 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixSyn: Learning Composition and Style for Multi-Source Image Synthesis
Paper and Code
Nov 24, 2021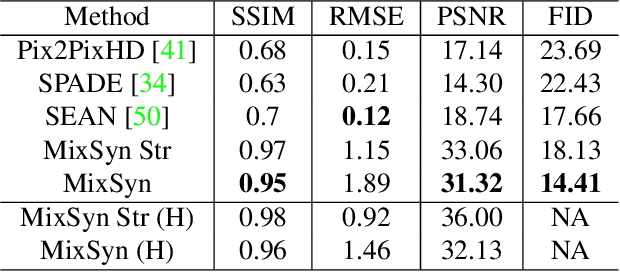
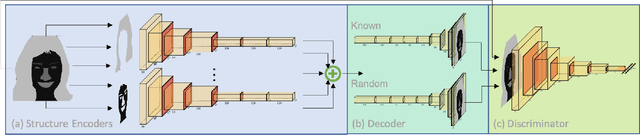
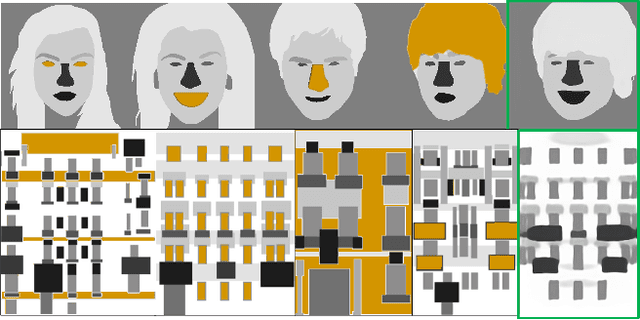
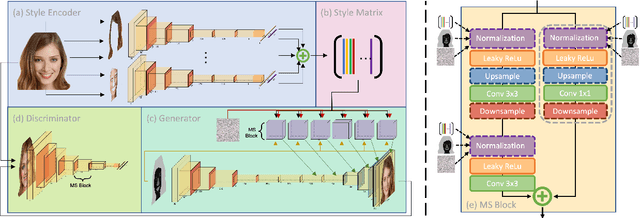
Synthetic images created by generative models increase in quality and expressiveness as newer models utilize larger datasets and novel architectures. Although this photorealism is a positive side-effect from a creative standpoint, it becomes problematic when such generative models are used for impersonation without consent. Most of these approaches are built on the partial transfer between source and target pairs, or they generate completely new samples based on an ideal distribution, still resembling the closest real sample in the dataset. We propose MixSyn (read as " mixin' ") for learning novel fuzzy compositions from multiple sources and creating novel images as a mix of image regions corresponding to the compositions. MixSyn not only combines uncorrelated regions from multiple source masks into a coherent semantic composition, but also generates mask-aware high quality reconstructions of non-existing images. We compare MixSyn to state-of-the-art single-source sequential generation and collage generation approaches in terms of quality, diversity, realism, and expressive power; while also showcasing interactive synthesis, mix & match, and edit propagation tasks, with no mask dependency.