 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWiCV 2019: The Sixth Women In Computer Vision Workshop
Sep 23, 2019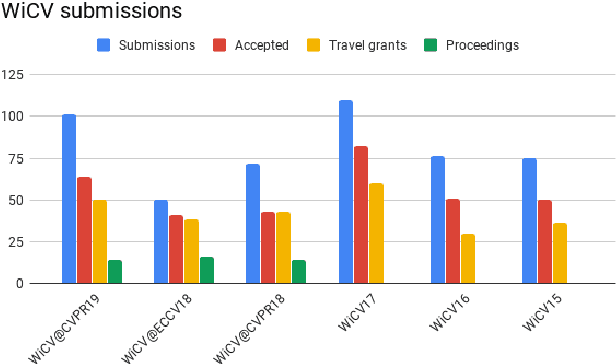
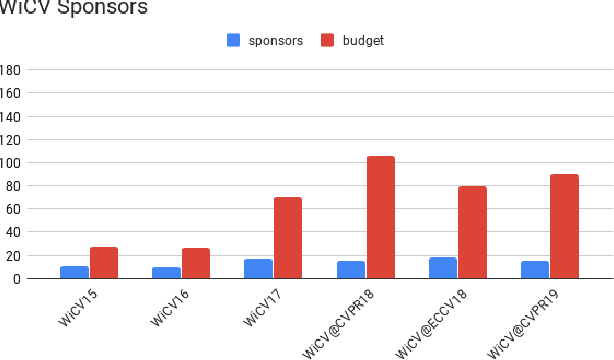
In this paper we present the Women in Computer Vision Workshop - WiCV 2019, organized in conjunction with CVPR 2019. This event is meant for increasing the visibility and inclusion of women researchers in the computer vision field. Computer vision and machine learning have made incredible progress over the past years, but the number of female researchers is still low both in academia and in industry. WiCV is organized especially for the following reason: to raise visibility of female researchers, to increase collaborations between them, and to provide mentorship to female junior researchers in the field. In this paper, we present a report of trends over the past years, along with a summary of statistics regarding presenters, attendees, and sponsorship for the current workshop.
* Report of the Sixth Women In Computer Vision Workshop
3D Organ Shape Reconstruction from Topogram Images
Mar 29, 2019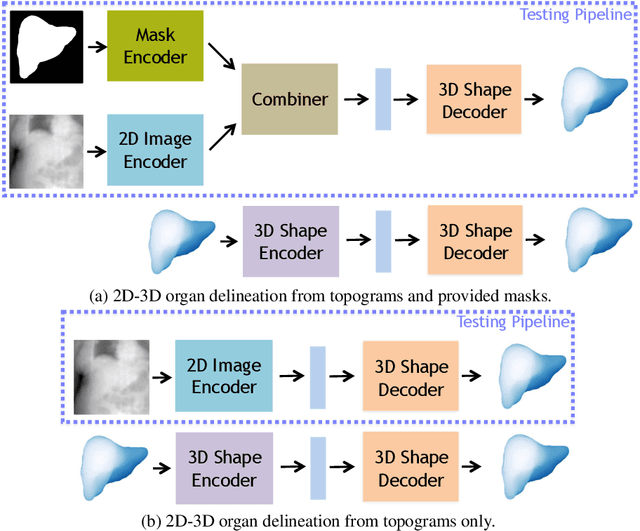

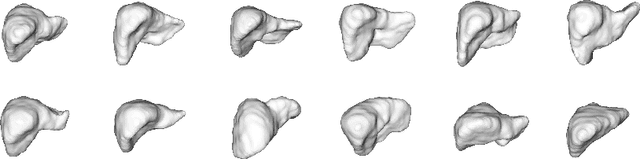

Automatic delineation and measurement of main organs such as liver is one of the critical steps for assessment of hepatic diseases, planning and postoperative or treatment follow-up. However, addressing this problem typically requires performing computed tomography (CT) scanning and complicated postprocessing of the resulting scans using slice-by-slice techniques. In this paper, we show that 3D organ shape can be automatically predicted directly from topogram images, which are easier to acquire and have limited exposure to radiation during acquisition, compared to CT scans. We evaluate our approach on the challenging task of predicting liver shape using a generative model. We also demonstrate that our method can be combined with user annotations, such as a 2D mask, for improved prediction accuracy. We show compelling results on 3D liver shape reconstruction and volume estimation on 2129 CT scans.
