 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThoughts without Thinking: Reconsidering the Explanatory Value of Chain-of-Thought Reasoning in LLMs through Agentic Pipelines
May 01, 2025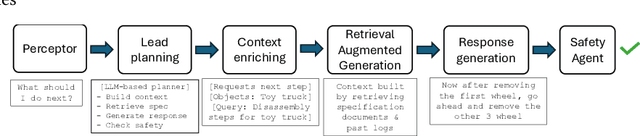



Agentic pipelines present novel challenges and opportunities for human-centered explainability. The HCXAI community is still grappling with how best to make the inner workings of LLMs transparent in actionable ways. Agentic pipelines consist of multiple LLMs working in cooperation with minimal human control. In this research paper, we present early findings from an agentic pipeline implementation of a perceptive task guidance system. Through quantitative and qualitative analysis, we analyze how Chain-of-Thought (CoT) reasoning, a common vehicle for explainability in LLMs, operates within agentic pipelines. We demonstrate that CoT reasoning alone does not lead to better outputs, nor does it offer explainability, as it tends to produce explanations without explainability, in that they do not improve the ability of end users to better understand systems or achieve their goals.
Introducing v0.5 of the AI Safety Benchmark from MLCommons
Apr 18, 2024



This paper introduces v0.5 of the AI Safety Benchmark, which has been created by the MLCommons AI Safety Working Group. The AI Safety Benchmark has been designed to assess the safety risks of AI systems that use chat-tuned language models. We introduce a principled approach to specifying and constructing the benchmark, which for v0.5 covers only a single use case (an adult chatting to a general-purpose assistant in English), and a limited set of personas (i.e., typical users, malicious users, and vulnerable users). We created a new taxonomy of 13 hazard categories, of which 7 have tests in the v0.5 benchmark. We plan to release version 1.0 of the AI Safety Benchmark by the end of 2024. The v1.0 benchmark will provide meaningful insights into the safety of AI systems. However, the v0.5 benchmark should not be used to assess the safety of AI systems. We have sought to fully document the limitations, flaws, and challenges of v0.5. This release of v0.5 of the AI Safety Benchmark includes (1) a principled approach to specifying and constructing the benchmark, which comprises use cases, types of systems under test (SUTs), language and context, personas, tests, and test items; (2) a taxonomy of 13 hazard categories with definitions and subcategories; (3) tests for seven of the hazard categories, each comprising a unique set of test items, i.e., prompts. There are 43,090 test items in total, which we created with templates; (4) a grading system for AI systems against the benchmark; (5) an openly available platform, and downloadable tool, called ModelBench that can be used to evaluate the safety of AI systems on the benchmark; (6) an example evaluation report which benchmarks the performance of over a dozen openly available chat-tuned language models; (7) a test specification for the benchmark.
Humans, AI, and Context: Understanding End-Users' Trust in a Real-World Computer Vision Application
May 15, 2023



Trust is an important factor in people's interactions with AI systems. However, there is a lack of empirical studies examining how real end-users trust or distrust the AI system they interact with. Most research investigates one aspect of trust in lab settings with hypothetical end-users. In this paper, we provide a holistic and nuanced understanding of trust in AI through a qualitative case study of a real-world computer vision application. We report findings from interviews with 20 end-users of a popular, AI-based bird identification app where we inquired about their trust in the app from many angles. We find participants perceived the app as trustworthy and trusted it, but selectively accepted app outputs after engaging in verification behaviors, and decided against app adoption in certain high-stakes scenarios. We also find domain knowledge and context are important factors for trust-related assessment and decision-making. We discuss the implications of our findings and provide recommendations for future research on trust in AI.
"Help Me Help the AI": Understanding How Explainability Can Support Human-AI Interaction
Oct 02, 2022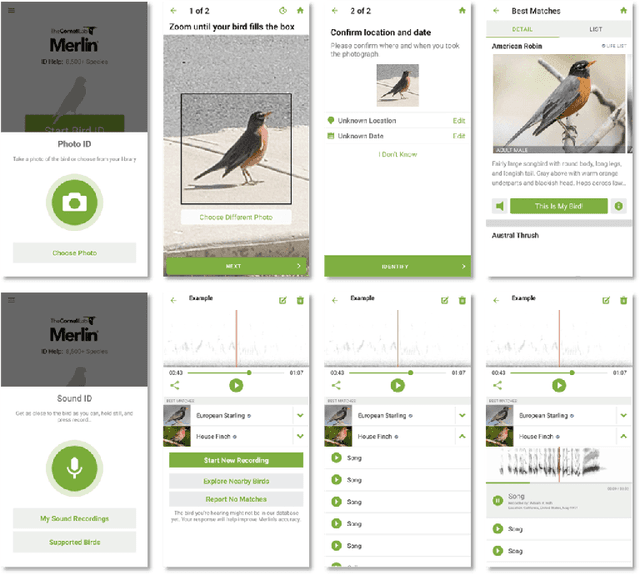

