 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFakeCatcher: Detection of Synthetic Portrait Videos using Biological Signals
Paper and Code

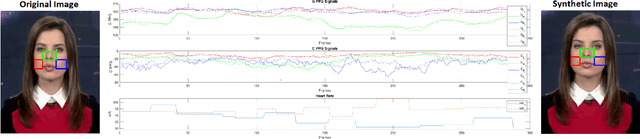
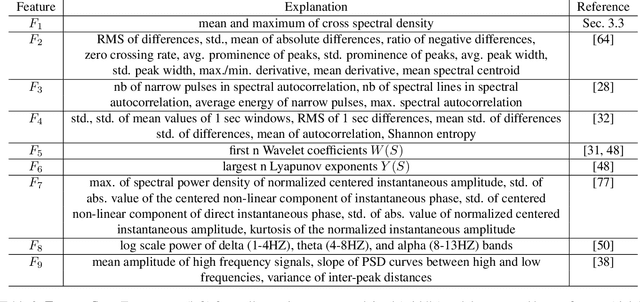
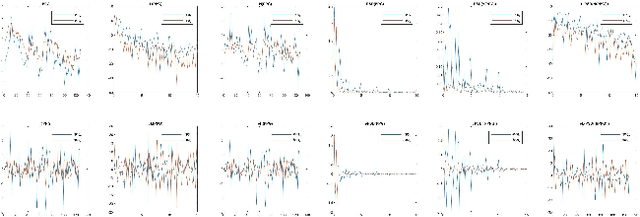
As we enter into the AI era, the proliferation of deep learning approaches, especially generative models, passed beyond research communities as it is being utilized for both good and bad intentions of the society. While generative models get stronger by creating more representative replicas, this strength begins to pose a threat on information integrity. We would like to present an approach to detect synthesized content in the domain of portrait videos, as a preventive solution for this threat. In other words, we would like to build a deep fake detector. Our approach exploits biological signals extracted from facial areas based on the observation that these signals are not well-preserved spatially and temporally in synthetic content. First, we exhibit several unary and binary signal transformations for the pairwise separation problem, achieving 99.39% accuracy to detect fake portrait videos. Second, we use those findings to formulate a generalized classifier of authentic and fake content, by analyzing the characteristics of proposed signal transformations and their corresponding feature sets. We evaluated FakeCatcher both on Face Forensics dataset [46] and on our newly introduced Deep Fakes dataset, performing with 82.55% and 77.33% accuracy respectively. Third, we are also releasing this mixed dataset of synthesized videos that we collected as a part of our evaluation process, containing fake portrait videos "in the wild", independent of a specific generative model, independent of the video compression, and independent of the context. We also analyzed the effects of different facial regions, video segment durations, and dimensionality reduction techniques and compared our detection rate to recent approaches.