SkelNetOn 2019 Dataset and Challenge on Deep Learning for Geometric Shape Understanding
Mar 21, 2019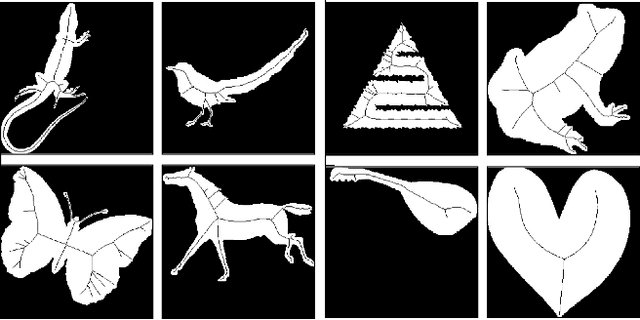
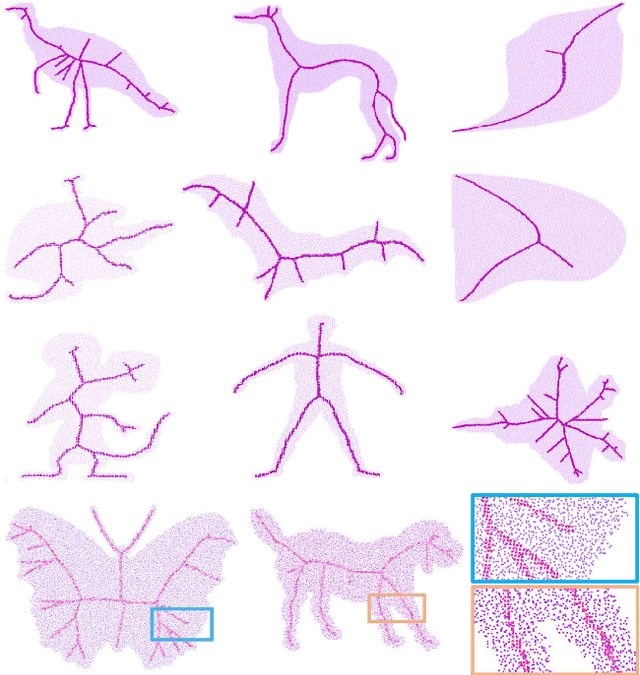
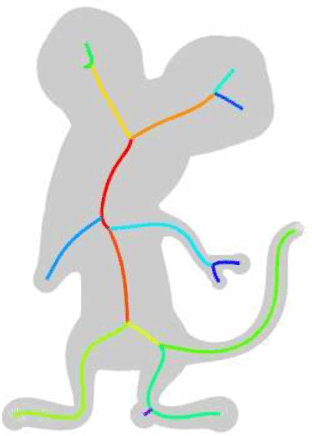

We present SkelNetOn 2019 Challenge and Deep Learning for Geometric Shape Understanding workshop to utilize existing and develop novel deep learning architectures for shape understanding. We observed that unlike traditional segmentation and detection tasks, geometry understanding is still a new area for investigation using deep learning techniques. SkelNetOn aims to bring together researchers from different domains to foster learning methods on global shape understanding tasks. We aim to improve and evaluate the state-of-the-art shape understanding approaches, and to serve as reference benchmarks for future research. Similar to other challenges in computer vision domain, SkelNetOn tracks propose three datasets and corresponding evaluation methodologies; all coherently bundled in three competitions with a dedicated workshop co-located with CVPR 2019 conference. In this paper, we describe and analyze characteristics of each dataset, define the evaluation criteria of the public competitions, and provide baselines for each task.