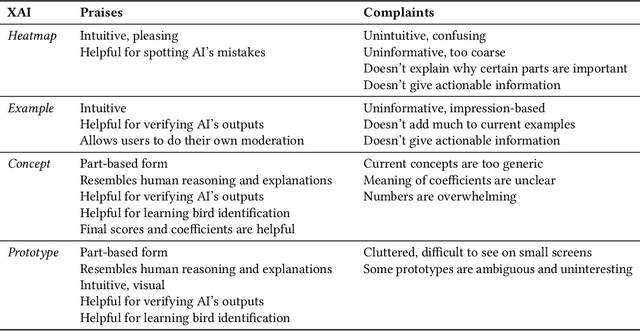
Despite the proliferation of explainable AI (XAI) methods, little is understood about end-users' explainability needs. This gap is critical, because end-users may have needs that XAI methods should but don't yet support. To address this gap and contribute to understanding how explainability can support human-AI interaction, we conducted a study of a real-world AI application via interviews with 20 end-users of Merlin, a bird-identification app. We found that people express a need for practically useful information that can improve their collaboration with the AI system, and intend to use XAI explanations for calibrating trust, improving their task skills, changing their behavior to supply better inputs to the AI system, and giving constructive feedback to developers. We also assessed end-users' perceptions of existing XAI approaches, finding that they prefer part-based explanations. Finally, we discuss implications of our findings and provide recommendations for future designs of XAI, specifically XAI for human-AI collaboration.
The four-fifths rule is not disparate impact: a woeful tale of epistemic trespassing in algorithmic fairness
Feb 19, 2022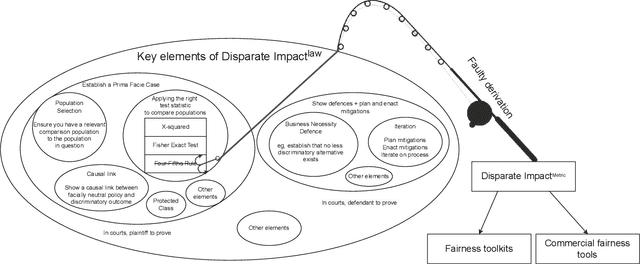


Computer scientists are trained to create abstractions that simplify and generalize. However, a premature abstraction that omits crucial contextual details creates the risk of epistemic trespassing, by falsely asserting its relevance into other contexts. We study how the field of responsible AI has created an imperfect synecdoche by abstracting the four-fifths rule (a.k.a. the 4/5 rule or 80% rule), a single part of disparate impact discrimination law, into the disparate impact metric. This metric incorrectly introduces a new deontic nuance and new potentials for ethical harms that were absent in the original 4/5 rule. We also survey how the field has amplified the potential for harm in codifying the 4/5 rule into popular AI fairness software toolkits. The harmful erasure of legal nuances is a wake-up call for computer scientists to self-critically re-evaluate the abstractions they create and use, particularly in the interdisciplinary field of AI ethics.