 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting 2D Foundation Models for Scalable 3D Medical Image Classification
Dec 15, 2025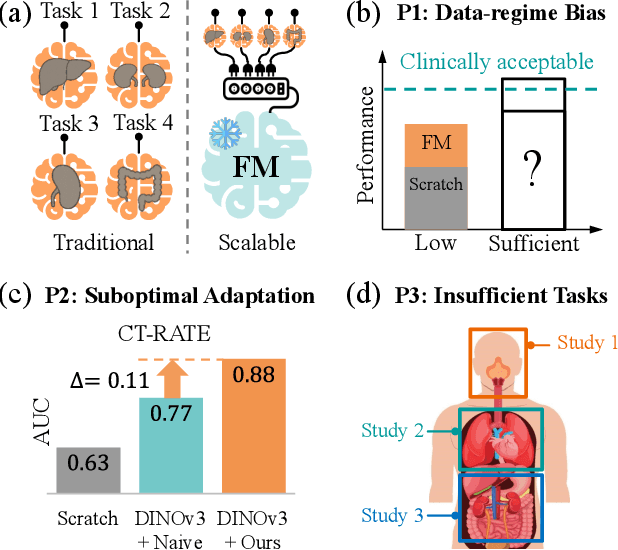
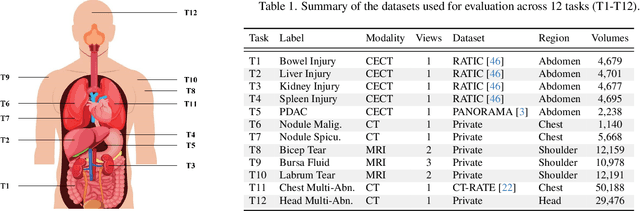
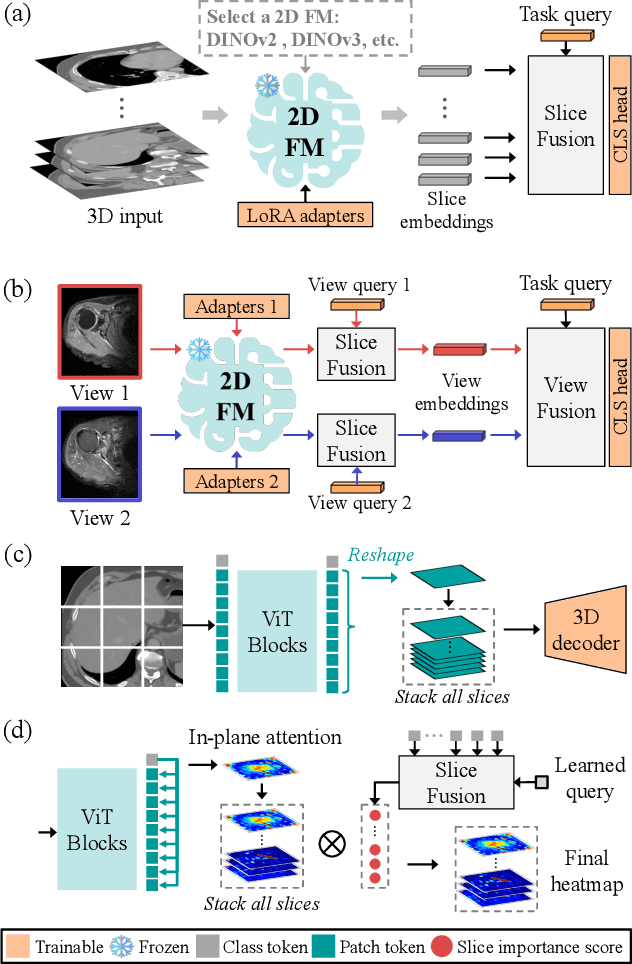
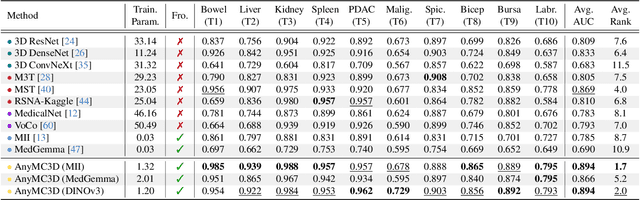
3D medical image classification is essential for modern clinical workflows. Medical foundation models (FMs) have emerged as a promising approach for scaling to new tasks, yet current research suffers from three critical pitfalls: data-regime bias, suboptimal adaptation, and insufficient task coverage. In this paper, we address these pitfalls and introduce AnyMC3D, a scalable 3D classifier adapted from 2D FMs. Our method scales efficiently to new tasks by adding only lightweight plugins (about 1M parameters per task) on top of a single frozen backbone. This versatile framework also supports multi-view inputs, auxiliary pixel-level supervision, and interpretable heatmap generation. We establish a comprehensive benchmark of 12 tasks covering diverse pathologies, anatomies, and modalities, and systematically analyze state-of-the-art 3D classification techniques. Our analysis reveals key insights: (1) effective adaptation is essential to unlock FM potential, (2) general-purpose FMs can match medical-specific FMs if properly adapted, and (3) 2D-based methods surpass 3D architectures for 3D classification. For the first time, we demonstrate the feasibility of achieving state-of-the-art performance across diverse applications using a single scalable framework (including 1st place in the VLM3D challenge), eliminating the need for separate task-specific models.
