 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMy Face My Choice: Privacy Enhancing Deepfakes for Social Media Anonymization
Nov 02, 2022Recently, productization of face recognition and identification algorithms have become the most controversial topic about ethical AI. As new policies around digital identities are formed, we introduce three face access models in a hypothetical social network, where the user has the power to only appear in photos they approve. Our approach eclipses current tagging systems and replaces unapproved faces with quantitatively dissimilar deepfakes. In addition, we propose new metrics specific for this task, where the deepfake is generated at random with a guaranteed dissimilarity. We explain access models based on strictness of the data flow, and discuss impact of each model on privacy, usability, and performance. We evaluate our system on Facial Descriptor Dataset as the real dataset, and two synthetic datasets with random and equal class distributions. Running seven SOTA face recognizers on our results, MFMC reduces the average accuracy by 61%. Lastly, we extensively analyze similarity metrics, deepfake generators, and datasets in structural, visual, and generative spaces; supporting the design choices and verifying the quality.
MixSyn: Learning Composition and Style for Multi-Source Image Synthesis
Nov 24, 2021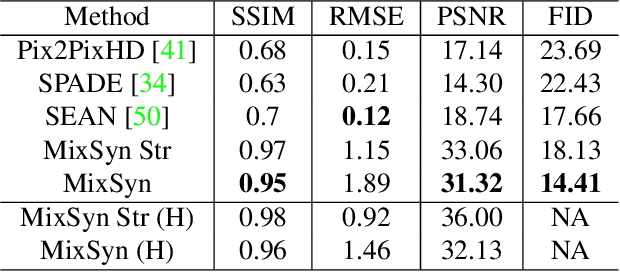
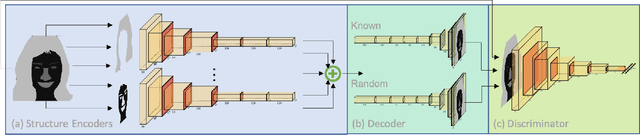
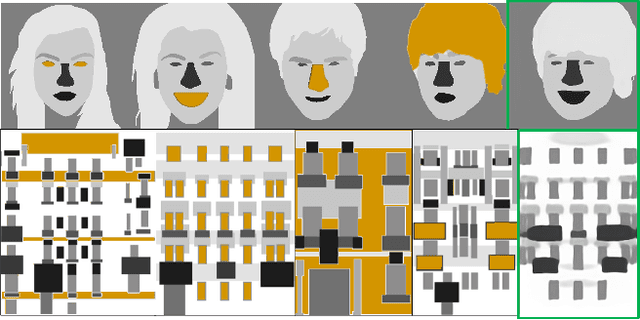
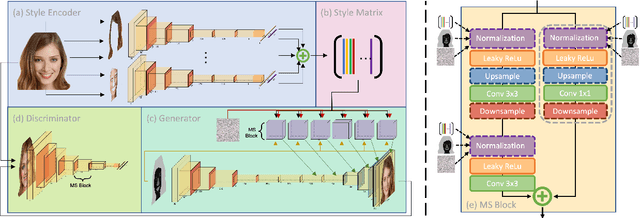
Synthetic images created by generative models increase in quality and expressiveness as newer models utilize larger datasets and novel architectures. Although this photorealism is a positive side-effect from a creative standpoint, it becomes problematic when such generative models are used for impersonation without consent. Most of these approaches are built on the partial transfer between source and target pairs, or they generate completely new samples based on an ideal distribution, still resembling the closest real sample in the dataset. We propose MixSyn (read as " mixin' ") for learning novel fuzzy compositions from multiple sources and creating novel images as a mix of image regions corresponding to the compositions. MixSyn not only combines uncorrelated regions from multiple source masks into a coherent semantic composition, but also generates mask-aware high quality reconstructions of non-existing images. We compare MixSyn to state-of-the-art single-source sequential generation and collage generation approaches in terms of quality, diversity, realism, and expressive power; while also showcasing interactive synthesis, mix & match, and edit propagation tasks, with no mask dependency.
