 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVIViT: Variable-Input Vision Transformer Framework for 3D MR Image Segmentation
May 13, 2025Self-supervised pretrain techniques have been widely used to improve the downstream tasks' performance. However, real-world magnetic resonance (MR) studies usually consist of different sets of contrasts due to different acquisition protocols, which poses challenges for the current deep learning methods on large-scale pretrain and different downstream tasks with different input requirements, since these methods typically require a fixed set of input modalities or, contrasts. To address this challenge, we propose variable-input ViT (VIViT), a transformer-based framework designed for self-supervised pretraining and segmentation finetuning for variable contrasts in each study. With this ability, our approach can maximize the data availability in pretrain, and can transfer the learned knowledge from pretrain to downstream tasks despite variations in input requirements. We validate our method on brain infarct and brain tumor segmentation, where our method outperforms current CNN and ViT-based models with a mean Dice score of 0.624 and 0.883 respectively. These results highlight the efficacy of our design for better adaptability and performance on tasks with real-world heterogeneous MR data.
Multi-Plane Vision Transformer for Hemorrhage Classification Using Axial and Sagittal MRI Data
May 12, 2025Identifying brain hemorrhages from magnetic resonance imaging (MRI) is a critical task for healthcare professionals. The diverse nature of MRI acquisitions with varying contrasts and orientation introduce complexity in identifying hemorrhage using neural networks. For acquisitions with varying orientations, traditional methods often involve resampling images to a fixed plane, which can lead to information loss. To address this, we propose a 3D multi-plane vision transformer (MP-ViT) for hemorrhage classification with varying orientation data. It employs two separate transformer encoders for axial and sagittal contrasts, using cross-attention to integrate information across orientations. MP-ViT also includes a modality indication vector to provide missing contrast information to the model. The effectiveness of the proposed model is demonstrated with extensive experiments on real world clinical dataset consists of 10,084 training, 1,289 validation and 1,496 test subjects. MP-ViT achieved substantial improvement in area under the curve (AUC), outperforming the vision transformer (ViT) by 5.5% and CNN-based architectures by 1.8%. These results highlight the potential of MP-ViT in improving performance for hemorrhage detection when different orientation contrasts are needed.
AdaViT: Adaptive Vision Transformer for Flexible Pretrain and Finetune with Variable 3D Medical Image Modalities
Apr 04, 2025



Pretrain techniques, whether supervised or self-supervised, are widely used in deep learning to enhance model performance. In real-world clinical scenarios, different sets of magnetic resonance (MR) contrasts are often acquired for different subjects/cases, creating challenges for deep learning models assuming consistent input modalities among all the cases and between pretrain and finetune. Existing methods struggle to maintain performance when there is an input modality/contrast set mismatch with the pretrained model, often resulting in degraded accuracy. We propose an adaptive Vision Transformer (AdaViT) framework capable of handling variable set of input modalities for each case. We utilize a dynamic tokenizer to encode different input image modalities to tokens and take advantage of the characteristics of the transformer to build attention mechanism across variable length of tokens. Through extensive experiments, we demonstrate that this architecture effectively transfers supervised pretrained models to new datasets with different input modality/contrast sets, resulting in superior performance on zero-shot testing, few-shot finetuning, and backward transferring in brain infarct and brain tumor segmentation tasks. Additionally, for self-supervised pretrain, the proposed method is able to maximize the pretrain data and facilitate transferring to diverse downstream tasks with variable sets of input modalities.
