 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMy Body My Choice: Human-Centric Full-Body Anonymization
Jun 13, 2024In an era of increasing privacy concerns for our online presence, we propose that the decision to appear in a piece of content should only belong to the owner of the body. Although some automatic approaches for full-body anonymization have been proposed, human-guided anonymization can adapt to various contexts, such as cultural norms, personal relations, esthetic concerns, and security issues. ''My Body My Choice'' (MBMC) enables physical and adversarial anonymization by removal and swapping approaches aimed for four tasks, designed by single or multi, ControlNet or GAN modules, combining several diffusion models. We evaluate anonymization on seven datasets; compare with SOTA inpainting and anonymization methods; evaluate by image, adversarial, and generative metrics; and conduct reidentification experiments.
My Art My Choice: Adversarial Protection Against Unruly AI
Sep 06, 2023Generative AI is on the rise, enabling everyone to produce realistic content via publicly available interfaces. Especially for guided image generation, diffusion models are changing the creator economy by producing high quality low cost content. In parallel, artists are rising against unruly AI, since their artwork are leveraged, distributed, and dissimulated by large generative models. Our approach, My Art My Choice (MAMC), aims to empower content owners by protecting their copyrighted materials from being utilized by diffusion models in an adversarial fashion. MAMC learns to generate adversarially perturbed "protected" versions of images which can in turn "break" diffusion models. The perturbation amount is decided by the artist to balance distortion vs. protection of the content. MAMC is designed with a simple UNet-based generator, attacking black box diffusion models, combining several losses to create adversarial twins of the original artwork. We experiment on three datasets for various image-to-image tasks, with different user control values. Both protected image and diffusion output results are evaluated in visual, noise, structure, pixel, and generative spaces to validate our claims. We believe that MAMC is a crucial step for preserving ownership information for AI generated content in a flawless, based-on-need, and human-centric way.
How Do Deepfakes Move? Motion Magnification for Deepfake Source Detection
Dec 28, 2022



With the proliferation of deep generative models, deepfakes are improving in quality and quantity everyday. However, there are subtle authenticity signals in pristine videos, not replicated by SOTA GANs. We contrast the movement in deepfakes and authentic videos by motion magnification towards building a generalized deepfake source detector. The sub-muscular motion in faces has different interpretations per different generative models which is reflected in their generative residue. Our approach exploits the difference between real motion and the amplified GAN fingerprints, by combining deep and traditional motion magnification, to detect whether a video is fake and its source generator if so. Evaluating our approach on two multi-source datasets, we obtain 97.17% and 94.03% for video source detection. We compare against the prior deepfake source detector and other complex architectures. We also analyze the importance of magnification amount, phase extraction window, backbone network architecture, sample counts, and sample lengths. Finally, we report our results for different skin tones to assess the bias.
My Face My Choice: Privacy Enhancing Deepfakes for Social Media Anonymization
Nov 02, 2022Recently, productization of face recognition and identification algorithms have become the most controversial topic about ethical AI. As new policies around digital identities are formed, we introduce three face access models in a hypothetical social network, where the user has the power to only appear in photos they approve. Our approach eclipses current tagging systems and replaces unapproved faces with quantitatively dissimilar deepfakes. In addition, we propose new metrics specific for this task, where the deepfake is generated at random with a guaranteed dissimilarity. We explain access models based on strictness of the data flow, and discuss impact of each model on privacy, usability, and performance. We evaluate our system on Facial Descriptor Dataset as the real dataset, and two synthetic datasets with random and equal class distributions. Running seven SOTA face recognizers on our results, MFMC reduces the average accuracy by 61%. Lastly, we extensively analyze similarity metrics, deepfake generators, and datasets in structural, visual, and generative spaces; supporting the design choices and verifying the quality.