The First Vision For Vitals Challenge for Non-Contact Video-Based Physiological Estimation
Sep 22, 2021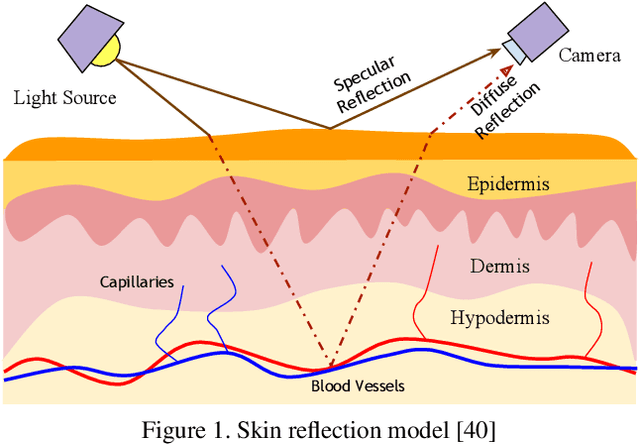
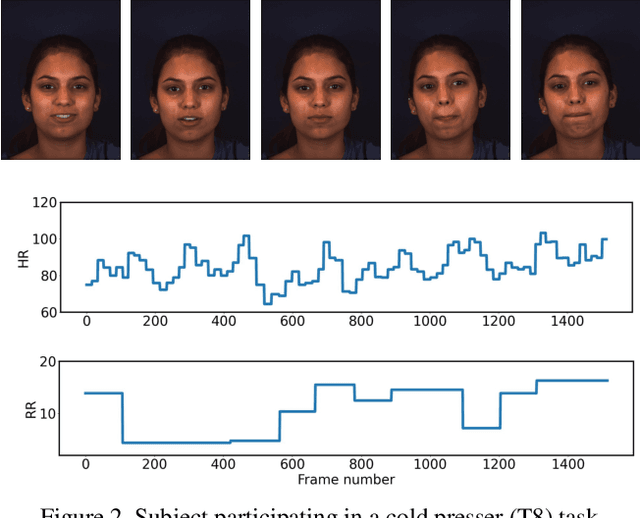
Telehealth has the potential to offset the high demand for help during public health emergencies, such as the COVID-19 pandemic. Remote Photoplethysmography (rPPG) - the problem of non-invasively estimating blood volume variations in the microvascular tissue from video - would be well suited for these situations. Over the past few years a number of research groups have made rapid advances in remote PPG methods for estimating heart rate from digital video and obtained impressive results. How these various methods compare in naturalistic conditions, where spontaneous behavior, facial expressions, and illumination changes are present, is relatively unknown. To enable comparisons among alternative methods, the 1st Vision for Vitals Challenge (V4V) presented a novel dataset containing high-resolution videos time-locked with varied physiological signals from a diverse population. In this paper, we outline the evaluation protocol, the data used, and the results. V4V is to be held in conjunction with the 2021 International Conference on Computer Vision.
Where Do Deep Fakes Look? Synthetic Face Detection via Gaze Tracking
Jan 04, 2021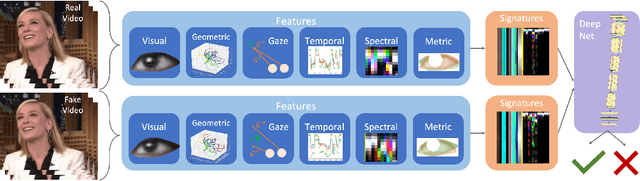

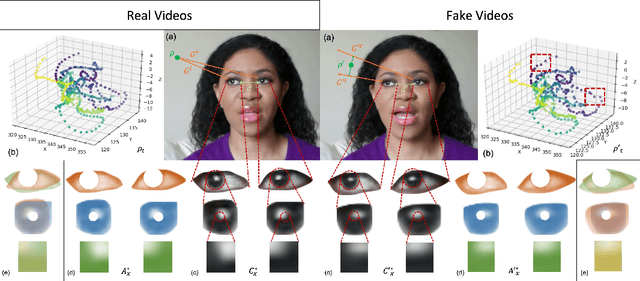

Following the recent initiatives for the democratization of AI, deep fake generators have become increasingly popular and accessible, causing dystopian scenarios towards social erosion of trust. A particular domain, such as biological signals, attracted attention towards detection methods that are capable of exploiting authenticity signatures in real videos that are not yet faked by generative approaches. In this paper, we first propose several prominent eye and gaze features that deep fakes exhibit differently. Second, we compile those features into signatures and analyze and compare those of real and fake videos, formulating geometric, visual, metric, temporal, and spectral variations. Third, we generalize this formulation to deep fake detection problem by a deep neural network, to classify any video in the wild as fake or real. We evaluate our approach on several deep fake datasets, achieving 89.79\% accuracy on FaceForensics++, 80.0\% on Deep Fakes (in the wild), and 88.35\% on CelebDF datasets. We conduct ablation studies involving different features, architectures, sequence durations, and post-processing artifacts. Our analysis concludes with 6.29\% improved accuracy over complex network architectures without the proposed gaze signatures.