 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResponsible Emergent Multi-Agent Behavior
Nov 02, 2023Responsible AI has risen to the forefront of the AI research community. As neural network-based learning algorithms continue to permeate real-world applications, the field of Responsible AI has played a large role in ensuring that such systems maintain a high-level of human-compatibility. Despite this progress, the state of the art in Responsible AI has ignored one crucial point: human problems are multi-agent problems. Predominant approaches largely consider the performance of a single AI system in isolation, but human problems are, by their very nature, multi-agent. From driving in traffic to negotiating economic policy, human problem-solving involves interaction and the interplay of the actions and motives of multiple individuals. This dissertation develops the study of responsible emergent multi-agent behavior, illustrating how researchers and practitioners can better understand and shape multi-agent learning with respect to three pillars of Responsible AI: interpretability, fairness, and robustness. First, I investigate multi-agent interpretability, presenting novel techniques for understanding emergent multi-agent behavior at multiple levels of granularity. With respect to low-level interpretability, I examine the extent to which implicit communication emerges as an aid to coordination in multi-agent populations. I introduce a novel curriculum-driven method for learning high-performing policies in difficult, sparse reward environments and show through a measure of position-based social influence that multi-agent teams that learn sophisticated coordination strategies exchange significantly more information through implicit signals than lesser-coordinated agents. Then, at a high-level, I study concept-based interpretability in the context of multi-agent learning. I propose a novel method for learning intrinsically interpretable, concept-based policies and show that it enables...
Policy-Value Alignment and Robustness in Search-based Multi-Agent Learning
Feb 06, 2023Large-scale AI systems that combine search and learning have reached super-human levels of performance in game-playing, but have also been shown to fail in surprising ways. The brittleness of such models limits their efficacy and trustworthiness in real-world deployments. In this work, we systematically study one such algorithm, AlphaZero, and identify two phenomena related to the nature of exploration. First, we find evidence of policy-value misalignment -- for many states, AlphaZero's policy and value predictions contradict each other, revealing a tension between accurate move-selection and value estimation in AlphaZero's objective. Further, we find inconsistency within AlphaZero's value function, which causes it to generalize poorly, despite its policy playing an optimal strategy. From these insights we derive VISA-VIS: a novel method that improves policy-value alignment and value robustness in AlphaZero. Experimentally, we show that our method reduces policy-value misalignment by up to 76%, reduces value generalization error by up to 50%, and reduces average value error by up to 55%.
Collective Obfuscation and Crowdsourcing
Aug 12, 2022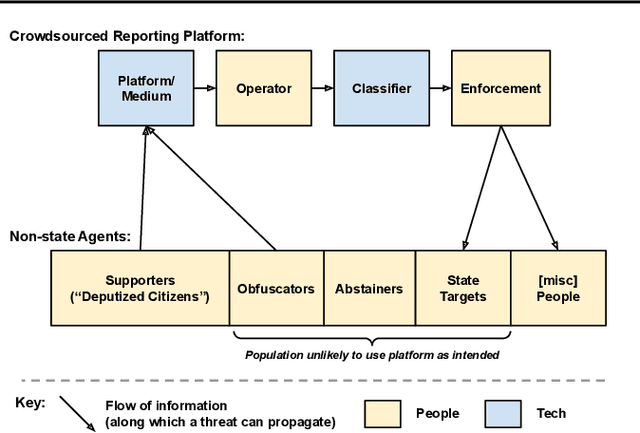


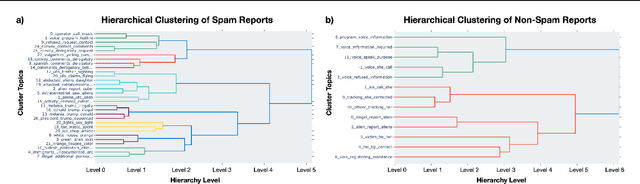
Crowdsourcing technologies rely on groups of people to input information that may be critical for decision-making. This work examines obfuscation in the context of reporting technologies. We show that widespread use of reporting platforms comes with unique security and privacy implications, and introduce a threat model and corresponding taxonomy to outline some of the many attack vectors in this space. We then perform an empirical analysis of a dataset of call logs from a controversial, real-world reporting hotline and identify coordinated obfuscation strategies that are intended to hinder the platform's legitimacy. We propose a variety of statistical measures to quantify the strength of this obfuscation strategy with respect to the structural and semantic characteristics of the reporting attacks in our dataset.
Curriculum-Driven Multi-Agent Learning and the Role of Implicit Communication in Teamwork
Jun 21, 2021

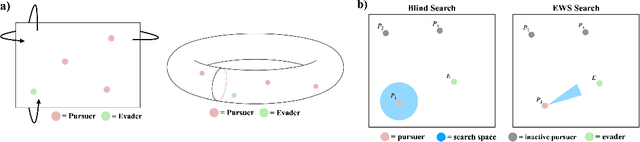
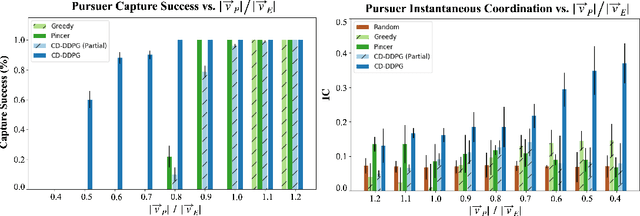
We propose a curriculum-driven learning strategy for solving difficult multi-agent coordination tasks. Our method is inspired by a study of animal communication, which shows that two straightforward design features (mutual reward and decentralization) support a vast spectrum of communication protocols in nature. We highlight the importance of similarly interpreting emergent communication as a spectrum. We introduce a toroidal, continuous-space pursuit-evasion environment and show that naive decentralized learning does not perform well. We then propose a novel curriculum-driven strategy for multi-agent learning. Experiments with pursuit-evasion show that our approach enables decentralized pursuers to learn to coordinate and capture a superior evader, significantly outperforming sophisticated analytical policies. We argue through additional quantitative analysis -- including influence-based measures such as Instantaneous Coordination -- that emergent implicit communication plays a large role in enabling superior levels of coordination.