MixSyn: Learning Composition and Style for Multi-Source Image Synthesis
Nov 24, 2021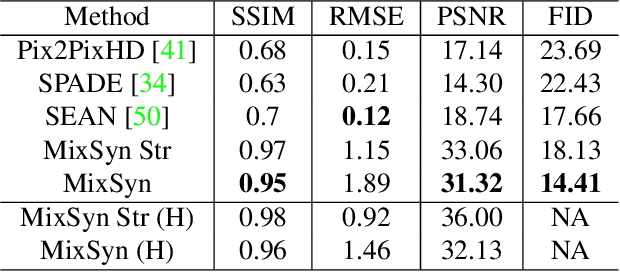
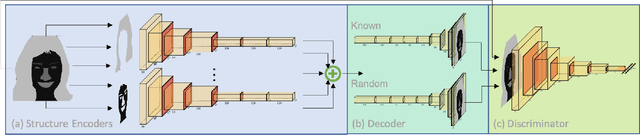
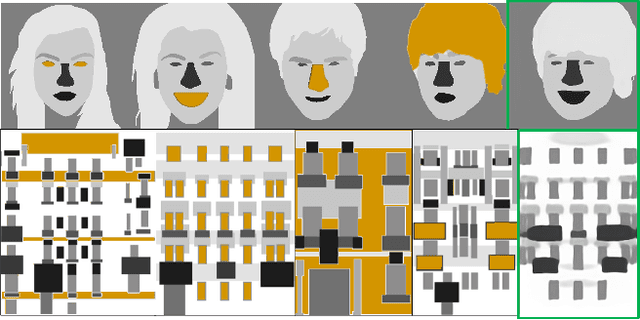
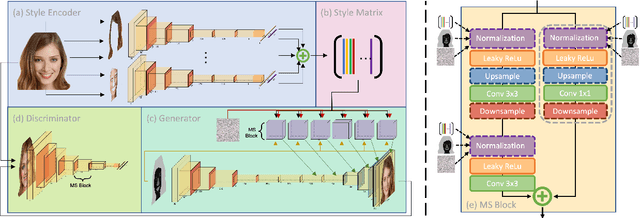
Synthetic images created by generative models increase in quality and expressiveness as newer models utilize larger datasets and novel architectures. Although this photorealism is a positive side-effect from a creative standpoint, it becomes problematic when such generative models are used for impersonation without consent. Most of these approaches are built on the partial transfer between source and target pairs, or they generate completely new samples based on an ideal distribution, still resembling the closest real sample in the dataset. We propose MixSyn (read as " mixin' ") for learning novel fuzzy compositions from multiple sources and creating novel images as a mix of image regions corresponding to the compositions. MixSyn not only combines uncorrelated regions from multiple source masks into a coherent semantic composition, but also generates mask-aware high quality reconstructions of non-existing images. We compare MixSyn to state-of-the-art single-source sequential generation and collage generation approaches in terms of quality, diversity, realism, and expressive power; while also showcasing interactive synthesis, mix & match, and edit propagation tasks, with no mask dependency.
Where Do Deep Fakes Look? Synthetic Face Detection via Gaze Tracking
Jan 04, 2021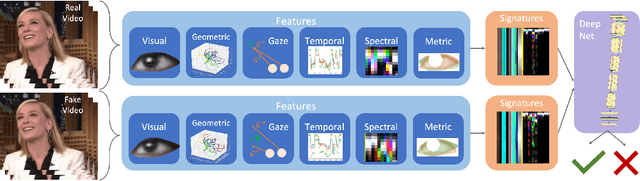


Following the recent initiatives for the democratization of AI, deep fake generators have become increasingly popular and accessible, causing dystopian scenarios towards social erosion of trust. A particular domain, such as biological signals, attracted attention towards detection methods that are capable of exploiting authenticity signatures in real videos that are not yet faked by generative approaches. In this paper, we first propose several prominent eye and gaze features that deep fakes exhibit differently. Second, we compile those features into signatures and analyze and compare those of real and fake videos, formulating geometric, visual, metric, temporal, and spectral variations. Third, we generalize this formulation to deep fake detection problem by a deep neural network, to classify any video in the wild as fake or real. We evaluate our approach on several deep fake datasets, achieving 89.79\% accuracy on FaceForensics++, 80.0\% on Deep Fakes (in the wild), and 88.35\% on CelebDF datasets. We conduct ablation studies involving different features, architectures, sequence durations, and post-processing artifacts. Our analysis concludes with 6.29\% improved accuracy over complex network architectures without the proposed gaze signatures.