A Non-contrast Head CT Foundation Model for Comprehensive Neuro-Trauma Triage
Feb 28, 2025



Recent advancements in AI and medical imaging offer transformative potential in emergency head CT interpretation for reducing assessment times and improving accuracy in the face of an increasing request of such scans and a global shortage in radiologists. This study introduces a 3D foundation model for detecting diverse neuro-trauma findings with high accuracy and efficiency. Using large language models (LLMs) for automatic labeling, we generated comprehensive multi-label annotations for critical conditions. Our approach involved pretraining neural networks for hemorrhage subtype segmentation and brain anatomy parcellation, which were integrated into a pretrained comprehensive neuro-trauma detection network through multimodal fine-tuning. Performance evaluation against expert annotations and comparison with CT-CLIP demonstrated strong triage accuracy across major neuro-trauma findings, such as hemorrhage and midline shift, as well as less frequent critical conditions such as cerebral edema and arterial hyperdensity. The integration of neuro-specific features significantly enhanced diagnostic capabilities, achieving an average AUC of 0.861 for 16 neuro-trauma conditions. This work advances foundation models in medical imaging, serving as a benchmark for future AI-assisted neuro-trauma diagnostics in emergency radiology.
Generation of Radiology Findings in Chest X-Ray by Leveraging Collaborative Knowledge
Jun 18, 2023



Among all the sub-sections in a typical radiology report, the Clinical Indications, Findings, and Impression often reflect important details about the health status of a patient. The information included in Impression is also often covered in Findings. While Findings and Impression can be deduced by inspecting the image, Clinical Indications often require additional context. The cognitive task of interpreting medical images remains the most critical and often time-consuming step in the radiology workflow. Instead of generating an end-to-end radiology report, in this paper, we focus on generating the Findings from automated interpretation of medical images, specifically chest X-rays (CXRs). Thus, this work focuses on reducing the workload of radiologists who spend most of their time either writing or narrating the Findings. Unlike past research, which addresses radiology report generation as a single-step image captioning task, we have further taken into consideration the complexity of interpreting CXR images and propose a two-step approach: (a) detecting the regions with abnormalities in the image, and (b) generating relevant text for regions with abnormalities by employing a generative large language model (LLM). This two-step approach introduces a layer of interpretability and aligns the framework with the systematic reasoning that radiologists use when reviewing a CXR.
