 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Bad NOFO? AI Governance in Federal Grantmaking
May 13, 2025Much scholarship considers how U.S. federal agencies govern artificial intelligence (AI) through rulemaking and their own internal use policies. But agencies have an overlooked AI governance role: setting discretionary grant policy when directing billions of dollars in federal financial assistance. These dollars enable state and local entities to study, create, and use AI. This funding not only goes to dedicated AI programs, but also to grantees using AI in the course of meeting their routine grant objectives. As discretionary grantmakers, agencies guide and restrict what grant winners do -- a hidden lever for AI governance. Agencies pull this lever by setting program objectives, judging criteria, and restrictions for AI use. Using a novel dataset of over 40,000 non-defense federal grant notices of funding opportunity (NOFOs) posted to Grants.gov between 2009 and 2024, we analyze how agencies regulate the use of AI by grantees. We select records mentioning AI and review their stated goals and requirements. We find agencies promoting AI in notice narratives, shaping adoption in ways other records of grant policy might fail to capture. Of the grant opportunities that mention AI, we find only a handful of AI-specific judging criteria or restrictions. This silence holds even when agencies fund AI uses in contexts affecting people's rights and which, under an analogous federal procurement regime, would result in extra oversight. These findings recast grant notices as a site of AI policymaking -- albeit one that is developing out of step with other regulatory efforts and incomplete in its consideration of transparency, accountability, and privacy protections. The paper concludes by drawing lessons from AI procurement scholarship, while identifying distinct challenges in grantmaking that invite further study.
* In The 2025 ACM Conference on Fairness, Accountability, and Transparency (FAccT '25), June 23---26, 2025, Athens, Greece. 13 pages
Participation in the age of foundation models
May 29, 2024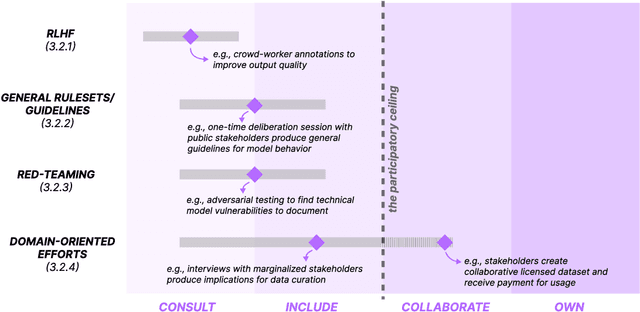
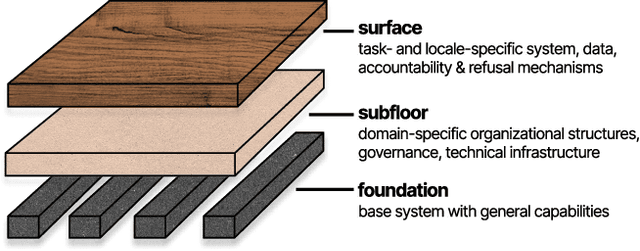
Growing interest and investment in the capabilities of foundation models has positioned such systems to impact a wide array of public services. Alongside these opportunities is the risk that these systems reify existing power imbalances and cause disproportionate harm to marginalized communities. Participatory approaches hold promise to instead lend agency and decision-making power to marginalized stakeholders. But existing approaches in participatory AI/ML are typically deeply grounded in context - how do we apply these approaches to foundation models, which are, by design, disconnected from context? Our paper interrogates this question. First, we examine existing attempts at incorporating participation into foundation models. We highlight the tension between participation and scale, demonstrating that it is intractable for impacted communities to meaningfully shape a foundation model that is intended to be universally applicable. In response, we develop a blueprint for participatory foundation models that identifies more local, application-oriented opportunities for meaningful participation. In addition to the "foundation" layer, our framework proposes the "subfloor'' layer, in which stakeholders develop shared technical infrastructure, norms and governance for a grounded domain, and the "surface'' layer, in which affected communities shape the use of a foundation model for a specific downstream task. The intermediate "subfloor'' layer scopes the range of potential harms to consider, and affords communities more concrete avenues for deliberation and intervention. At the same time, it avoids duplicative effort by scaling input across relevant use cases. Through three case studies in clinical care, financial services, and journalism, we illustrate how this multi-layer model can create more meaningful opportunities for participation than solely intervening at the foundation layer.