SegResMamba: An Efficient Architecture for 3D Medical Image Segmentation
Mar 10, 2025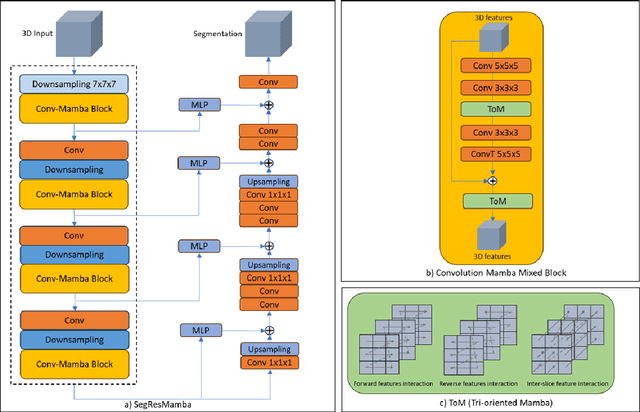



The Transformer architecture has opened a new paradigm in the domain of deep learning with its ability to model long-range dependencies and capture global context and has outpaced the traditional Convolution Neural Networks (CNNs) in many aspects. However, applying Transformer models to 3D medical image datasets presents significant challenges due to their high training time, and memory requirements, which not only hinder scalability but also contribute to elevated CO$_2$ footprint. This has led to an exploration of alternative models that can maintain or even improve performance while being more efficient and environmentally sustainable. Recent advancements in Structured State Space Models (SSMs) effectively address some of the inherent limitations of Transformers, particularly their high memory and computational demands. Inspired by these advancements, we propose an efficient 3D segmentation model for medical imaging called SegResMamba, designed to reduce computation complexity, memory usage, training time, and environmental impact while maintaining high performance. Our model uses less than half the memory during training compared to other state-of-the-art (SOTA) architectures, achieving comparable performance with significantly reduced resource demands.
Self Pre-training with Adaptive Mask Autoencoders for Variable-Contrast 3D Medical Imaging
Jan 15, 2025The Masked Autoencoder (MAE) has recently demonstrated effectiveness in pre-training Vision Transformers (ViT) for analyzing natural images. By reconstructing complete images from partially masked inputs, the ViT encoder gathers contextual information to predict the missing regions. This capability to aggregate context is especially important in medical imaging, where anatomical structures are functionally and mechanically linked to surrounding regions. However, current methods do not consider variations in the number of input images, which is typically the case in real-world Magnetic Resonance (MR) studies. To address this limitation, we propose a 3D Adaptive Masked Autoencoders (AMAE) architecture that accommodates a variable number of 3D input contrasts per subject. A magnetic resonance imaging (MRI) dataset of 45,364 subjects was used for pretraining and a subset of 1648 training, 193 validation and 215 test subjects were used for finetuning. The performance demonstrates that self pre-training of this adaptive masked autoencoders can enhance the infarct segmentation performance by 2.8%-3.7% for ViT-based segmentation models.
Self-Supervised Learning for Interventional Image Analytics: Towards Robust Device Trackers
May 02, 2024An accurate detection and tracking of devices such as guiding catheters in live X-ray image acquisitions is an essential prerequisite for endovascular cardiac interventions. This information is leveraged for procedural guidance, e.g., directing stent placements. To ensure procedural safety and efficacy, there is a need for high robustness no failures during tracking. To achieve that, one needs to efficiently tackle challenges, such as: device obscuration by contrast agent or other external devices or wires, changes in field-of-view or acquisition angle, as well as the continuous movement due to cardiac and respiratory motion. To overcome the aforementioned challenges, we propose a novel approach to learn spatio-temporal features from a very large data cohort of over 16 million interventional X-ray frames using self-supervision for image sequence data. Our approach is based on a masked image modeling technique that leverages frame interpolation based reconstruction to learn fine inter-frame temporal correspondences. The features encoded in the resulting model are fine-tuned downstream. Our approach achieves state-of-the-art performance and in particular robustness compared to ultra optimized reference solutions (that use multi-stage feature fusion, multi-task and flow regularization). The experiments show that our method achieves 66.31% reduction in maximum tracking error against reference solutions (23.20% when flow regularization is used); achieving a success score of 97.95% at a 3x faster inference speed of 42 frames-per-second (on GPU). The results encourage the use of our approach in various other tasks within interventional image analytics that require effective understanding of spatio-temporal semantics.