 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal-to-Global Logical Explanations for Deep Vision Models
Jan 19, 2026While deep neural networks are extremely effective at classifying images, they remain opaque and hard to interpret. We introduce local and global explanation methods for black-box models that generate explanations in terms of human-recognizable primitive concepts. Both the local explanations for a single image and the global explanations for a set of images are cast as logical formulas in monotone disjunctive-normal-form (MDNF), whose satisfaction guarantees that the model yields a high score on a given class. We also present an algorithm for explaining the classification of examples into multiple classes in the form of a monotone explanation list over primitive concepts. Despite their simplicity and interpretability we show that the explanations maintain high fidelity and coverage with respect to the blackbox models they seek to explain in challenging vision datasets.
* 15 pages, 5 figures, 5th International Joint Conference on Learning & Reasoning 2025
Thoughts without Thinking: Reconsidering the Explanatory Value of Chain-of-Thought Reasoning in LLMs through Agentic Pipelines
May 01, 2025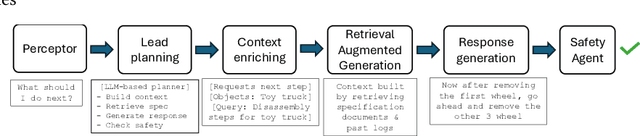



Agentic pipelines present novel challenges and opportunities for human-centered explainability. The HCXAI community is still grappling with how best to make the inner workings of LLMs transparent in actionable ways. Agentic pipelines consist of multiple LLMs working in cooperation with minimal human control. In this research paper, we present early findings from an agentic pipeline implementation of a perceptive task guidance system. Through quantitative and qualitative analysis, we analyze how Chain-of-Thought (CoT) reasoning, a common vehicle for explainability in LLMs, operates within agentic pipelines. We demonstrate that CoT reasoning alone does not lead to better outputs, nor does it offer explainability, as it tends to produce explanations without explainability, in that they do not improve the ability of end users to better understand systems or achieve their goals.
A Beginner's Guide to Power and Energy Measurement and Estimation for Computing and Machine Learning
Dec 11, 2024Concerns about the environmental footprint of machine learning are increasing. While studies of energy use and emissions of ML models are a growing subfield, most ML researchers and developers still do not incorporate energy measurement as part of their work practices. While measuring energy is a crucial step towards reducing carbon footprint, it is also not straightforward. This paper introduces the main considerations necessary for making sound use of energy measurement tools and interpreting energy estimates, including the use of at-the-wall versus on-device measurements, sampling strategies and best practices, common sources of error, and proxy measures. It also contains practical tips and real-world scenarios that illustrate how these considerations come into play. It concludes with a call to action for improving the state of the art of measurement methods and standards for facilitating robust comparisons between diverse hardware and software environments.
QA-TOOLBOX: Conversational Question-Answering for process task guidance in manufacturing
Dec 03, 2024



In this work we explore utilizing LLMs for data augmentation for manufacturing task guidance system. The dataset consists of representative samples of interactions with technicians working in an advanced manufacturing setting. The purpose of this work to explore the task, data augmentation for the supported tasks and evaluating the performance of the existing LLMs. We observe that that task is complex requiring understanding from procedure specification documents, actions and objects sequenced temporally. The dataset consists of 200,000+ question/answer pairs that refer to the spec document and are grounded in narrations and/or video demonstrations. We compared the performance of several popular open-sourced LLMs by developing a baseline using each LLM and then compared the responses in a reference-free setting using LLM-as-a-judge and compared the ratings with crowd-workers whilst validating the ratings with experts.
Human in the loop approaches in multi-modal conversational task guidance system development
Nov 03, 2022



Development of task guidance systems for aiding humans in a situated task remains a challenging problem. The role of search (information retrieval) and conversational systems for task guidance has immense potential to help the task performers achieve various goals. However, there are several technical challenges that need to be addressed to deliver such conversational systems, where common supervised approaches fail to deliver the expected results in terms of overall performance, user experience and adaptation to realistic conditions. In this preliminary work we first highlight some of the challenges involved during the development of such systems. We then provide an overview of existing datasets available and highlight their limitations. We finally develop a model-in-the-loop wizard-of-oz based data collection tool and perform a pilot experiment.
Distill and Collect for Semi-Supervised Temporal Action Segmentation
Nov 03, 2022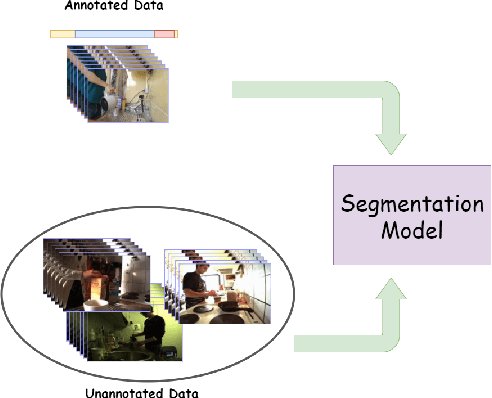
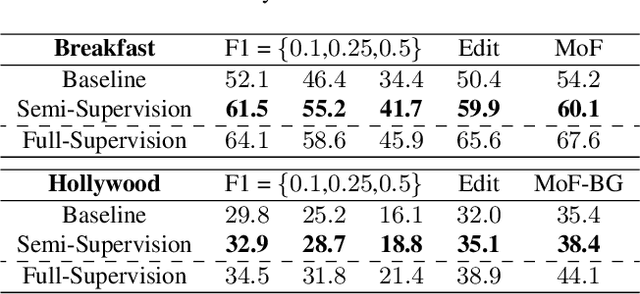
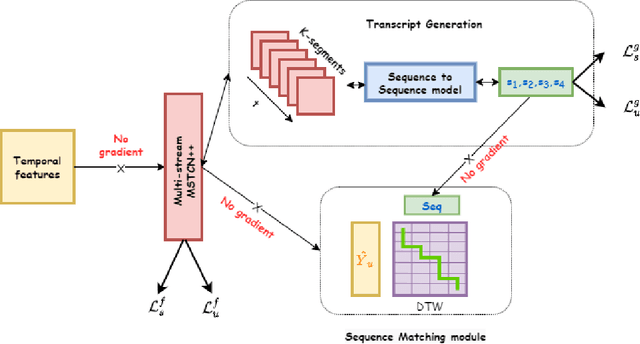

Recent temporal action segmentation approaches need frame annotations during training to be effective. These annotations are very expensive and time-consuming to obtain. This limits their performances when only limited annotated data is available. In contrast, we can easily collect a large corpus of in-domain unannotated videos by scavenging through the internet. Thus, this paper proposes an approach for the temporal action segmentation task that can simultaneously leverage knowledge from annotated and unannotated video sequences. Our approach uses multi-stream distillation that repeatedly refines and finally combines their frame predictions. Our model also predicts the action order, which is later used as a temporal constraint while estimating frames labels to counter the lack of supervision for unannotated videos. In the end, our evaluation of the proposed approach on two different datasets demonstrates its capability to achieve comparable performance to the full supervision despite limited annotation.