* Information Technology and Quantitative Management (ITQM 2023)
Self-supervised Learning from 100 Million Medical Images
Jan 04, 2022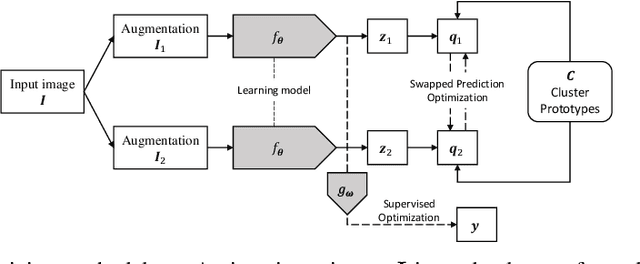
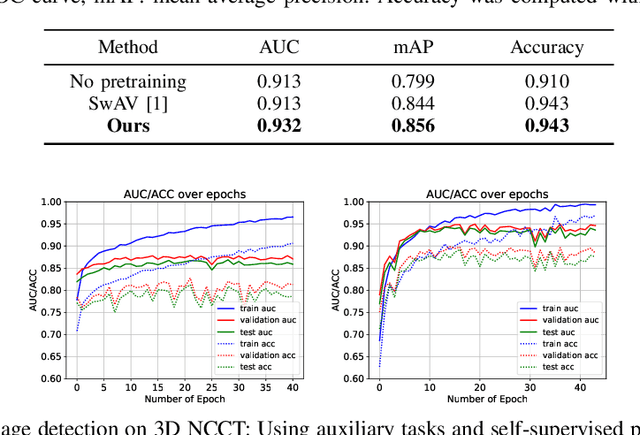
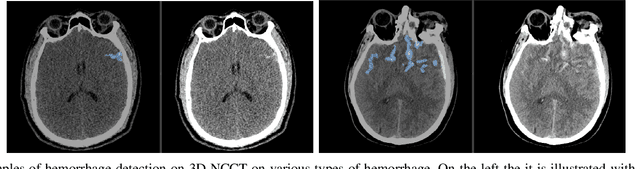
Building accurate and robust artificial intelligence systems for medical image assessment requires not only the research and design of advanced deep learning models but also the creation of large and curated sets of annotated training examples. Constructing such datasets, however, is often very costly -- due to the complex nature of annotation tasks and the high level of expertise required for the interpretation of medical images (e.g., expert radiologists). To counter this limitation, we propose a method for self-supervised learning of rich image features based on contrastive learning and online feature clustering. For this purpose we leverage large training datasets of over 100,000,000 medical images of various modalities, including radiography, computed tomography (CT), magnetic resonance (MR) imaging and ultrasonography. We propose to use these features to guide model training in supervised and hybrid self-supervised/supervised regime on various downstream tasks. We highlight a number of advantages of this strategy on challenging image assessment problems in radiography, CT and MR: 1) Significant increase in accuracy compared to the state-of-the-art (e.g., AUC boost of 3-7% for detection of abnormalities from chest radiography scans and hemorrhage detection on brain CT); 2) Acceleration of model convergence during training by up to 85% compared to using no pretraining (e.g., 83% when training a model for detection of brain metastases in MR scans); 3) Increase in robustness to various image augmentations, such as intensity variations, rotations or scaling reflective of data variation seen in the field.
Robust Classification from Noisy Labels: Integrating Additional Knowledge for Chest Radiography Abnormality Assessment
Apr 21, 2021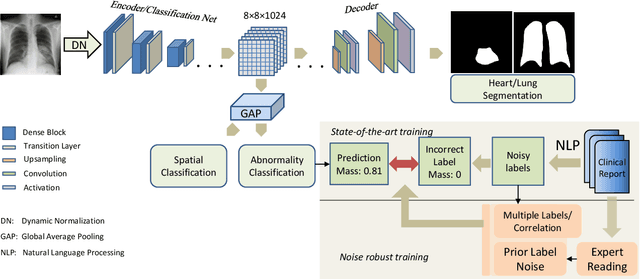
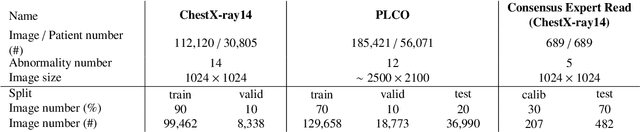
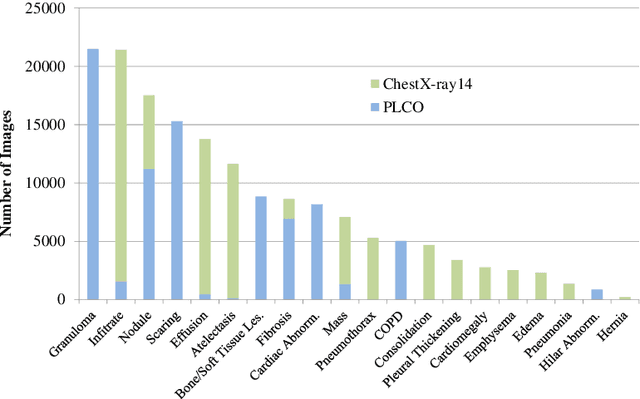
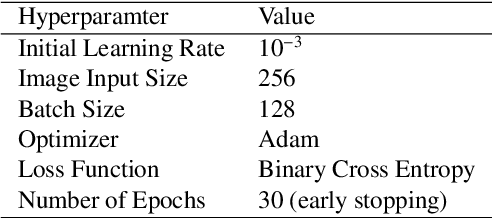
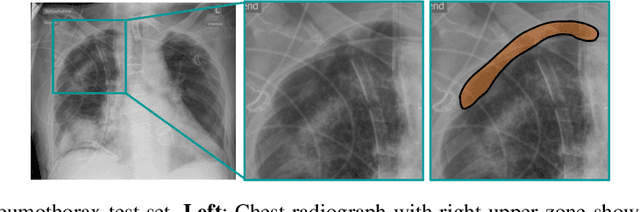
Chest radiography is the most common radiographic examination performed in daily clinical practice for the detection of various heart and lung abnormalities. The large amount of data to be read and reported, with more than 100 studies per day for a single radiologist, poses a challenge in consistently maintaining high interpretation accuracy. The introduction of large-scale public datasets has led to a series of novel systems for automated abnormality classification. However, the