 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnbalanced optimal transport for robust longitudinal lesion evolution with registration-aware and appearance-guided priors
Feb 10, 2026Evaluating lesion evolution in longitudinal CT scans of can cer patients is essential for assessing treatment response, yet establishing reliable lesion correspondence across time remains challenging. Standard bipartite matchers, which rely on geometric proximity, struggle when lesions appear, disappear, merge, or split. We propose a registration-aware matcher based on unbalanced optimal transport (UOT) that accommodates unequal lesion mass and adapts priors to patient-level tumor-load changes. Our transport cost blends (i) size-normalized geometry, (ii) local registration trust from the deformation-field Jacobian, and (iii) optional patch-level appearance consistency. The resulting transport plan is sparsified by relative pruning, yielding one-to-one matches as well as new, disappearing, merging, and splitting lesions without retraining or heuristic rules. On longitudinal CT data, our approach achieves consistently higher edge-detection precision and recall, improved lesion-state recall, and superior lesion-graph component F1 scores versus distance-only baselines.
Self-Supervised Learning for Interventional Image Analytics: Towards Robust Device Trackers
May 02, 2024An accurate detection and tracking of devices such as guiding catheters in live X-ray image acquisitions is an essential prerequisite for endovascular cardiac interventions. This information is leveraged for procedural guidance, e.g., directing stent placements. To ensure procedural safety and efficacy, there is a need for high robustness no failures during tracking. To achieve that, one needs to efficiently tackle challenges, such as: device obscuration by contrast agent or other external devices or wires, changes in field-of-view or acquisition angle, as well as the continuous movement due to cardiac and respiratory motion. To overcome the aforementioned challenges, we propose a novel approach to learn spatio-temporal features from a very large data cohort of over 16 million interventional X-ray frames using self-supervision for image sequence data. Our approach is based on a masked image modeling technique that leverages frame interpolation based reconstruction to learn fine inter-frame temporal correspondences. The features encoded in the resulting model are fine-tuned downstream. Our approach achieves state-of-the-art performance and in particular robustness compared to ultra optimized reference solutions (that use multi-stage feature fusion, multi-task and flow regularization). The experiments show that our method achieves 66.31% reduction in maximum tracking error against reference solutions (23.20% when flow regularization is used); achieving a success score of 97.95% at a 3x faster inference speed of 42 frames-per-second (on GPU). The results encourage the use of our approach in various other tasks within interventional image analytics that require effective understanding of spatio-temporal semantics.
Self-supervised Learning from 100 Million Medical Images
Jan 04, 2022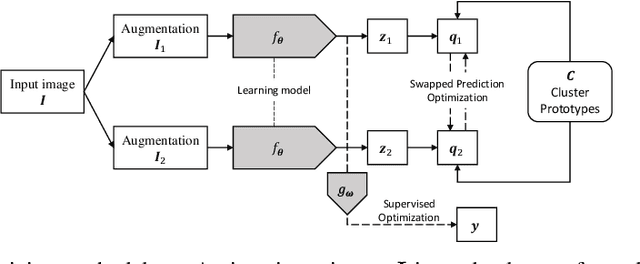
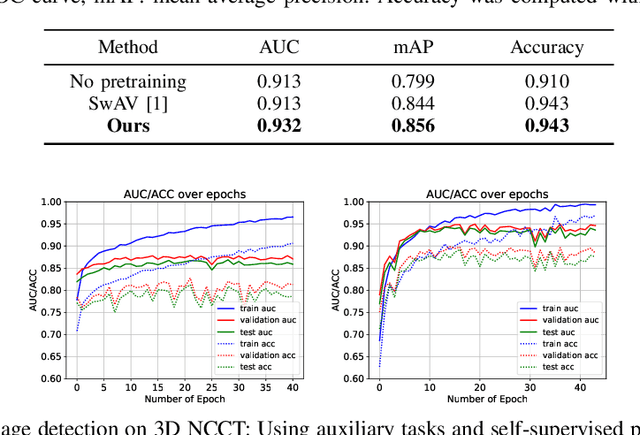
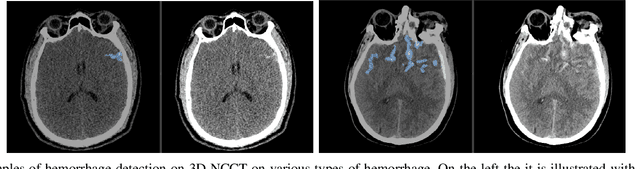
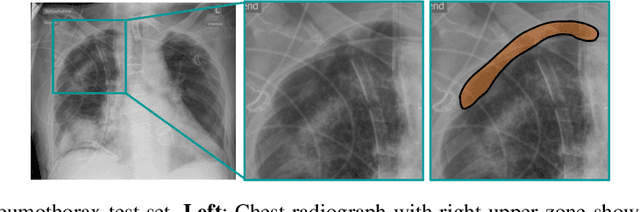
