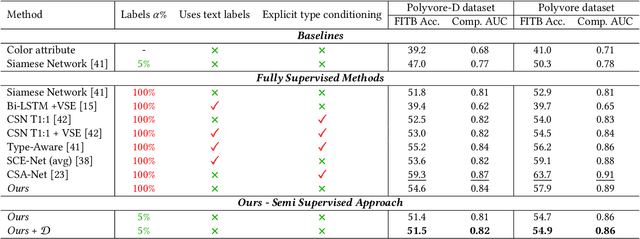
We consider the problem of complementary fashion prediction. Existing approaches focus on learning an embedding space where fashion items from different categories that are visually compatible are closer to each other. However, creating such labeled outfits is intensive and also not feasible to generate all possible outfit combinations, especially with large fashion catalogs. In this work, we propose a semi-supervised learning approach where we leverage large unlabeled fashion corpus to create pseudo-positive and pseudo-negative outfits on the fly during training. For each labeled outfit in a training batch, we obtain a pseudo-outfit by matching each item in the labeled outfit with unlabeled items. Additionally, we introduce consistency regularization to ensure that representation of the original images and their transformations are consistent to implicitly incorporate colour and other important attributes through self-supervision. We conduct extensive experiments on Polyvore, Polyvore-D and our newly created large-scale Fashion Outfits datasets, and show that our approach with only a fraction of labeled examples performs on-par with completely supervised methods.
Your Classifier can Secretly Suffice Multi-Source Domain Adaptation
Mar 20, 2021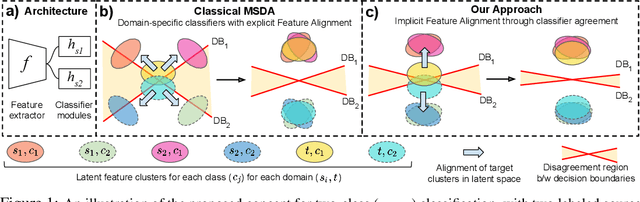
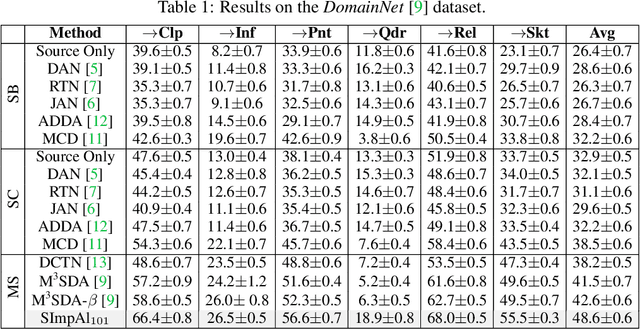
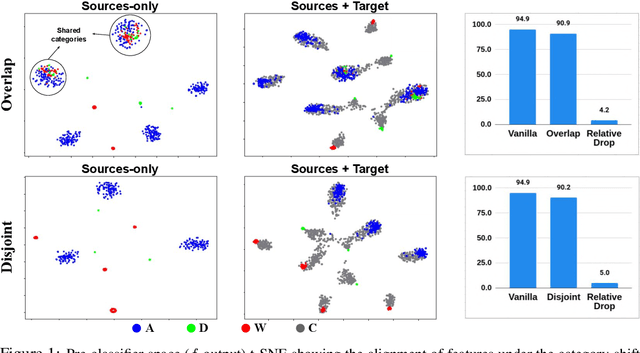
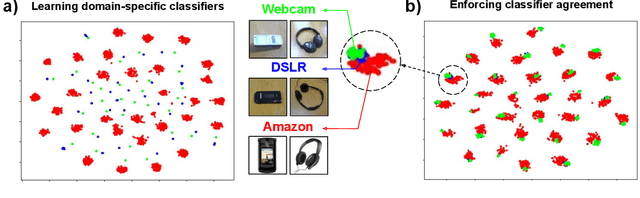
Multi-Source Domain Adaptation (MSDA) deals with the transfer of task knowledge from multiple labeled source domains to an unlabeled target domain, under a domain-shift. Existing methods aim to minimize this domain-shift using auxiliary distribution alignment objectives. In this work, we present a different perspective to MSDA wherein deep models are observed to implicitly align the domains under label supervision. Thus, we aim to utilize implicit alignment without additional training objectives to perform adaptation. To this end, we use pseudo-labeled target samples and enforce a classifier agreement on the pseudo-labels, a process called Self-supervised Implicit Alignment (SImpAl). We find that SImpAl readily works even under category-shift among the source domains. Further, we propose classifier agreement as a cue to determine the training convergence, resulting in a simple training algorithm. We provide a thorough evaluation of our approach on five benchmarks, along with detailed insights into each component of our approach.
