 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
Towards in-store multi-person tracking using head detection and track heatmaps
May 16, 2020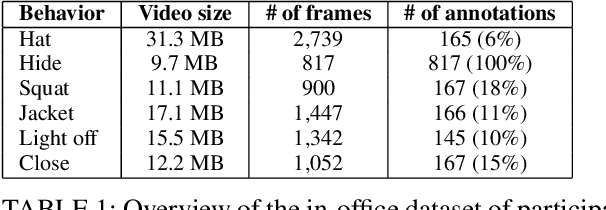

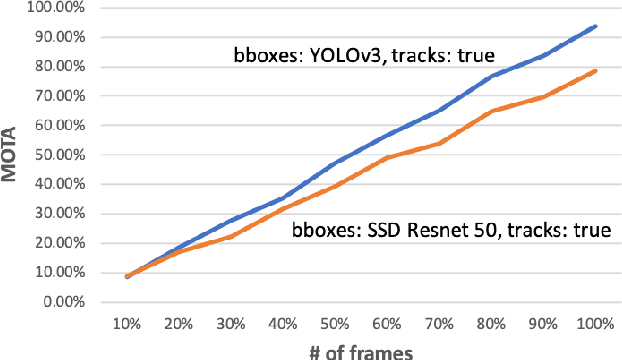
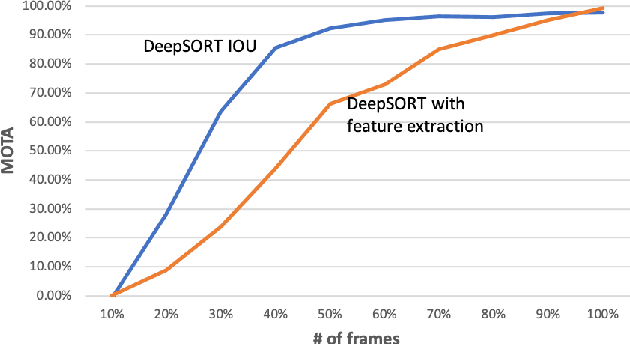
Computer vision algorithms are being implemented across a breadth of industries to enable technological innovations. In this paper, we study the problem of computer vision based customer tracking in retail industry. To this end, we introduce a dataset collected from a camera in an office environment where participants mimic various behaviors of customers in a supermarket. In addition, we describe an illustrative example of the use of this dataset for tracking participants based on a head tracking model in an effort to minimize errors due to occlusion. Furthermore, we propose a model for recognizing customers and staff based on their movement patterns. The model is evaluated using a real-world dataset collected in a supermarket over a 24-hour period that achieves 98\% accuracy during training and 93\% accuracy during evaluation.
3D Organ Shape Reconstruction from Topogram Images
Mar 29, 2019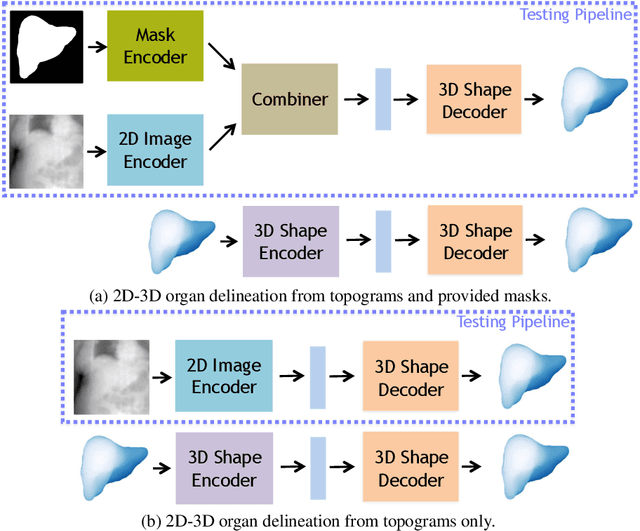

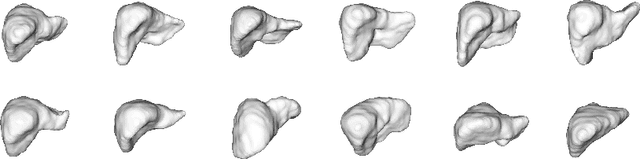

Automatic delineation and measurement of main organs such as liver is one of the critical steps for assessment of hepatic diseases, planning and postoperative or treatment follow-up. However, addressing this problem typically requires performing computed tomography (CT) scanning and complicated postprocessing of the resulting scans using slice-by-slice techniques. In this paper, we show that 3D organ shape can be automatically predicted directly from topogram images, which are easier to acquire and have limited exposure to radiation during acquisition, compared to CT scans. We evaluate our approach on the challenging task of predicting liver shape using a generative model. We also demonstrate that our method can be combined with user annotations, such as a 2D mask, for improved prediction accuracy. We show compelling results on 3D liver shape reconstruction and volume estimation on 2129 CT scans.
Structure-Aware Shape Synthesis
Aug 04, 2018