How Do the Hearts of Deep Fakes Beat? Deep Fake Source Detection via Interpreting Residuals with Biological Signals
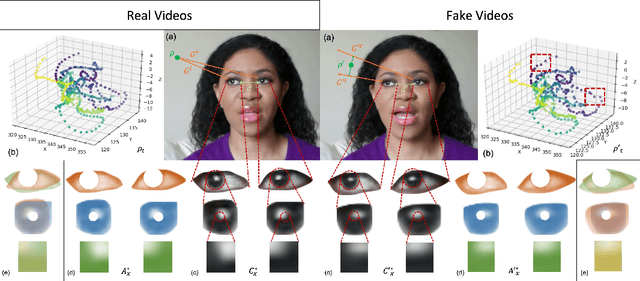
Aug 26, 2020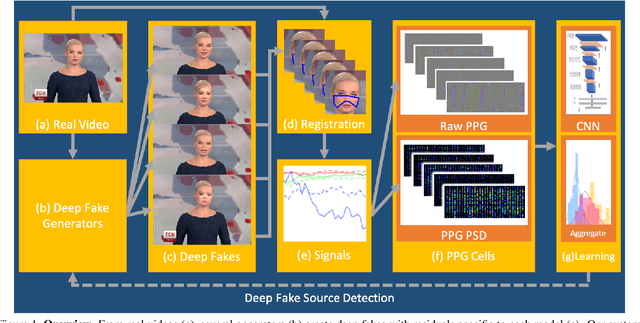



Fake portrait video generation techniques have been posing a new threat to the society with photorealistic deep fakes for political propaganda, celebrity imitation, forged evidences, and other identity related manipulations. Following these generation techniques, some detection approaches have also been proved useful due to their high classification accuracy. Nevertheless, almost no effort was spent to track down the source of deep fakes. We propose an approach not only to separate deep fakes from real videos, but also to discover the specific generative model behind a deep fake. Some pure deep learning based approaches try to classify deep fakes using CNNs where they actually learn the residuals of the generator. We believe that these residuals contain more information and we can reveal these manipulation artifacts by disentangling them with biological signals. Our key observation yields that the spatiotemporal patterns in biological signals can be conceived as a representative projection of residuals. To justify this observation, we extract PPG cells from real and fake videos and feed these to a state-of-the-art classification network for detecting the generative model per video. Our results indicate that our approach can detect fake videos with 97.29% accuracy, and the source model with 93.39% accuracy.
SkelNetOn 2019 Dataset and Challenge on Deep Learning for Geometric Shape Understanding
Mar 21, 2019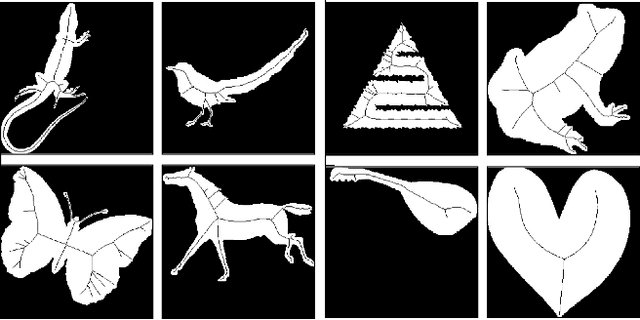
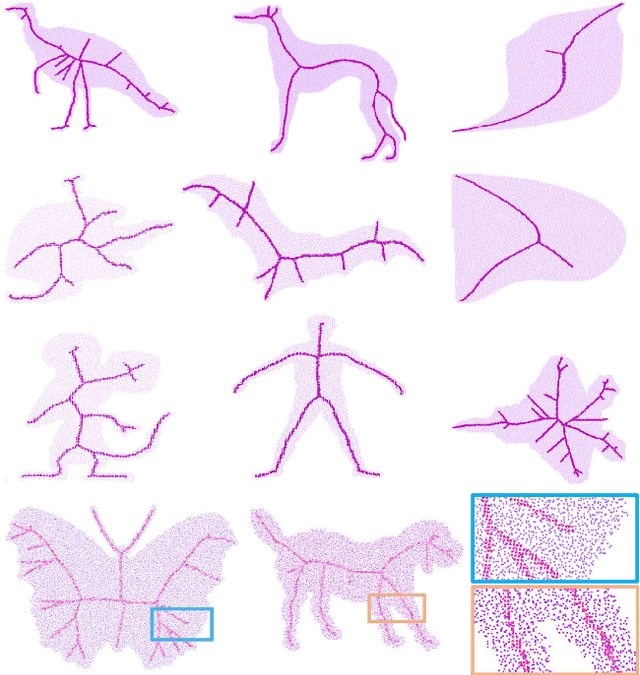
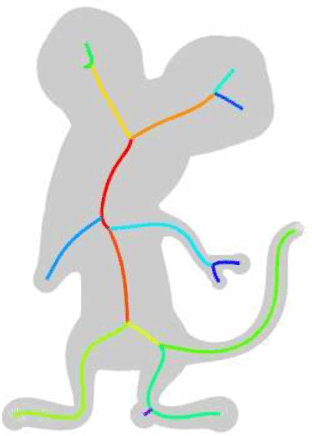

We present SkelNetOn 2019 Challenge and Deep Learning for Geometric Shape Understanding workshop to utilize existing and develop novel deep learning architectures for shape understanding. We observed that unlike traditional segmentation and detection tasks, geometry understanding is still a new area for investigation using deep learning techniques. SkelNetOn aims to bring together researchers from different domains to foster learning methods on global shape understanding tasks. We aim to improve and evaluate the state-of-the-art shape understanding approaches, and to serve as reference benchmarks for future research. Similar to other challenges in computer vision domain, SkelNetOn tracks propose three datasets and corresponding evaluation methodologies; all coherently bundled in three competitions with a dedicated workshop co-located with CVPR 2019 conference. In this paper, we describe and analyze characteristics of each dataset, define the evaluation criteria of the public competitions, and provide baselines for each task.
