 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControlling Context: Generative AI at Work in Integrated Circuit Design and Other High-Precision Domains
Jun 17, 2025Generative AI tools have become more prevalent in engineering workflows, particularly through chatbots and code assistants. As the perceived accuracy of these tools improves, questions arise about whether and how those who work in high-precision domains might maintain vigilance for errors, and what other aspects of using such tools might trouble their work. This paper analyzes interviews with hardware and software engineers, and their collaborators, who work in integrated circuit design to identify the role accuracy plays in their use of generative AI tools and what other forms of trouble they face in using such tools. The paper inventories these forms of trouble, which are then mapped to elements of generative AI systems, to conclude that controlling the context of interactions between engineers and the generative AI tools is one of the largest challenges they face. The paper concludes with recommendations for mitigating this form of trouble by increasing the ability to control context interactively.
Thoughts without Thinking: Reconsidering the Explanatory Value of Chain-of-Thought Reasoning in LLMs through Agentic Pipelines
May 01, 2025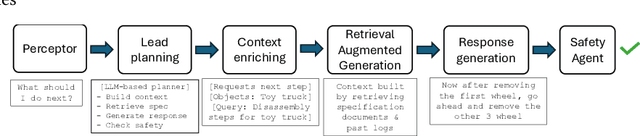



Agentic pipelines present novel challenges and opportunities for human-centered explainability. The HCXAI community is still grappling with how best to make the inner workings of LLMs transparent in actionable ways. Agentic pipelines consist of multiple LLMs working in cooperation with minimal human control. In this research paper, we present early findings from an agentic pipeline implementation of a perceptive task guidance system. Through quantitative and qualitative analysis, we analyze how Chain-of-Thought (CoT) reasoning, a common vehicle for explainability in LLMs, operates within agentic pipelines. We demonstrate that CoT reasoning alone does not lead to better outputs, nor does it offer explainability, as it tends to produce explanations without explainability, in that they do not improve the ability of end users to better understand systems or achieve their goals.
Introducing v0.5 of the AI Safety Benchmark from MLCommons
Apr 18, 2024



This paper introduces v0.5 of the AI Safety Benchmark, which has been created by the MLCommons AI Safety Working Group. The AI Safety Benchmark has been designed to assess the safety risks of AI systems that use chat-tuned language models. We introduce a principled approach to specifying and constructing the benchmark, which for v0.5 covers only a single use case (an adult chatting to a general-purpose assistant in English), and a limited set of personas (i.e., typical users, malicious users, and vulnerable users). We created a new taxonomy of 13 hazard categories, of which 7 have tests in the v0.5 benchmark. We plan to release version 1.0 of the AI Safety Benchmark by the end of 2024. The v1.0 benchmark will provide meaningful insights into the safety of AI systems. However, the v0.5 benchmark should not be used to assess the safety of AI systems. We have sought to fully document the limitations, flaws, and challenges of v0.5. This release of v0.5 of the AI Safety Benchmark includes (1) a principled approach to specifying and constructing the benchmark, which comprises use cases, types of systems under test (SUTs), language and context, personas, tests, and test items; (2) a taxonomy of 13 hazard categories with definitions and subcategories; (3) tests for seven of the hazard categories, each comprising a unique set of test items, i.e., prompts. There are 43,090 test items in total, which we created with templates; (4) a grading system for AI systems against the benchmark; (5) an openly available platform, and downloadable tool, called ModelBench that can be used to evaluate the safety of AI systems on the benchmark; (6) an example evaluation report which benchmarks the performance of over a dozen openly available chat-tuned language models; (7) a test specification for the benchmark.
The Cadaver in the Machine: The Social Practices of Measurement and Validation in Motion Capture Technology
Jan 19, 2024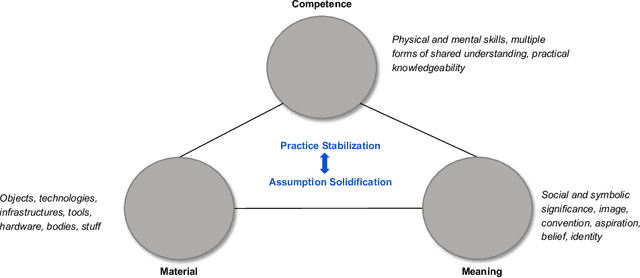
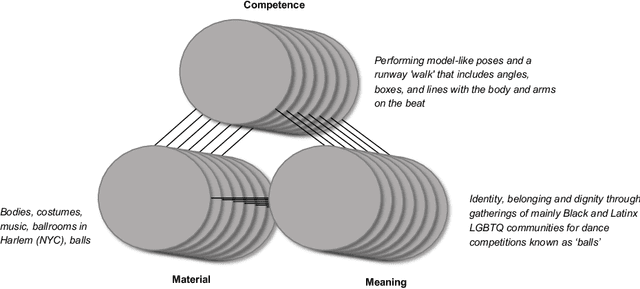

Motion capture systems, used across various domains, make body representations concrete through technical processes. We argue that the measurement of bodies and the validation of measurements for motion capture systems can be understood as social practices. By analyzing the findings of a systematic literature review (N=278) through the lens of social practice theory, we show how these practices, and their varying attention to errors, become ingrained in motion capture design and innovation over time. Moreover, we show how contemporary motion capture systems perpetuate assumptions about human bodies and their movements. We suggest that social practices of measurement and validation are ubiquitous in the development of data- and sensor-driven systems more broadly, and provide this work as a basis for investigating hidden design assumptions and their potential negative consequences in human-computer interaction.
Accountability in an Algorithmic Society: Relationality, Responsibility, and Robustness in Machine Learning
Feb 23, 2022In 1996, philosopher Helen Nissenbaum issued a clarion call concerning the erosion of accountability in society due to the ubiquitous delegation of consequential functions to computerized systems. Using the conceptual framing of moral blame, Nissenbaum described four types of barriers to accountability that computerization presented: 1) "many hands," the problem of attributing moral responsibility for outcomes caused by many moral actors; 2) "bugs," a way software developers might shrug off responsibility by suggesting software errors are unavoidable; 3) "computer as scapegoat," shifting blame to computer systems as if they were moral actors; and 4) "ownership without liability," a free pass to the tech industry to deny responsibility for the software they produce. We revisit these four barriers in relation to the recent ascendance of data-driven algorithmic systems--technology often folded under the heading of machine learning (ML) or artificial intelligence (AI)--to uncover the new challenges for accountability that these systems present. We then look ahead to how one might construct and justify a moral, relational framework for holding responsible parties accountable, and argue that the FAccT community is uniquely well-positioned to develop such a framework to weaken the four barriers.
Participation is not a Design Fix for Machine Learning
Jul 07, 2020This paper critically examines existing modes of participation in design practice and machine learning. Cautioning against 'participation-washing', it suggests that the ML community must become attuned to possibly exploitative and extractive forms of community involvement and shift away from the prerogatives of context-independent scalability.