 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Ensembling For Mitigating Reward Overoptimisation
Jun 03, 2024



Reinforcement Learning from Human Feedback (RLHF) has enabled significant advancements within language modeling for powerful, instruction-following models. However, the alignment of these models remains a pressing challenge as the policy tends to overfit the learned ``proxy" reward model past an inflection point of utility as measured by a ``gold" reward model that is more performant -- a phenomenon known as \textit{over-optimization}. Prior work has mitigated this issue by computing a pessimistic statistic over an ensemble of reward models, which is common in Offline Reinforcement Learning but incredibly costly for language models with high memory requirements, making such approaches infeasible for sufficiently large models. To this end, we propose using a shared encoder but separate linear heads. We find this leads to similar performance as the full ensemble while allowing tremendous savings in memory and time required for training for models of similar size. \end{abstract}
Introducing v0.5 of the AI Safety Benchmark from MLCommons
Apr 18, 2024



This paper introduces v0.5 of the AI Safety Benchmark, which has been created by the MLCommons AI Safety Working Group. The AI Safety Benchmark has been designed to assess the safety risks of AI systems that use chat-tuned language models. We introduce a principled approach to specifying and constructing the benchmark, which for v0.5 covers only a single use case (an adult chatting to a general-purpose assistant in English), and a limited set of personas (i.e., typical users, malicious users, and vulnerable users). We created a new taxonomy of 13 hazard categories, of which 7 have tests in the v0.5 benchmark. We plan to release version 1.0 of the AI Safety Benchmark by the end of 2024. The v1.0 benchmark will provide meaningful insights into the safety of AI systems. However, the v0.5 benchmark should not be used to assess the safety of AI systems. We have sought to fully document the limitations, flaws, and challenges of v0.5. This release of v0.5 of the AI Safety Benchmark includes (1) a principled approach to specifying and constructing the benchmark, which comprises use cases, types of systems under test (SUTs), language and context, personas, tests, and test items; (2) a taxonomy of 13 hazard categories with definitions and subcategories; (3) tests for seven of the hazard categories, each comprising a unique set of test items, i.e., prompts. There are 43,090 test items in total, which we created with templates; (4) a grading system for AI systems against the benchmark; (5) an openly available platform, and downloadable tool, called ModelBench that can be used to evaluate the safety of AI systems on the benchmark; (6) an example evaluation report which benchmarks the performance of over a dozen openly available chat-tuned language models; (7) a test specification for the benchmark.
Self-Improving Robots: End-to-End Autonomous Visuomotor Reinforcement Learning
Mar 02, 2023In imitation and reinforcement learning, the cost of human supervision limits the amount of data that robots can be trained on. An aspirational goal is to construct self-improving robots: robots that can learn and improve on their own, from autonomous interaction with minimal human supervision or oversight. Such robots could collect and train on much larger datasets, and thus learn more robust and performant policies. While reinforcement learning offers a framework for such autonomous learning via trial-and-error, practical realizations end up requiring extensive human supervision for reward function design and repeated resetting of the environment between episodes of interactions. In this work, we propose MEDAL++, a novel design for self-improving robotic systems: given a small set of expert demonstrations at the start, the robot autonomously practices the task by learning to both do and undo the task, simultaneously inferring the reward function from the demonstrations. The policy and reward function are learned end-to-end from high-dimensional visual inputs, bypassing the need for explicit state estimation or task-specific pre-training for visual encoders used in prior work. We first evaluate our proposed algorithm on a simulated non-episodic benchmark EARL, finding that MEDAL++ is both more data efficient and gets up to 30% better final performance compared to state-of-the-art vision-based methods. Our real-robot experiments show that MEDAL++ can be applied to manipulation problems in larger environments than those considered in prior work, and autonomous self-improvement can improve the success rate by 30-70% over behavior cloning on just the expert data. Code, training and evaluation videos along with a brief overview is available at: https://architsharma97.github.io/self-improving-robots/
Cross-Trajectory Representation Learning for Zero-Shot Generalization in RL
Jun 04, 2021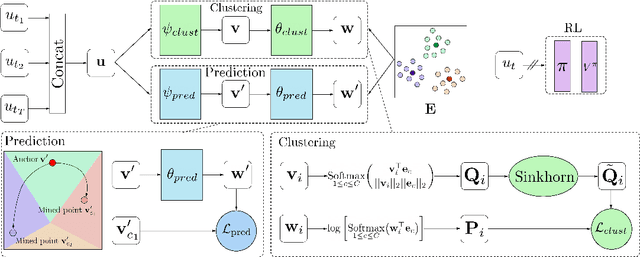
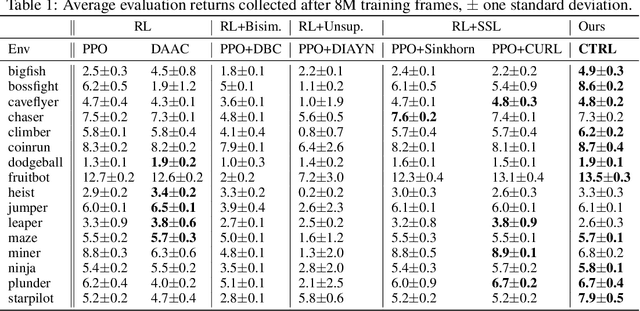
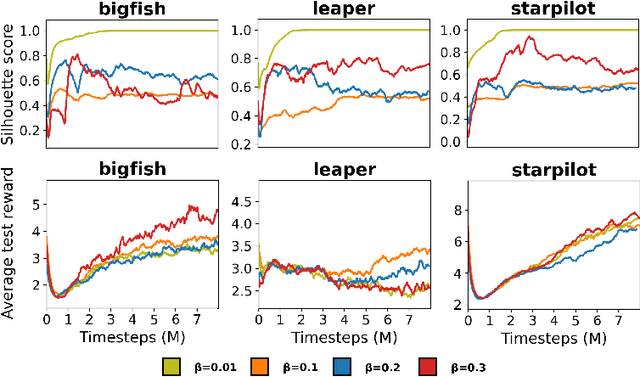

A highly desirable property of a reinforcement learning (RL) agent -- and a major difficulty for deep RL approaches -- is the ability to generalize policies learned on a few tasks over a high-dimensional observation space to similar tasks not seen during training. Many promising approaches to this challenge consider RL as a process of training two functions simultaneously: a complex nonlinear encoder that maps high-dimensional observations to a latent representation space, and a simple linear policy over this space. We posit that a superior encoder for zero-shot generalization in RL can be trained by using solely an auxiliary SSL objective if the training process encourages the encoder to map behaviorally similar observations to similar representations, as reward-based signal can cause overfitting in the encoder (Raileanu et al., 2021). We propose Cross-Trajectory Representation Learning (CTRL), a method that runs within an RL agent and conditions its encoder to recognize behavioral similarity in observations by applying a novel SSL objective to pairs of trajectories from the agent's policies. CTRL can be viewed as having the same effect as inducing a pseudo-bisimulation metric but, crucially, avoids the use of rewards and associated overfitting risks. Our experiments ablate various components of CTRL and demonstrate that in combination with PPO it achieves better generalization performance on the challenging Procgen benchmark suite (Cobbe et al., 2020).