* 13 pages, 2 figures. Appeared at FAccT '24
Strategic Evaluation: Subjects, Evaluators, and Society
Oct 05, 2023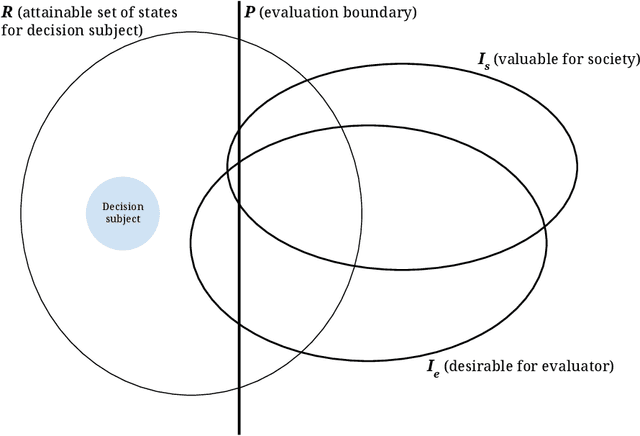
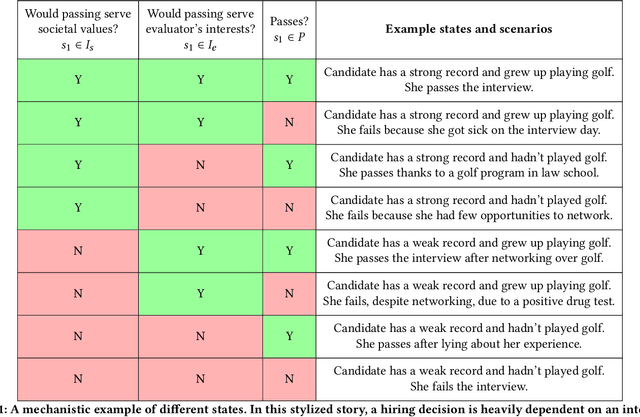
A broad current application of algorithms is in formal and quantitative measures of murky concepts -- like merit -- to make decisions. When people strategically respond to these sorts of evaluations in order to gain favorable decision outcomes, their behavior can be subjected to moral judgments. They may be described as 'gaming the system' or 'cheating,' or (in other cases) investing 'honest effort' or 'improving.' Machine learning literature on strategic behavior has tried to describe these dynamics by emphasizing the efforts expended by decision subjects hoping to obtain a more favorable assessment -- some works offer ways to preempt or prevent such manipulations, some differentiate 'gaming' from 'improvement' behavior, while others aim to measure the effort burden or disparate effects of classification systems. We begin from a different starting point: that the design of an evaluation itself can be understood as furthering goals held by the evaluator which may be misaligned with broader societal goals. To develop the idea that evaluation represents a strategic interaction in which both the evaluator and the subject of their evaluation are operating out of self-interest, we put forward a model that represents the process of evaluation using three interacting agents: a decision subject, an evaluator, and society, representing a bundle of values and oversight mechanisms. We highlight our model's applicability to a number of social systems where one or two players strategically undermine the others' interests to advance their own. Treating evaluators as themselves strategic allows us to re-cast the scrutiny directed at decision subjects, towards the incentives that underpin institutional designs of evaluations. The moral standing of strategic behaviors often depend on the moral standing of the evaluations and incentives that provoke such behaviors.
* 12 pages, 2 figures, EAAMO 2023
On the Actionability of Outcome Prediction
Sep 08, 2023
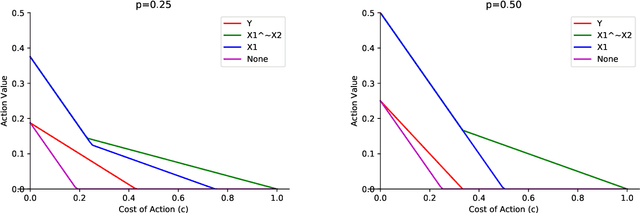

Predicting future outcomes is a prevalent application of machine learning in social impact domains. Examples range from predicting student success in education to predicting disease risk in healthcare. Practitioners recognize that the ultimate goal is not just to predict but to act effectively. Increasing evidence suggests that relying on outcome predictions for downstream interventions may not have desired results. In most domains there exists a multitude of possible interventions for each individual, making the challenge of taking effective action more acute. Even when causal mechanisms connecting the individual's latent states to outcomes is well understood, in any given instance (a specific student or patient), practitioners still need to infer -- from budgeted measurements of latent states -- which of many possible interventions will be most effective for this individual. With this in mind, we ask: when are accurate predictors of outcomes helpful for identifying the most suitable intervention? Through a simple model encompassing actions, latent states, and measurements, we demonstrate that pure outcome prediction rarely results in the most effective policy for taking actions, even when combined with other measurements. We find that except in cases where there is a single decisive action for improving the outcome, outcome prediction never maximizes "action value", the utility of taking actions. Making measurements of actionable latent states, where specific actions lead to desired outcomes, considerably enhances the action value compared to outcome prediction, and the degree of improvement depends on action costs and the outcome model. This analysis emphasizes the need to go beyond generic outcome prediction in interventional settings by incorporating knowledge of plausible actions and latent states.