FakeCatcher: Detection of Synthetic Portrait Videos using Biological Signals
Jan 08, 2019
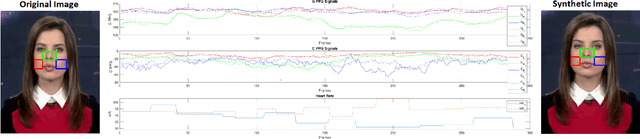
As we enter into the AI era, the proliferation of deep learning approaches, especially generative models, passed beyond research communities as it is being utilized for both good and bad intentions of the society. While generative models get stronger by creating more representative replicas, this strength begins to pose a threat on information integrity. We would like to present an approach to detect synthesized content in the domain of portrait videos, as a preventive solution for this threat. In other words, we would like to build a deep fake detector. Our approach exploits biological signals extracted from facial areas based on the observation that these signals are not well-preserved spatially and temporally in synthetic content. First, we exhibit several unary and binary signal transformations for the pairwise separation problem, achieving 99.39% accuracy to detect fake portrait videos. Second, we use those findings to formulate a generalized classifier of authentic and fake content, by analyzing the characteristics of proposed signal transformations and their corresponding feature sets. We evaluated FakeCatcher both on Face Forensics dataset [46] and on our newly introduced Deep Fakes dataset, performing with 82.55% and 77.33% accuracy respectively. Third, we are also releasing this mixed dataset of synthesized videos that we collected as a part of our evaluation process, containing fake portrait videos "in the wild", independent of a specific generative model, independent of the video compression, and independent of the context. We also analyzed the effects of different facial regions, video segment durations, and dimensionality reduction techniques and compared our detection rate to recent approaches.
Addressing the Invisible: Street Address Generation for Developing Countries with Deep Learning
Nov 10, 2018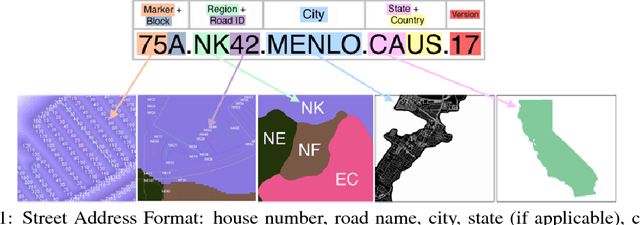
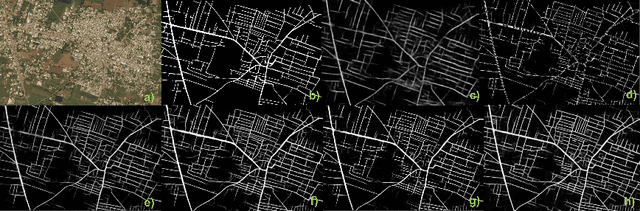


More than half of the world's roads lack adequate street addressing systems. Lack of addresses is even more visible in daily lives of people in developing countries. We would like to object to the assumption that having an address is a luxury, by proposing a generative address design that maps the world in accordance with streets. The addressing scheme is designed considering several traditional street addressing methodologies employed in the urban development scenarios around the world. Our algorithm applies deep learning to extract roads from satellite images, converts the road pixel confidences into a road network, partitions the road network to find neighborhoods, and labels the regions, roads, and address units using graph- and proximity-based algorithms. We present our results on a sample US city, and several developing cities, compare travel times of users using current ad hoc and new complete addresses, and contrast our addressing solution to current industrial and open geocoding alternatives.