 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Backfiring Effect of Weak AI Safety Regulation
Mar 26, 2025Recent policy proposals aim to improve the safety of general-purpose AI, but there is little understanding of the efficacy of different regulatory approaches to AI safety. We present a strategic model that explores the interactions between the regulator, the general-purpose AI technology creators, and domain specialists--those who adapt the AI for specific applications. Our analysis examines how different regulatory measures, targeting different parts of the development chain, affect the outcome of the development process. In particular, we assume AI technology is described by two key attributes: safety and performance. The regulator first sets a minimum safety standard that applies to one or both players, with strict penalties for non-compliance. The general-purpose creator then develops the technology, establishing its initial safety and performance levels. Next, domain specialists refine the AI for their specific use cases, and the resulting revenue is distributed between the specialist and generalist through an ex-ante bargaining process. Our analysis of this game reveals two key insights: First, weak safety regulation imposed only on the domain specialists can backfire. While it might seem logical to regulate use cases (as opposed to the general-purpose technology), our analysis shows that weak regulations targeting domain specialists alone can unintentionally reduce safety. This effect persists across a wide range of settings. Second, in sharp contrast to the previous finding, we observe that stronger, well-placed regulation can in fact benefit all players subjected to it. When regulators impose appropriate safety standards on both AI creators and domain specialists, the regulation functions as a commitment mechanism, leading to safety and performance gains, surpassing what is achieved under no regulation or regulating one player only.
Fundamental Limits in the Search for Less Discriminatory Algorithms -- and How to Avoid Them
Dec 24, 2024Disparate impact doctrine offers an important legal apparatus for targeting unfair data-driven algorithmic decisions. A recent body of work has focused on conceptualizing and operationalizing one particular construct from this doctrine -- the less discriminatory alternative, an alternative policy that reduces disparities while meeting the same business needs of a status quo or baseline policy. This paper puts forward four fundamental results, which each represent limits to searching for and using less discriminatory algorithms (LDAs). (1) Statistically, although LDAs are almost always identifiable in retrospect on fixed populations, making conclusions about how alternative classifiers perform on an unobserved distribution is more difficult. (2) Mathematically, a classifier can only exhibit certain combinations of accuracy and selection rate disparity between groups, given the size of each group and the base rate of the property or outcome of interest in each group. (3) Computationally, a search for a lower-disparity classifier at some baseline level of utility is NP-hard. (4) From a modeling and consumer welfare perspective, defining an LDA only in terms of business needs can lead to LDAs that leave consumers strictly worse off, including members of the disadvantaged group. These findings, which may seem on their face to give firms strong defenses against discrimination claims, only tell part of the story. For each of our negative results limiting what is attainable in this setting, we offer positive results demonstrating that there exist effective and low-cost strategies that are remarkably effective at identifying viable lower-disparity policies.
Strategic Evaluation: Subjects, Evaluators, and Society
Oct 05, 2023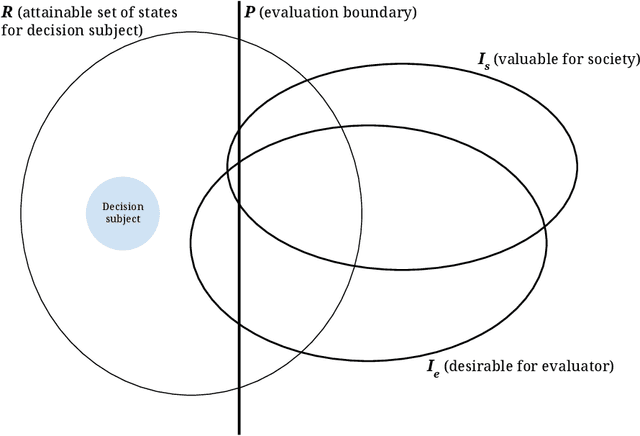
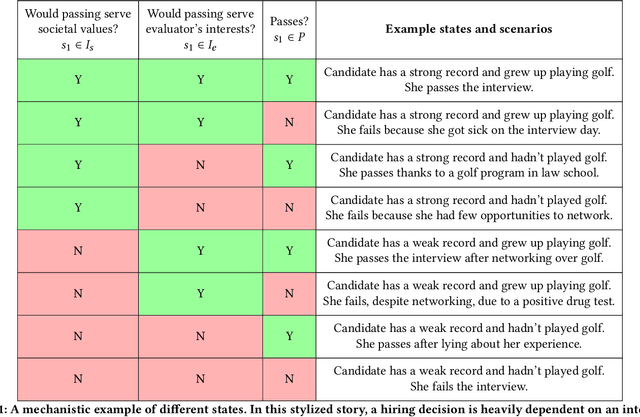