labels of these datasets were obtained using natural language processed medical reports, yielding a large degree of label noise that can impact the performance. In this study, we propose novel training strategies that handle label noise from such suboptimal data. Prior label probabilities were measured on a subset of training data re-read by 4 board-certified radiologists and were used during training to increase the robustness of the training model to the label noise. Furthermore, we exploit the high comorbidity of abnormalities observed in chest radiography and incorporate this information to further reduce the impact of label noise. Additionally, anatomical knowledge is incorporated by training the system to predict lung and heart segmentation, as well as spatial knowledge labels. To deal with multiple datasets and images derived from various scanners that apply different post-processing techniques, we introduce a novel image normalization strategy. Experiments were performed on an extensive collection of 297,541 chest radiographs from 86,876 patients, leading to a state-of-the-art performance level for 17 abnormalities from 2 datasets. With an average AUC score of 0.880 across all abnormalities, our proposed training strategies can be used to significantly improve performance scores.
Quantifying and Leveraging Predictive Uncertainty for Medical Image Assessment
Jul 08, 2020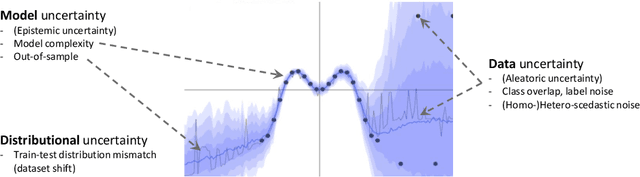

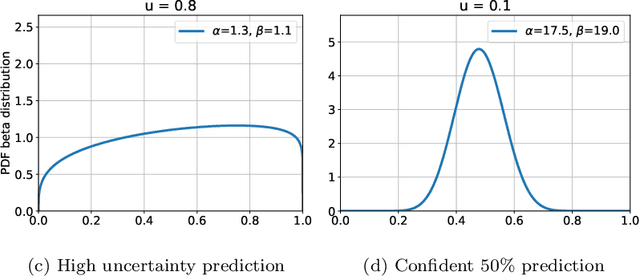
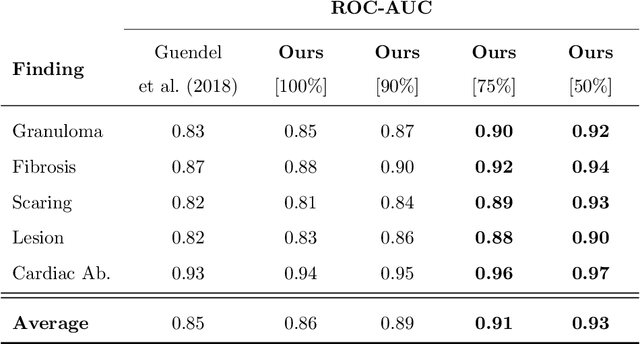
The interpretation of medical images is a challenging task, often complicated by the presence of artifacts, occlusions, limited contrast and more. Most notable is the case of chest radiography, where there is a high inter-rater variability in the detection and classification of abnormalities. This is largely due to inconclusive evidence in the data or subjective definitions of disease appearance. An additional example is the classification of anatomical views based on 2D Ultrasound images. Often, the anatomical context captured in a frame is not sufficient to recognize the underlying anatomy. Current machine learning solutions for these problems are typically limited to providing probabilistic predictions, relying on the capacity of underlying models to adapt to limited information and the high degree of label noise. In practice, however, this leads to overconfident systems with poor generalization on unseen data. To account for this, we propose a system that learns not only the probabilistic estimate for classification, but also an explicit uncertainty measure which captures the confidence of the system in the predicted output. We argue that this