Class-Incremental Domain Adaptation
Aug 04, 2020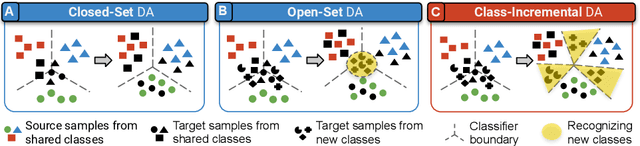
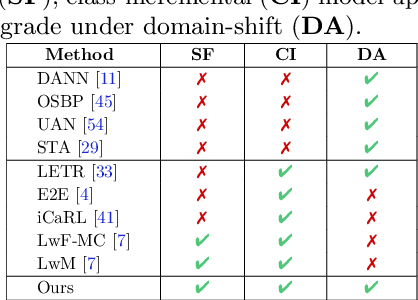
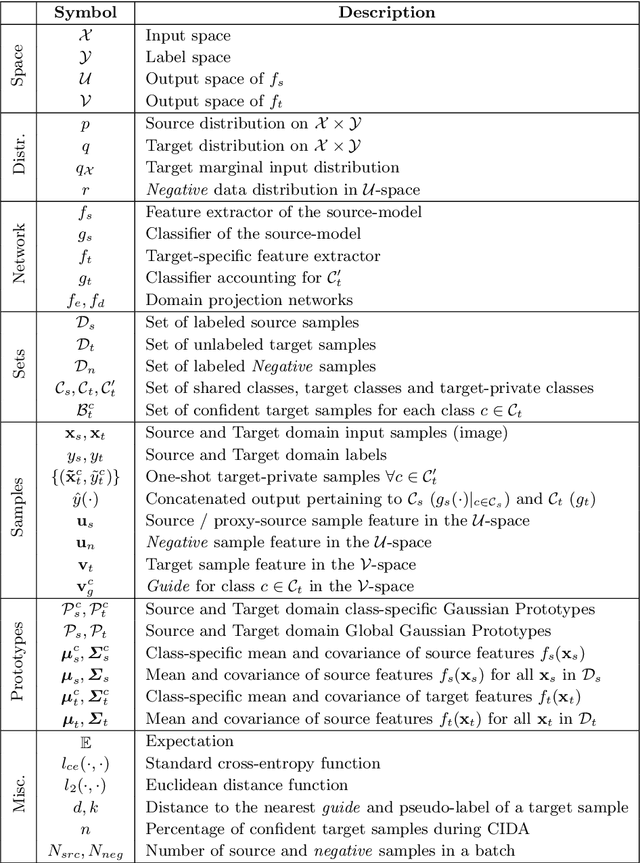

We introduce a practical Domain Adaptation (DA) paradigm called Class-Incremental Domain Adaptation (CIDA). Existing DA methods tackle domain-shift but are unsuitable for learning novel target-domain classes. Meanwhile, class-incremental (CI) methods enable learning of new classes in absence of source training data but fail under a domain-shift without labeled supervision. In this work, we effectively identify the limitations of these approaches in the CIDA paradigm. Motivated by theoretical and empirical observations, we propose an effective method, inspired by prototypical networks, that enables classification of target samples into both shared and novel (one-shot) target classes, even under a domain-shift. Our approach yields superior performance as compared to both DA and CI methods in the CIDA paradigm.
Unsupervised Cross-Modal Alignment for Multi-Person 3D Pose Estimation
Aug 04, 2020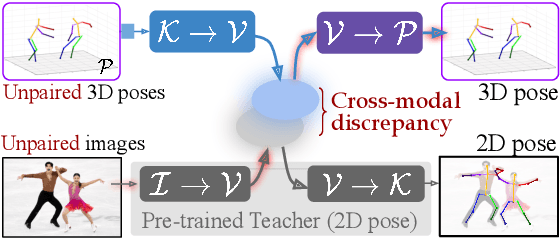

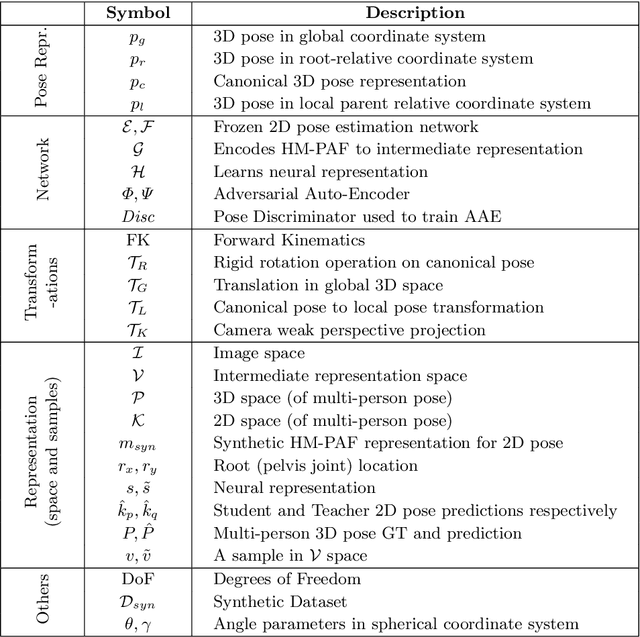
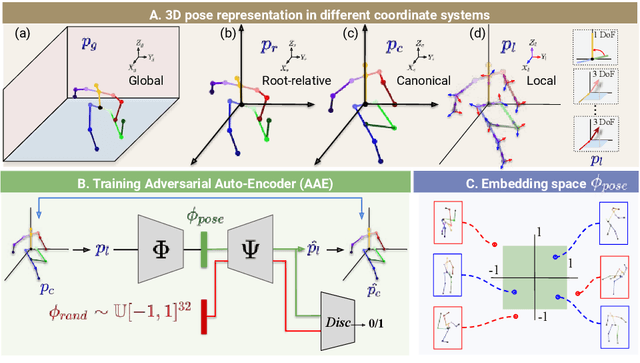
We present a deployment friendly, fast bottom-up framework for multi-person 3D human pose estimation. We adopt a novel neural representation of multi-person 3D pose which unifies the position of person instances with their corresponding 3D pose representation. This is realized by learning a generative pose embedding which not only ensures plausible 3D pose predictions, but also eliminates the usual keypoint grouping operation as employed in prior bottom-up approaches. Further, we propose a practical deployment paradigm where paired 2D or 3D pose annotations are unavailable. In the absence of any paired supervision, we leverage a frozen network, as a teacher model, which is trained on an auxiliary task of multi-person 2D pose estimation. We cast the learning as a cross-modal