Fairness for Cooperative Multi-Agent Learning with Equivariant Policies
Jun 10, 2021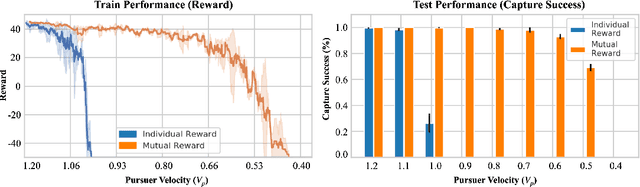
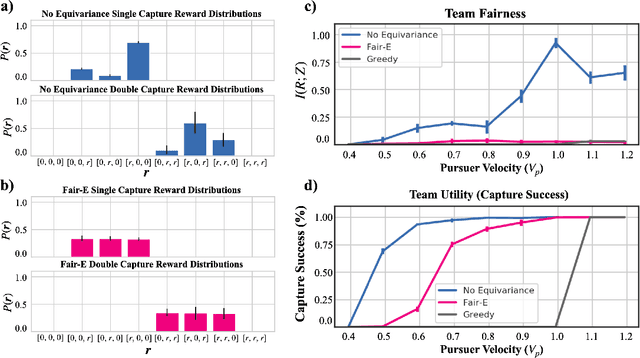
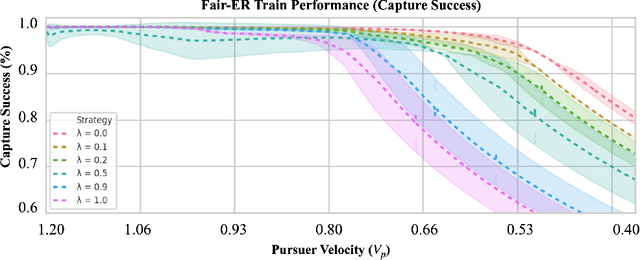
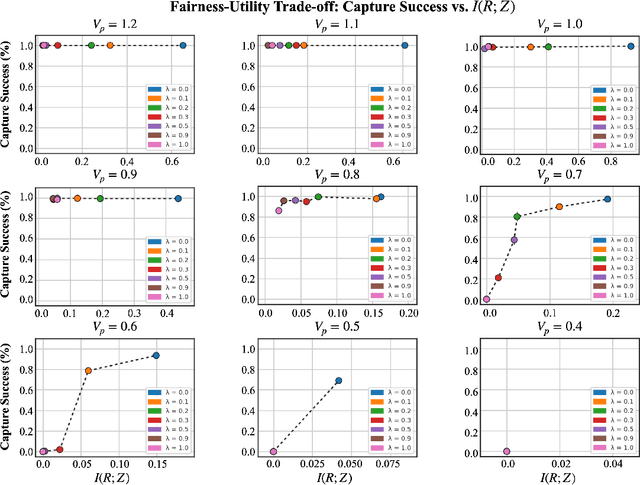
We study fairness through the lens of cooperative multi-agent learning. Our work is motivated by empirical evidence that naive maximization of team reward yields unfair outcomes for individual team members. To address fairness in multi-agent contexts, we introduce team fairness, a group-based fairness measure for multi-agent learning. We then incorporate team fairness into policy optimization -- introducing Fairness through Equivariance (Fair-E), a novel learning strategy that achieves provably fair reward distributions. We then introduce Fairness through Equivariance Regularization (Fair-ER) as a soft-constraint version of Fair-E and show that Fair-ER reaches higher levels of utility than Fair-E and fairer outcomes than policies with no equivariance. Finally, we investigate the fairness-utility trade-off in multi-agent settings.
Low-Bandwidth Communication Emerges Naturally in Multi-Agent Learning Systems
Dec 08, 2020
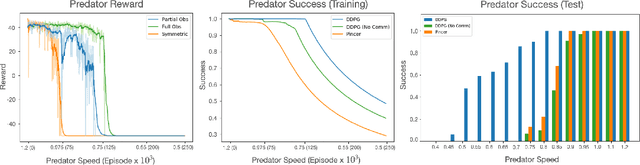
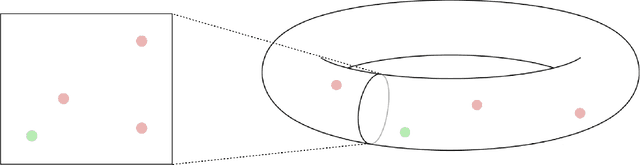
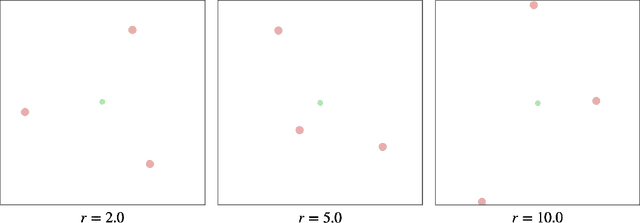
In this work, we study emergent communication through the lens of cooperative multi-agent behavior in nature. Using insights from animal communication, we propose a spectrum from low-bandwidth (e.g. pheromone trails) to high-bandwidth (e.g. compositional language) communication that is based on the cognitive, perceptual, and behavioral capabilities of social agents. Through a series of experiments with pursuit-evasion games, we identify multi-agent reinforcement learning algorithms as a computational model for the low-bandwidth end of the communication spectrum.