Building accurate and robust artificial intelligence systems for medical image assessment requires not only the research and design of advanced deep learning models but also the creation of large and curated sets of annotated training examples. Constructing such datasets, however, is often very costly -- due to the complex nature of annotation tasks and the high level of expertise required for the interpretation of medical images (e.g., expert radiologists). To counter this limitation, we propose a method for self-supervised learning of rich image features based on contrastive learning and online feature clustering. For this purpose we leverage large training datasets of over 100,000,000 medical images of various modalities, including radiography, computed tomography (CT), magnetic resonance (MR) imaging and ultrasonography. We propose to use these features to guide model training in supervised and hybrid self-supervised/supervised regime on various downstream tasks. We highlight a number of advantages of this strategy on challenging image assessment problems in radiography, CT and MR: 1) Significant increase in accuracy compared to the state-of-the-art (e.g., AUC boost of 3-7% for detection of abnormalities from chest radiography scans and hemorrhage detection on brain CT); 2) Acceleration of model convergence during training by up to 85% compared to using no pretraining (e.g., 83% when training a model for detection of brain metastases in MR scans); 3) Increase in robustness to various image augmentations, such as intensity variations, rotations or scaling reflective of data variation seen in the field.
A Self-Taught Artificial Agent for Multi-Physics Computational Model Personalization
May 01, 2016
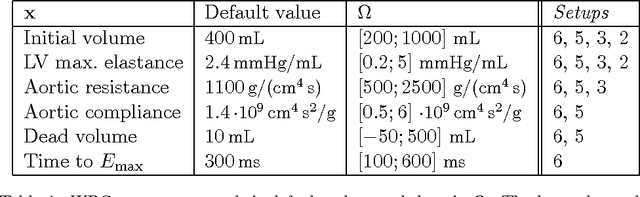
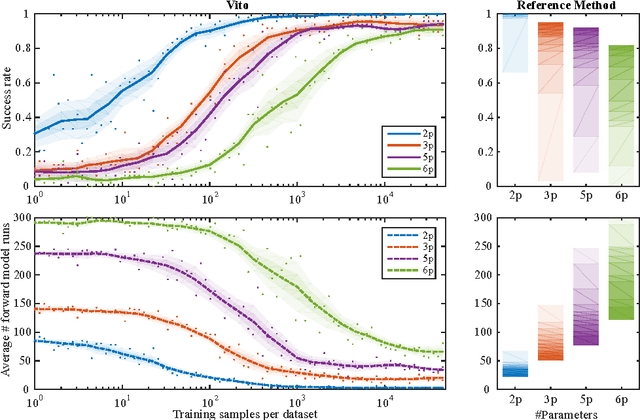

Personalization is the process of fitting a model to patient data, a critical step towards application of multi-physics computational models in clinical practice. Designing robust personalization algorithms is often a tedious, time-consuming, model- and data-specific process. We propose to use artificial intelligence concepts to learn this task, inspired by how human experts manually perform it. The problem is reformulated in terms of reinforcement learning. In an off-line phase, Vito, our self-taught artificial agent, learns a representative decision process model through exploration of the computational model: it learns how the model behaves under change of parameters. The agent then automatically learns an optimal strategy for on-line personalization. The algorithm is model-independent; applying it to a new model requires only adjusting few hyper-parameters of the agent and defining the observations to match. The full knowledge of the model itself is not required. Vito was tested in a synthetic scenario, showing that it could learn how to optimize cost functions generically. Then Vito was applied to the inverse problem of cardiac electrophysiology and the personalization of a whole-body circulation model. The obtained results suggested that Vito could achieve equivalent, if not better goodness of fit than standard methods, while being more robust (up to 11% higher success rates) and with faster (up to seven times) convergence rate. Our artificial intelligence approach could thus make personalization algorithms generalizable and self-adaptable to any patient and any model.