 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArbitrary Data as Images: Fusion of Patient Data Across Modalities and Irregular Intervals with Vision Transformers
Jan 30, 2025



A patient undergoes multiple examinations in each hospital stay, where each provides different facets of the health status. These assessments include temporal data with varying sampling rates, discrete single-point measurements, therapeutic interventions such as medication administration, and images. While physicians are able to process and integrate diverse modalities intuitively, neural networks need specific modeling for each modality complicating the training procedure. We demonstrate that this complexity can be significantly reduced by visualizing all information as images along with unstructured text and subsequently training a conventional vision-text transformer. Our approach, Vision Transformer for irregular sampled Multi-modal Measurements (ViTiMM), not only simplifies data preprocessing and modeling but also outperforms current state-of-the-art methods in predicting in-hospital mortality and phenotyping, as evaluated on 6,175 patients from the MIMIC-IV dataset. The modalities include patient's clinical measurements, medications, X-ray images, and electrocardiography scans. We hope our work inspires advancements in multi-modal medical AI by reducing the training complexity to (visual) prompt engineering, thus lowering entry barriers and enabling no-code solutions for training. The source code will be made publicly available.
Content-Aware Differential Privacy with Conditional Invertible Neural Networks
Jul 29, 2022
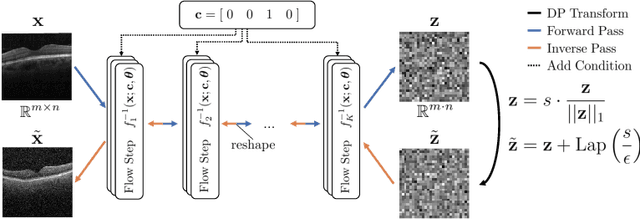

Differential privacy (DP) has arisen as the gold standard in protecting an individual's privacy in datasets by adding calibrated noise to each data sample. While the application to categorical data is straightforward, its usability in the context of images has been limited. Contrary to categorical data the meaning of an image is inherent in the spatial correlation of neighboring pixels making the simple application of noise infeasible. Invertible Neural Networks (INN) have shown excellent generative performance while still providing the ability to quantify the exact likelihood. Their principle is based on transforming a complicated distribution into a simple one e.g. an image into a spherical Gaussian. We hypothesize that adding noise to the latent space of an INN can enable differentially private image modification. Manipulation of the latent space leads to a modified image while preserving important details. Further, by conditioning the INN on meta-data provided with the dataset we aim at leaving dimensions important for downstream tasks like classification untouched while altering other parts that potentially contain identifying information. We term our method content-aware differential privacy (CADP). We conduct experiments on publicly available benchmarking datasets as well as dedicated medical ones. In addition, we show the generalizability of our method to categorical data. The source code is publicly available at https://github.com/Cardio-AI/CADP.
A Self-Taught Artificial Agent for Multi-Physics Computational Model Personalization
May 01, 2016
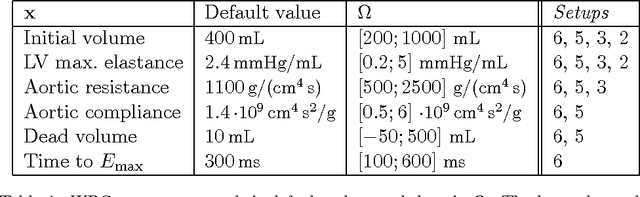
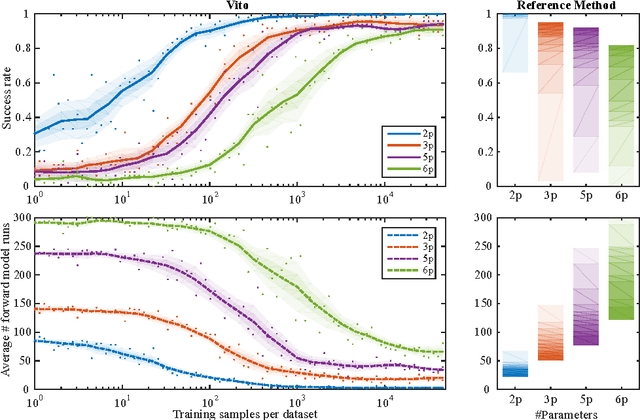

Personalization is the process of fitting a model to patient data, a critical step towards application of multi-physics computational models in clinical practice. Designing robust personalization algorithms is often a tedious, time-consuming, model- and data-specific process. We propose to use artificial intelligence concepts to learn this task, inspired by how human experts manually perform it. The problem is reformulated in terms of reinforcement learning. In an off-line phase, Vito, our self-taught artificial agent, learns a representative decision process model through exploration of the computational model: it learns how the model behaves under change of parameters. The agent then automatically learns an optimal strategy for on-line personalization. The algorithm is model-independent; applying it to a new model requires only adjusting few hyper-parameters of the agent and defining the observations to match. The full knowledge of the model itself is not required. Vito was tested in a synthetic scenario, showing that it could learn how to optimize cost functions generically. Then Vito was applied to the inverse problem of cardiac electrophysiology and the personalization of a whole-body circulation model. The obtained results suggested that Vito could achieve equivalent, if not better goodness of fit than standard methods, while being more robust (up to 11% higher success rates) and with faster (up to seven times) convergence rate. Our artificial intelligence approach could thus make personalization algorithms generalizable and self-adaptable to any patient and any model.