alignment problem and propose training objectives to realize a shared latent space between two diverse modalities. We aim to enhance the model's ability to perform beyond the limiting teacher network by enriching the latent-to-3D pose mapping using artificially synthesized multi-person 3D scene samples. Our approach not only generalizes to in-the-wild images, but also yields a superior trade-off between speed and performance, compared to prior top-down approaches. Our approach also yields state-of-the-art multi-person 3D pose estimation performance among the bottom-up approaches under consistent supervision levels.
Towards Inheritable Models for Open-Set Domain Adaptation
Apr 09, 2020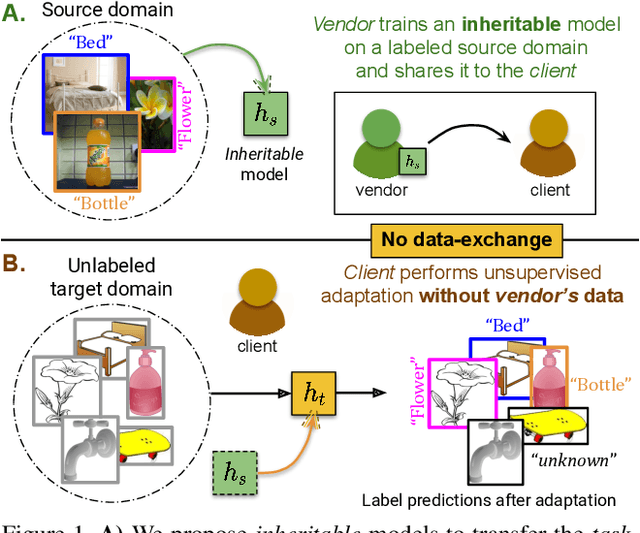
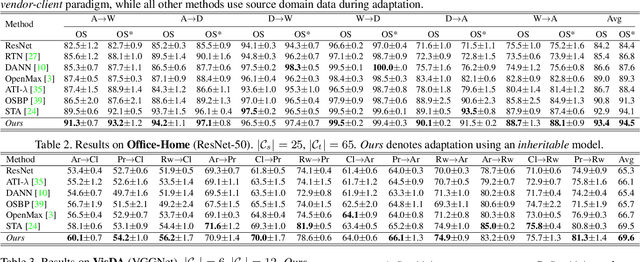


There has been a tremendous progress in Domain Adaptation (DA) for visual recognition tasks. Particularly, open-set DA has gained considerable attention wherein the target domain contains additional unseen categories. Existing open-set DA approaches demand access to a labeled source dataset along with unlabeled target instances. However, this reliance on co-existing source and target data is highly impractical in scenarios where data-sharing is restricted due to its proprietary nature or privacy concerns. Addressing this, we introduce a practical DA paradigm where a source-trained model is used to facilitate adaptation in the absence of the source dataset in future. To this end, we formalize knowledge inheritability as a novel concept and propose a simple yet effective solution to realize inheritable models suitable for the above practical paradigm. Further, we present an objective way to quantify inheritability to enable the selection of the most suitable source model for a given target domain, even in the absence of the source data. We provide theoretical insights followed by a thorough empirical evaluation demonstrating state-of-the-art open-set domain adaptation performance.