 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep learning-based segmentation of T1 and T2 cardiac MRI maps for automated disease detection
Jul 01, 2025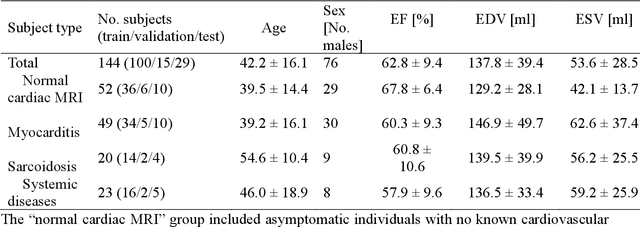
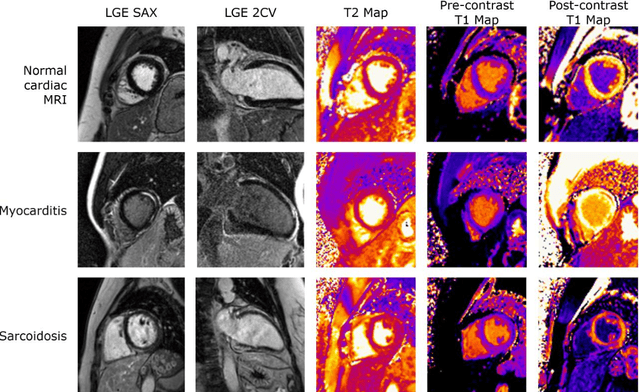
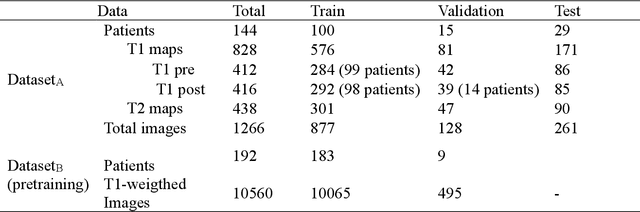
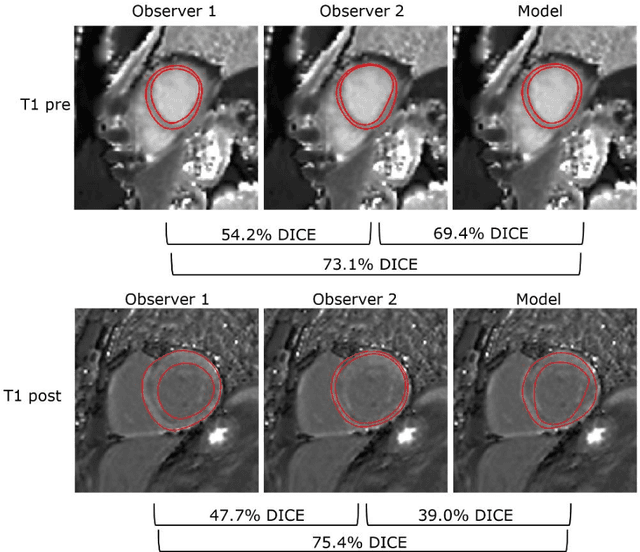
Objectives Parametric tissue mapping enables quantitative cardiac tissue characterization but is limited by inter-observer variability during manual delineation. Traditional approaches relying on average relaxation values and single cutoffs may oversimplify myocardial complexity. This study evaluates whether deep learning (DL) can achieve segmentation accuracy comparable to inter-observer variability, explores the utility of statistical features beyond mean T1/T2 values, and assesses whether machine learning (ML) combining multiple features enhances disease detection. Materials & Methods T1 and T2 maps were manually segmented. The test subset was independently annotated by two observers, and inter-observer variability was assessed. A DL model was trained to segment left ventricle blood pool and myocardium. Average (A), lower quartile (LQ), median (M), and upper quartile (UQ) were computed for the myocardial pixels and employed in classification by applying cutoffs or in ML. Dice similarity coefficient (DICE) and mean absolute percentage error evaluated segmentation performance. Bland-Altman plots assessed inter-user and model-observer agreement. Receiver operating characteristic analysis determined optimal cutoffs. Pearson correlation compared features from model and manual segmentations. F1-score, precision, and recall evaluated classification performance. Wilcoxon test assessed differences between classification methods, with p < 0.05 considered statistically significant. Results 144 subjects were split into training (100), validation (15) and evaluation (29) subsets. Segmentation model achieved a DICE of 85.4%, surpassing inter-observer agreement. Random forest applied to all features increased F1-score (92.7%, p < 0.001). Conclusion DL facilitates segmentation of T1/ T2 maps. Combining multiple features with ML improves disease detection.
Privacy-Preserving Medical Image Classification through Deep Learning and Matrix Decomposition
Aug 31, 2023



Deep learning (DL)-based solutions have been extensively researched in the medical domain in recent years, enhancing the efficacy of diagnosis, planning, and treatment. Since the usage of health-related data is strictly regulated, processing medical records outside the hospital environment for developing and using DL models demands robust data protection measures. At the same time, it can be challenging to guarantee that a DL solution delivers a minimum level of performance when being trained on secured data, without being specifically designed for the given task. Our approach uses singular value decomposition (SVD) and principal component analysis (PCA) to obfuscate the medical images before employing them in the DL analysis. The capability of DL algorithms to extract relevant information from secured data is assessed on a task of angiographic view classification based on obfuscated frames. The security level is probed by simulated artificial intelligence (AI)-based reconstruction attacks, considering two threat actors with different prior knowledge of the targeted data. The degree of privacy is quantitatively measured using similarity indices. Although a trade-off between privacy and accuracy should be considered, the proposed technique allows for training the angiographic view classifier exclusively on secured data with satisfactory performance and with no computational overhead, model adaptation, or hyperparameter tuning. While the obfuscated medical image content is well protected against human perception, the hypothetical reconstruction attack proved that it is also difficult to recover the complete information of the original frames.
* 6 pages, 9 figures, Published in: 2023 31st Mediterranean Conference on Control and Automation (MED)
Generation of Radiology Findings in Chest X-Ray by Leveraging Collaborative Knowledge
Jun 18, 2023



Among all the sub-sections in a typical radiology report, the Clinical Indications, Findings, and Impression often reflect important details about the health status of a patient. The information included in Impression is also often covered in Findings. While Findings and Impression can be deduced by inspecting the image, Clinical Indications often require additional context. The cognitive task of interpreting medical images remains the most critical and often time-consuming step in the radiology workflow. Instead of generating an end-to-end radiology report, in this paper, we focus on generating the Findings from automated interpretation of medical images, specifically chest X-rays (CXRs). Thus, this work focuses on reducing the workload of radiologists who spend most of their time either writing or narrating the Findings. Unlike past research, which addresses radiology report generation as a single-step image captioning task, we have further taken into consideration the complexity of interpreting CXR images and propose a two-step approach: (a) detecting the regions with abnormalities in the image, and (b) generating relevant text for regions with abnormalities by employing a generative large language model (LLM). This two-step approach introduces a layer of interpretability and aligns the framework with the systematic reasoning that radiologists use when reviewing a CXR.
* Information Technology and Quantitative Management (ITQM 2023)