approach is essential to account for the inherent ambiguity characteristic of medical images from different radiologic exams including computed radiography, ultrasonography and magnetic resonance imaging. In our experiments we demonstrate that sample rejection based on the predicted uncertainty can significantly improve the ROC-AUC for various tasks, e.g., by 8% to 0.91 with an expected rejection rate of under 25% for the classification of different abnormalities in chest radiographs. In addition, we show that using uncertainty-driven bootstrapping to filter the training data, one can achieve a significant increase in robustness and accuracy.
Machine Learning Automatically Detects COVID-19 using Chest CTs in a Large Multicenter Cohort
Jun 11, 2020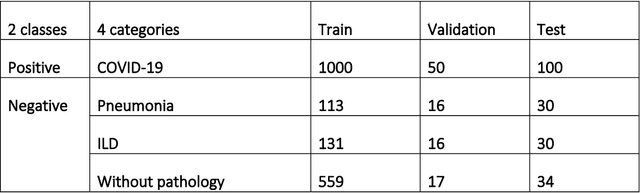
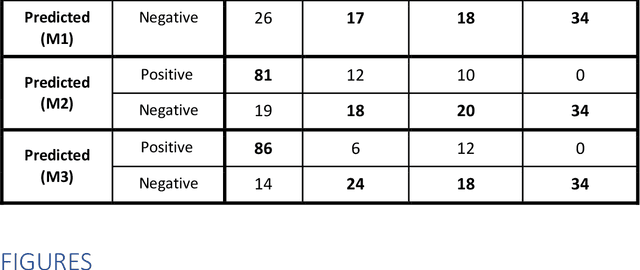
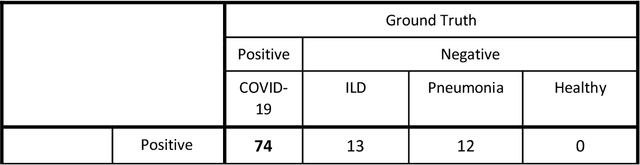

Purpose: To investigate if AI-based classifiers can distinguish COVID-19 from other pulmonary diseases and normal groups, using chest CT images. To study the interpretability of discriminative features for COVID19 detection. Materials and Methods: Our database consists of 2096 CT exams that include CTs from 1150 COVID-19 patients. Training was performed on 1000 COVID-19, 131 ILD, 113 other pneumonias, 559 normal CTs, and testing on 100 COVID-19, 30 ILD, 30 other pneumonias, and 34 normal CTs. A metric-based approach for classification of COVID-19 used interpretable features, relying on logistic regression and random forests. A deep learning-based classifier differentiated COVID-19 based on 3D features extracted directly from CT intensities and from the probability distribution of airspace opacities. Results: Most discriminative features of COVID-19 are percentage of airspace opacity, ground glass opacities, consolidations, and peripheral and basal opacities, which coincide with the typical characterization of COVID-19 in the literature. Unsupervised hierarchical clustering compares the distribution of these features across COVID-19 and control cohorts. The metrics-based classifier achieved AUC, sensitivity, and specificity of respectively 0.85, 0.81, and 0.77. The DL-based classifier achieved AUC, sensitivity, and specificity of respectively 0.90, 0.86, and 0.81. Most of ambiguity comes from non-COVID-19 pneumonia with manifestations that overlap with COVID-19, as well as COVID-19 cases in early stages. Conclusion: A new method discriminates COVID-19 from other types of pneumonia, ILD, and normal, using quantitative patterns from chest CT. Our models balance interpretability of results and classification performance, and therefore may be useful to expedite and improve diagnosis of COVID-19.
