 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQA-TOOLBOX: Conversational Question-Answering for process task guidance in manufacturing
Dec 03, 2024



In this work we explore utilizing LLMs for data augmentation for manufacturing task guidance system. The dataset consists of representative samples of interactions with technicians working in an advanced manufacturing setting. The purpose of this work to explore the task, data augmentation for the supported tasks and evaluating the performance of the existing LLMs. We observe that that task is complex requiring understanding from procedure specification documents, actions and objects sequenced temporally. The dataset consists of 200,000+ question/answer pairs that refer to the spec document and are grounded in narrations and/or video demonstrations. We compared the performance of several popular open-sourced LLMs by developing a baseline using each LLM and then compared the responses in a reference-free setting using LLM-as-a-judge and compared the ratings with crowd-workers whilst validating the ratings with experts.
My Art My Choice: Adversarial Protection Against Unruly AI
Sep 06, 2023Generative AI is on the rise, enabling everyone to produce realistic content via publicly available interfaces. Especially for guided image generation, diffusion models are changing the creator economy by producing high quality low cost content. In parallel, artists are rising against unruly AI, since their artwork are leveraged, distributed, and dissimulated by large generative models. Our approach, My Art My Choice (MAMC), aims to empower content owners by protecting their copyrighted materials from being utilized by diffusion models in an adversarial fashion. MAMC learns to generate adversarially perturbed "protected" versions of images which can in turn "break" diffusion models. The perturbation amount is decided by the artist to balance distortion vs. protection of the content. MAMC is designed with a simple UNet-based generator, attacking black box diffusion models, combining several losses to create adversarial twins of the original artwork. We experiment on three datasets for various image-to-image tasks, with different user control values. Both protected image and diffusion output results are evaluated in visual, noise, structure, pixel, and generative spaces to validate our claims. We believe that MAMC is a crucial step for preserving ownership information for AI generated content in a flawless, based-on-need, and human-centric way.
Distill and Collect for Semi-Supervised Temporal Action Segmentation
Nov 03, 2022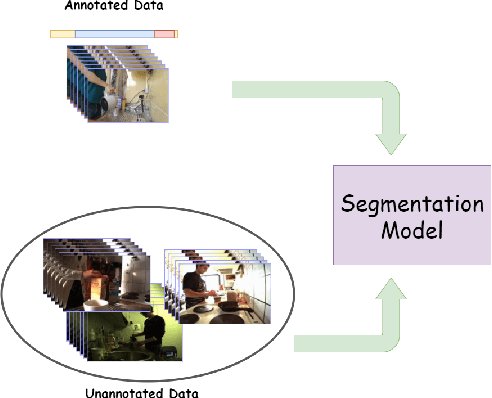
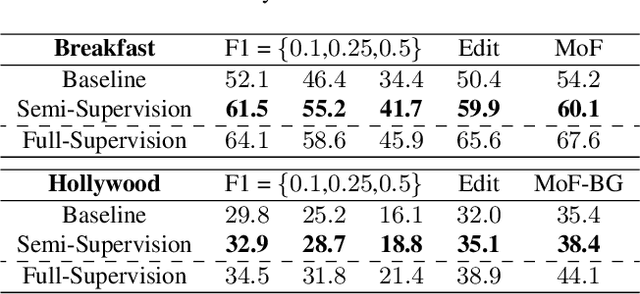
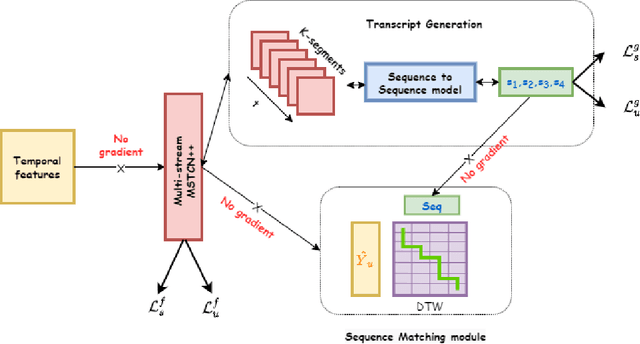

Recent temporal action segmentation approaches need frame annotations during training to be effective. These annotations are very expensive and time-consuming to obtain. This limits their performances when only limited annotated data is available. In contrast, we can easily collect a large corpus of in-domain unannotated videos by scavenging through the internet. Thus, this paper proposes an approach for the temporal action segmentation task that can simultaneously leverage knowledge from annotated and unannotated video sequences. Our approach uses multi-stream distillation that repeatedly refines and finally combines their frame predictions. Our model also predicts the action order, which is later used as a temporal constraint while estimating frames labels to counter the lack of supervision for unannotated videos. In the end, our evaluation of the proposed approach on two different datasets demonstrates its capability to achieve comparable performance to the full supervision despite limited annotation.
Human in the loop approaches in multi-modal conversational task guidance system development
Nov 03, 2022



Development of task guidance systems for aiding humans in a situated task remains a challenging problem. The role of search (information retrieval) and conversational systems for task guidance has immense potential to help the task performers achieve various goals. However, there are several technical challenges that need to be addressed to deliver such conversational systems, where common supervised approaches fail to deliver the expected results in terms of overall performance, user experience and adaptation to realistic conditions. In this preliminary work we first highlight some of the challenges involved during the development of such systems. We then provide an overview of existing datasets available and highlight their limitations. We finally develop a model-in-the-loop wizard-of-oz based data collection tool and perform a pilot experiment.