A broad current application of algorithms is in formal and quantitative measures of murky concepts -- like merit -- to make decisions. When people strategically respond to these sorts of evaluations in order to gain favorable decision outcomes, their behavior can be subjected to moral judgments. They may be described as 'gaming the system' or 'cheating,' or (in other cases) investing 'honest effort' or 'improving.' Machine learning literature on strategic behavior has tried to describe these dynamics by emphasizing the efforts expended by decision subjects hoping to obtain a more favorable assessment -- some works offer ways to preempt or prevent such manipulations, some differentiate 'gaming' from 'improvement' behavior, while others aim to measure the effort burden or disparate effects of classification systems. We begin from a different starting point: that the design of an evaluation itself can be understood as furthering goals held by the evaluator which may be misaligned with broader societal goals. To develop the idea that evaluation represents a strategic interaction in which both the evaluator and the subject of their evaluation are operating out of self-interest, we put forward a model that represents the process of evaluation using three interacting agents: a decision subject, an evaluator, and society, representing a bundle of values and oversight mechanisms. We highlight our model's applicability to a number of social systems where one or two players strategically undermine the others' interests to advance their own. Treating evaluators as themselves strategic allows us to re-cast the scrutiny directed at decision subjects, towards the incentives that underpin institutional designs of evaluations. The moral standing of strategic behaviors often depend on the moral standing of the evaluations and incentives that provoke such behaviors.
* 12 pages, 2 figures, EAAMO 2023
Fine-Tuning Games: Bargaining and Adaptation for General-Purpose Models
Aug 11, 2023



Major advances in Machine Learning (ML) and Artificial Intelligence (AI) increasingly take the form of developing and releasing general-purpose models. These models are designed to be adapted by other businesses and agencies to perform a particular, domain-specific function. This process has become known as adaptation or fine-tuning. This paper offers a model of the fine-tuning process where a Generalist brings the technological product (here an ML model) to a certain level of performance, and one or more Domain-specialist(s) adapts it for use in a particular domain. Both entities are profit-seeking and incur costs when they invest in the technology, and they must reach a bargaining agreement on how to share the revenue for the technology to reach the market. For a relatively general class of cost and revenue functions, we characterize the conditions under which the fine-tuning game yields a profit-sharing solution. We observe that any potential domain-specialization will either contribute, free-ride, or abstain in their uptake of the technology, and we provide conditions yielding these different strategies. We show how methods based on bargaining solutions and sub-game perfect equilibria provide insights into the strategic behavior of firms in these types of interactions, and we find that profit-sharing can still arise even when one firm has significantly higher costs than another. We also provide methods for identifying Pareto-optimal bargaining arrangements for a general set of utility functions.
Optimization's Neglected Normative Commitments
May 27, 2023

Optimization is offered as an objective approach to resolving complex, real-world decisions involving uncertainty and conflicting interests. It drives business strategies as well as public policies and, increasingly, lies at the heart of sophisticated machine learning systems. A paradigm used to approach potentially high-stakes decisions, optimization relies on abstracting the real world to a set of decision(s), objective(s) and constraint(s). Drawing from the modeling process and a range of actual cases, this paper describes the normative choices and assumptions that are necessarily part of using optimization. It then identifies six emergent problems that may be neglected: 1) Misspecified values can yield optimizations that omit certain imperatives altogether or incorporate them incorrectly as a constraint or as part of the objective, 2) Problematic decision boundaries can lead to faulty modularity assumptions and feedback loops, 3) Failing to account for multiple agents' divergent goals and decisions can lead to policies that serve only certain narrow interests, 4) Mislabeling and mismeasurement can introduce bias and imprecision, 5) Faulty use of relaxation and approximation methods, unaccompanied by formal characterizations and guarantees, can severely impede applicability, and 6) Treating optimization as a justification for action, without specifying the necessary contextual information, can lead to ethically dubious or faulty decisions. Suggestions are given to further understand and curb the harms that can arise when optimization is used wrongfully.