3D Tomographic Pattern Synthesis for Enhancing the Quantification of COVID-19
May 05, 2020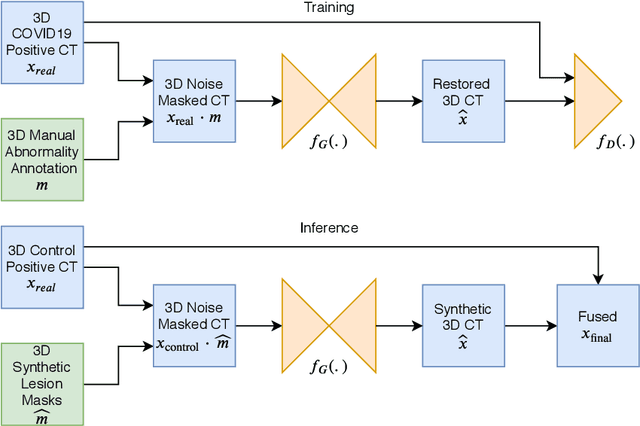
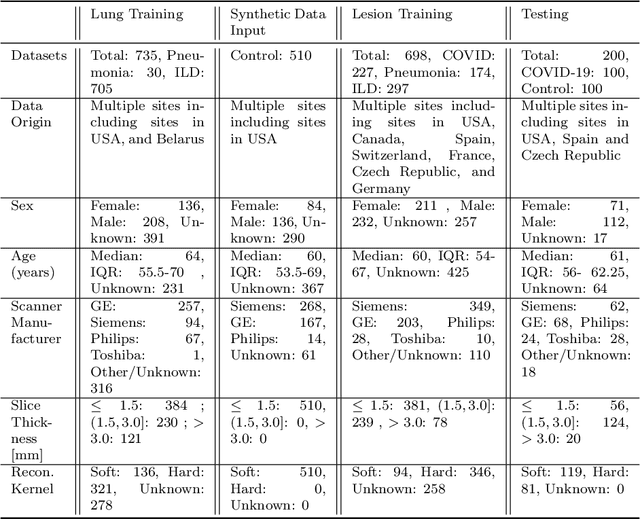
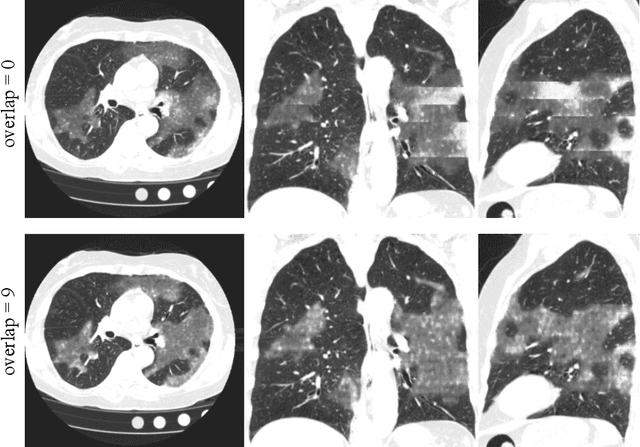
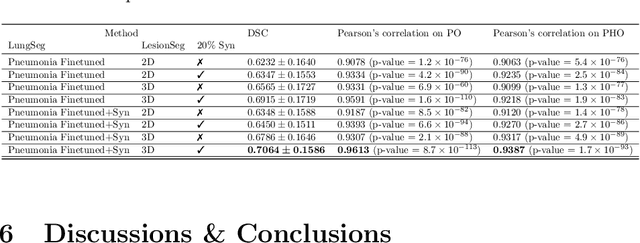
The Coronavirus Disease (COVID-19) has affected 1.8 million people and resulted in more than 110,000 deaths as of April 12, 2020. Several studies have shown that tomographic patterns seen on chest Computed Tomography (CT), such as ground-glass opacities, consolidations, and crazy paving pattern, are correlated with the disease severity and progression. CT imaging can thus emerge as an important modality for the management of COVID-19 patients. AI-based solutions can be used to support CT based quantitative reporting and make reading efficient and reproducible if quantitative biomarkers, such as the Percentage of Opacity (PO), can be automatically computed. However, COVID-19 has posed unique challenges to the development of AI, specifically concerning the availability of appropriate image data and annotations at scale. In this paper, we propose to use synthetic datasets to augment an existing COVID-19 database to tackle these challenges. We train a Generative Adversarial Network (GAN) to inpaint COVID-19 related tomographic patterns on chest CTs from patients without infectious diseases. Additionally, we leverage location priors derived from manually labeled COVID-19 chest CTs patients to generate appropriate abnormality distributions. Synthetic data are used to improve both lung segmentation and segmentation of COVID-19 patterns by adding 20% of synthetic data to the real COVID-19 training data. We collected 2143 chest CTs, containing 327 COVID-19 positive cases, acquired from 12 sites across 7 countries. By testing on 100 COVID-19 positive and 100 control cases, we show that synthetic data can help improve both lung segmentation (+6.02% lesion inclusion rate) and abnormality segmentation (+2.78% dice coefficient), leading to an overall more accurate PO computation (+2.82% Pearson coefficient).