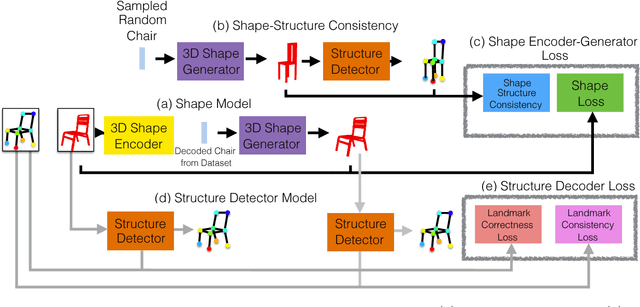
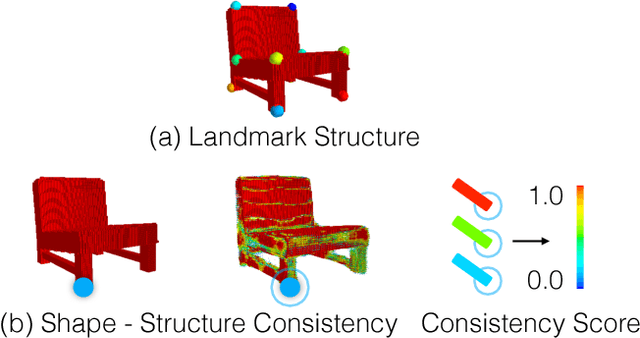
We propose a new procedure to guide training of a data-driven shape generative model using a structure-aware loss function. Complex 3D shapes often can be summarized using a coarsely defined structure which is consistent and robust across variety of observations. However, existing synthesis techniques do not account for structure during training, and thus often generate implausible and structurally unrealistic shapes. During training, we enforce structural constraints in order to enforce consistency and structure across the entire manifold. We propose a novel methodology for training 3D generative models that incorporates structural information into an end-to-end training pipeline.
Group Iterative Spectrum Thresholding for Super-Resolution Sparse Spectral Selection
Jul 29, 2013
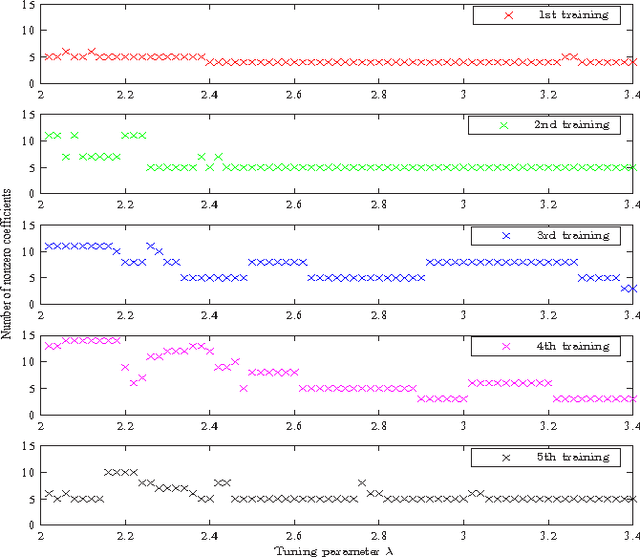
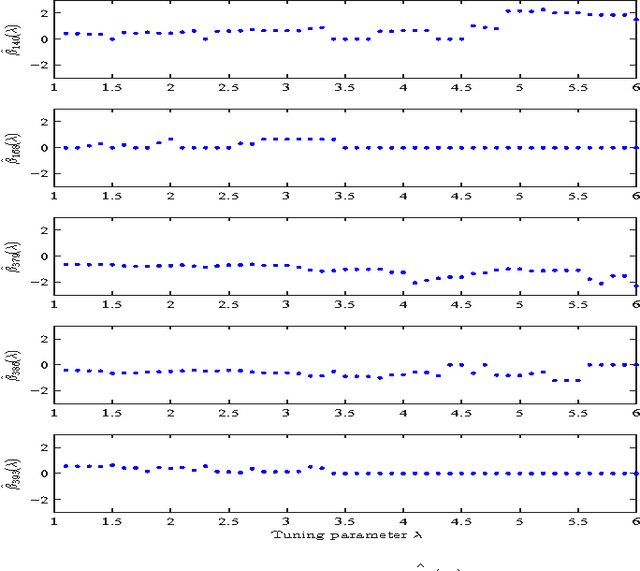
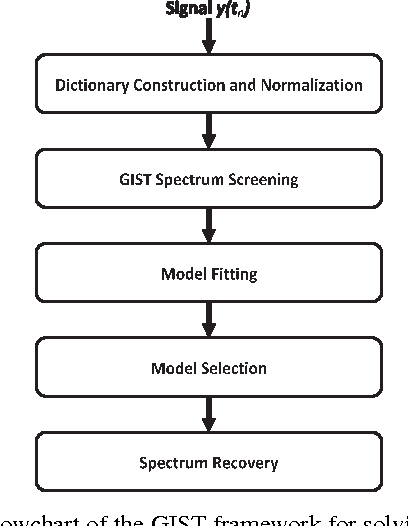
Recently, sparsity-based algorithms are proposed for super-resolution spectrum estimation. However, to achieve adequately high resolution in real-world signal analysis, the dictionary atoms have to be close to each other in frequency, thereby resulting in a coherent design. The popular convex compressed sensing methods break down in presence of high coherence and large noise. We propose a new regularization approach to handle model collinearity and obtain parsimonious frequency selection simultaneously. It takes advantage of the pairing structure of sine and cosine atoms in the frequency dictionary. A probabilistic spectrum screening is also developed for fast computation in high dimensions. A data-resampling version of high-dimensional Bayesian Information Criterion is used to determine the regularization parameters. Experiments show the efficacy and efficiency of the proposed algorithms in challenging situations with small sample size, high frequency resolution, and low signal-to-noise ratio.