Collective Obfuscation and Crowdsourcing
Aug 12, 2022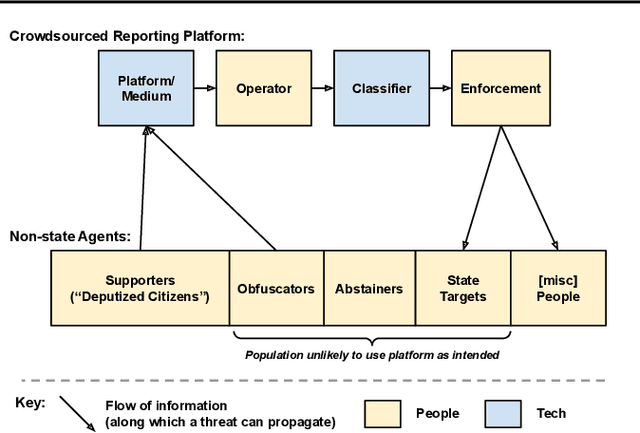


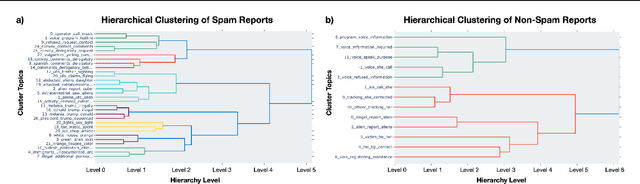
Crowdsourcing technologies rely on groups of people to input information that may be critical for decision-making. This work examines obfuscation in the context of reporting technologies. We show that widespread use of reporting platforms comes with unique security and privacy implications, and introduce a threat model and corresponding taxonomy to outline some of the many attack vectors in this space. We then perform an empirical analysis of a dataset of call logs from a controversial, real-world reporting hotline and identify coordinated obfuscation strategies that are intended to hinder the platform's legitimacy. We propose a variety of statistical measures to quantify the strength of this obfuscation strategy with respect to the structural and semantic characteristics of the reporting attacks in our dataset.
Accountability in an Algorithmic Society: Relationality, Responsibility, and Robustness in Machine Learning
Feb 23, 2022In 1996, philosopher Helen Nissenbaum issued a clarion call concerning the erosion of accountability in society due to the ubiquitous delegation of consequential functions to computerized systems. Using the conceptual framing of moral blame, Nissenbaum described four types of barriers to accountability that computerization presented: 1) "many hands," the problem of attributing moral responsibility for outcomes caused by many moral actors; 2) "bugs," a way software developers might shrug off responsibility by suggesting software errors are unavoidable; 3) "computer as scapegoat," shifting blame to computer systems as if they were moral actors; and 4) "ownership without liability," a free pass to the tech industry to deny responsibility for the software they produce. We revisit these four barriers in relation to the recent ascendance of data-driven algorithmic systems--technology often folded under the heading of machine learning (ML) or artificial intelligence (AI)--to uncover the new challenges for accountability that these systems present. We then look ahead to how one might construct and justify a moral, relational framework for holding responsible parties accountable, and argue that the FAccT community is uniquely well-positioned to develop such a framework to weaken the four barriers.
Feedback Effects in Repeat-Use Criminal Risk Assessments
Nov 28, 2020
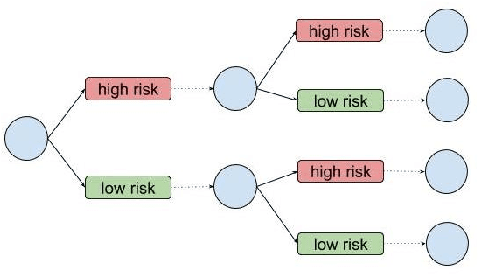
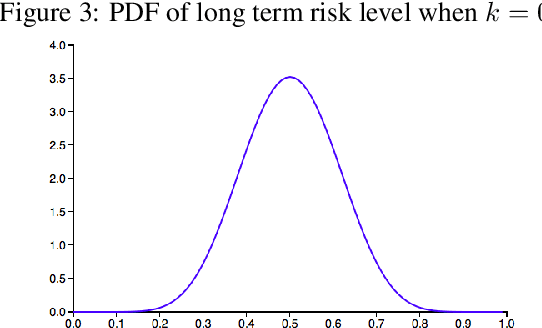
In the criminal legal context, risk assessment algorithms are touted as data-driven, well-tested tools. Studies known as validation tests are typically cited by practitioners to show that a particular risk assessment algorithm has predictive accuracy, establishes legitimate differences between risk groups, and maintains some measure of group fairness in treatment. To establish these important goals, most tests use a one-shot, single-point measurement. Using a Polya Urn model, we explore the implication of feedback effects in sequential scoring-decision processes. We show through simulation that risk can propagate over sequential decisions in ways that are not captured by one-shot tests. For example, even a very small or undetectable level of bias in risk allocation can amplify over sequential risk-based decisions, leading to observable group differences after a number of decision iterations. Risk assessment tools operate in a highly complex and path-dependent process, fraught with historical inequity. We conclude from this study that these tools do not properly account for compounding effects, and require new approaches to development and auditing.