Quantification of Tomographic Patterns associated with COVID-19 from Chest CT
Apr 28, 2020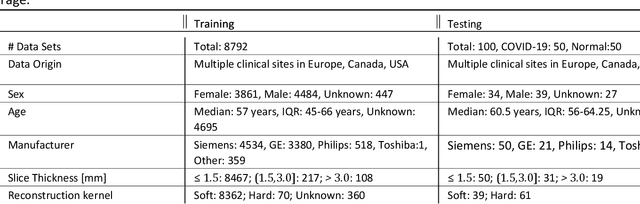
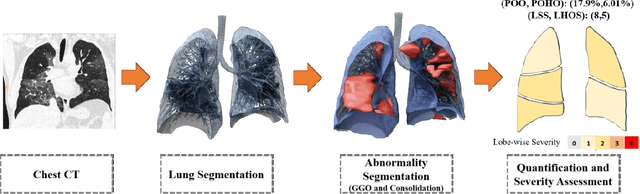
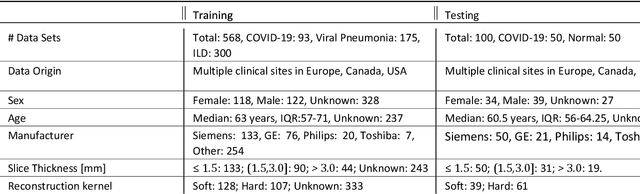
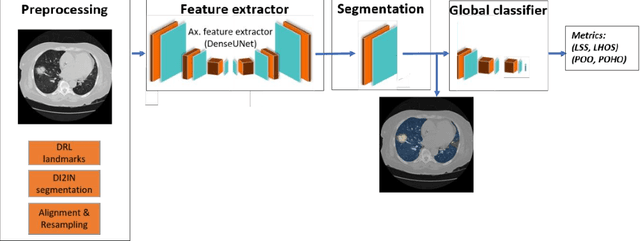
Purpose: To present a method that automatically detects and quantifies abnormal tomographic patterns commonly present in COVID-19, namely Ground Glass Opacities (GGO) and consolidations. Given that high opacity abnormalities (i.e., consolidations) were shown to correlate with severe disease, the paper introduces two combined severity measures (Percentage of Opacity, Percentage of High Opacity) and (Lung Severity Score, Lung High Opacity Score). They quantify the extent of overall COVID-19 abnormalities and the presence of high opacity abnormalities, global and lobe-wise, respectively, being computed based on 3D segmentations of lesions, lungs, and lobes. Materials and Methods: The proposed method takes as input a non-contrasted Chest CT and segments the lesions, lungs, and lobes in 3D. It outputs two combined measures of the severity of lung/lobe involvement, quantifying both the extent of COVID-19 abnormalities and presence of high opacities, based on deep learning and deep reinforcement learning. The first measure (POO, POHO) is global, while the second (LSS, LHOS) is lobe-wise. Evaluation is reported on CTs of 100 subjects (50 COVID-19 confirmed and 50 controls) from institutions from Canada, Europe and US. Ground truth is established by manual annotations of lesions, lungs, and lobes. Results: Pearson Correlation Coefficient between method prediction and ground truth is 0.97 (POO), 0.98 (POHO), 0.96 (LSS), 0.96 (LHOS). Automated processing time to compute the severity scores is 10 seconds/case vs 30 mins needed for manual annotations. Conclusion: A new method identifies regions of abnormalities seen in COVID-19 non-contrasted Chest CT and computes (POO, POHO) and (LSS, LHOS) severity scores.