Structure-Aware Shape Synthesis
Aug 04, 2018

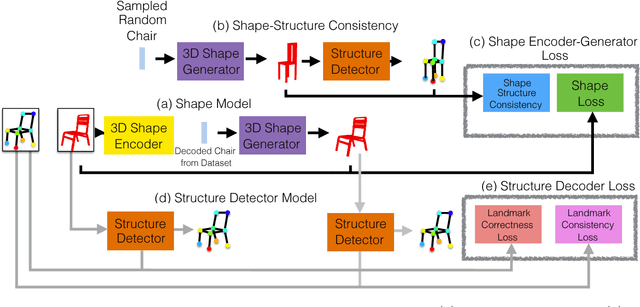
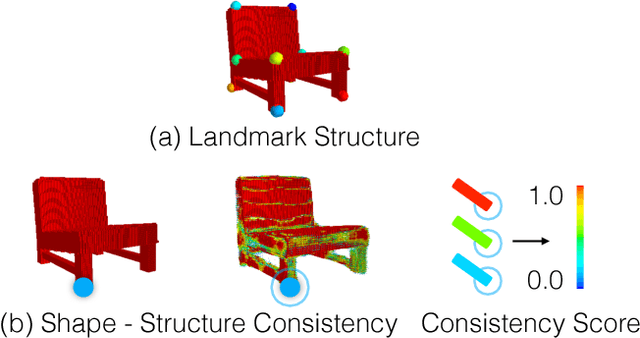
We propose a new procedure to guide training of a data-driven shape generative model using a structure-aware loss function. Complex 3D shapes often can be summarized using a coarsely defined structure which is consistent and robust across variety of observations. However, existing synthesis techniques do not account for structure during training, and thus often generate implausible and structurally unrealistic shapes. During training, we enforce structural constraints in order to enforce consistency and structure across the entire manifold. We propose a novel methodology for training 3D generative models that incorporates structural information into an end-to-end training pipeline.
Generating Synthetic X-ray Images of a Person from the Surface Geometry
May 14, 2018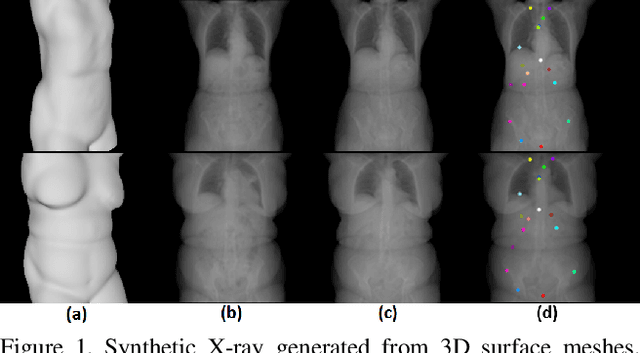
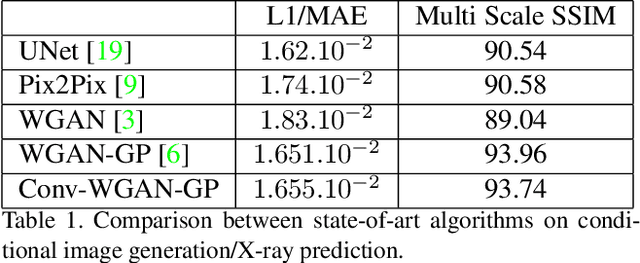
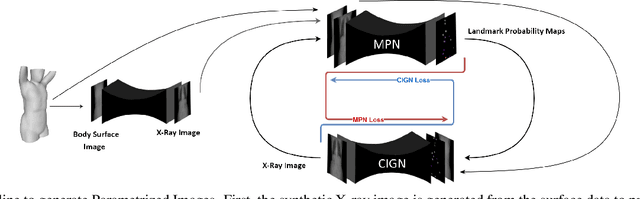
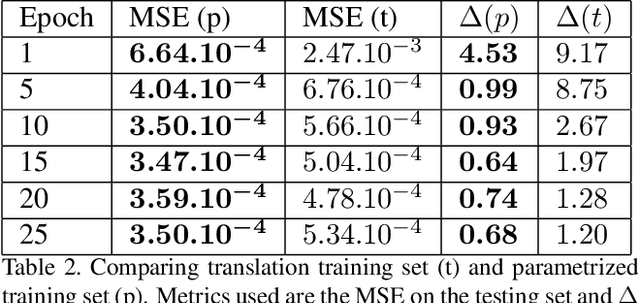
We present a novel framework that learns to predict human anatomy from body surface. Specifically, our approach generates a synthetic X-ray image of a person only from the person's surface geometry. Furthermore, the synthetic X-ray image is parametrized and can be manipulated by adjusting a set of body markers which are also generated during the X-ray image prediction. With the proposed framework, multiple synthetic X-ray images can easily be generated by varying surface geometry. By perturbing the parameters, several additional synthetic X-ray images can be generated from the same surface geometry. As a result, our approach offers a potential to overcome the training data barrier in the medical domain. This capability is achieved by learning a pair of networks - one learns to generate the full image from the partial image and a set of parameters, and the other learns to estimate the parameters given the full image. During training, the two networks are trained iteratively such that they would converge to a solution where the predicted parameters and the full image are consistent with each other. In addition to medical data enrichment, our framework can also be used for image completion as well as anomaly detection.