No Surprises: Training Robust Lung Nodule Detection for Low-Dose CT Scans by Augmenting with Adversarial Attacks
Mar 08, 2020

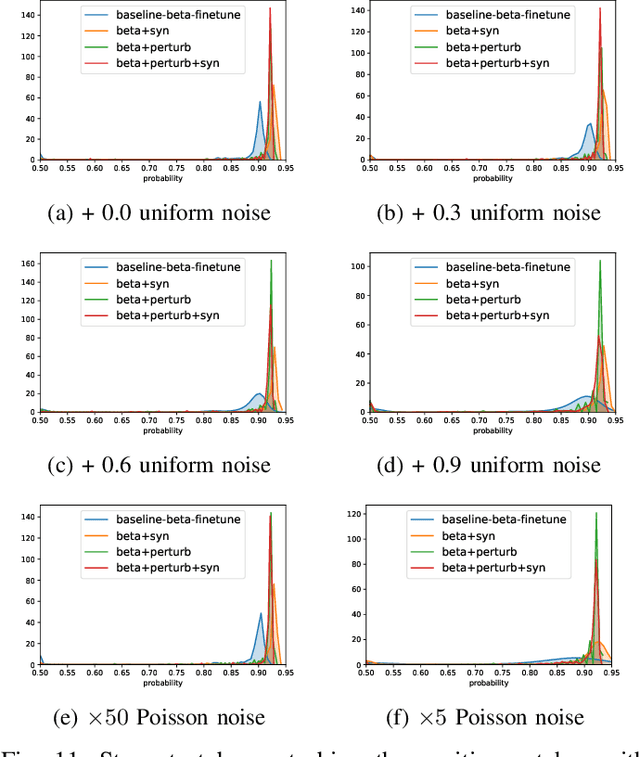
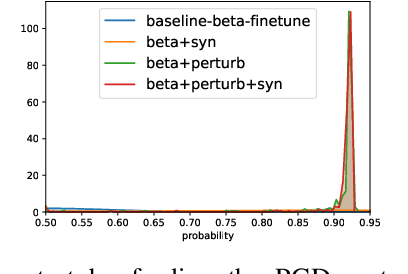
Detecting malignant pulmonary nodules at an early stage can allow medical interventions which increases the survival rate of lung cancer patients. Using computer vision techniques to detect nodules can improve the sensitivity and the speed of interpreting chest CT for lung cancer screening. Many studies have used CNNs to detect nodule candidates. Though such approaches have been shown to outperform the conventional image processing based methods regarding the detection accuracy, CNNs are also known to be limited to generalize on under-represented samples in the training set and prone to imperceptible noise perturbations. Such limitations can not be easily addressed by scaling up the dataset or the models. In this work, we propose to add adversarial synthetic nodules and adversarial attack samples to the training data to improve the generalization and the robustness of the lung nodule detection systems. In order to generate hard examples of nodules from a differentiable nodule synthesizer, we use projected gradient descent (PGD) to search the latent code within a bounded neighbourhood that would generate nodules to decrease the detector response. To make the network more robust to unanticipated noise perturbations, we use PGD to search for noise patterns that can trigger the network to give over-confident mistakes. By evaluating on two different benchmark datasets containing consensus annotations from three radiologists, we show that the proposed techniques can improve the detection performance on real CT data. To understand the limitations of both the conventional networks and the proposed augmented networks, we also perform stress-tests on the false positive reduction networks by feeding different types of artificially produced patches. We show that the augmented networks are more robust to both under-represented nodules as well as resistant to noise perturbations.