Informational Diversity and Affinity Bias in Team Growth Dynamics
Jan 28, 2023



Prior work has provided strong evidence that, within organizational settings, teams that bring a diversity of information and perspectives to a task are more effective than teams that do not. If this form of informational diversity confers performance advantages, why do we often see largely homogeneous teams in practice? One canonical argument is that the benefits of informational diversity are in tension with affinity bias. To better understand the impact of this tension on the makeup of teams, we analyze a sequential model of team formation in which individuals care about their team's performance (captured in terms of accurately predicting some future outcome based on a set of features) but experience a cost as a result of interacting with teammates who use different approaches to the prediction task. Our analysis of this simple model reveals a set of subtle behaviors that team-growth dynamics can exhibit: (i) from certain initial team compositions, they can make progress toward better performance but then get stuck partway to optimally diverse teams; while (ii) from other initial compositions, they can also move away from this optimal balance as the majority group tries to crowd out the opinions of the minority. The initial composition of the team can determine whether the dynamics will move toward or away from performance optimality, painting a path-dependent picture of inefficiencies in team compositions. Our results formalize a fundamental limitation of utility-based motivations to drive informational diversity in organizations and hint at interventions that may improve informational diversity and performance simultaneously.
Proactive Moderation of Online Discussions: Existing Practices and the Potential for Algorithmic Support
Nov 29, 2022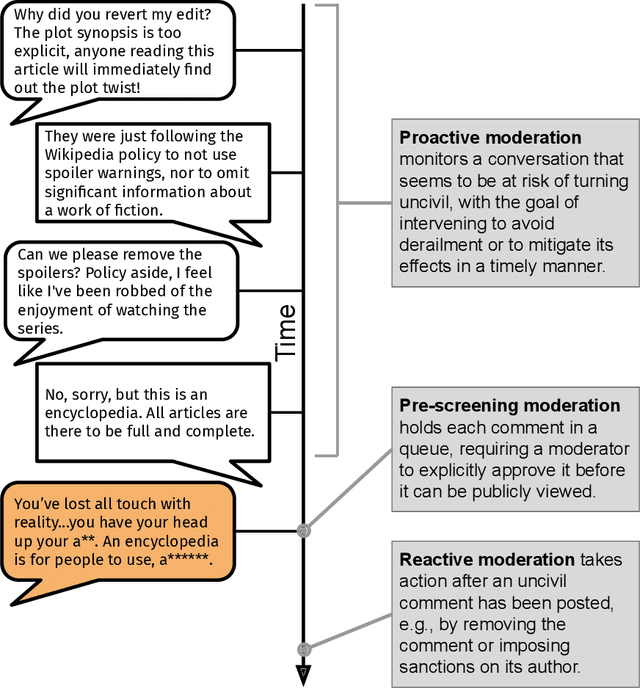
To address the widespread problem of uncivil behavior, many online discussion platforms employ human moderators to take action against objectionable content, such as removing it or placing sanctions on its authors. This reactive paradigm of taking action against already-posted antisocial content is currently the most common form of moderation, and has accordingly underpinned many recent efforts at introducing automation into the moderation process. Comparatively less work has been done to understand other moderation paradigms -- such as proactively discouraging the emergence of antisocial behavior rather than reacting to it -- and the role algorithmic support can play in these paradigms. In this work, we investigate such a proactive framework for moderation in a case study of a collaborative setting: Wikipedia Talk Pages. We employ a mixed methods approach, combining qualitative and design components for a holistic analysis. Through interviews with moderators, we find that despite a lack of technical and social support, moderators already engage in a number of proactive moderation behaviors, such as preemptively intervening in conversations to keep them on track. Further, we explore how automation could assist with this existing proactive moderation workflow by building a prototype tool, presenting it to moderators, and examining how the assistance it provides might fit into their workflow. The resulting feedback uncovers both strengths and drawbacks of the prototype tool and suggests concrete steps towards further developing such assisting technology so it can most effectively support moderators in their existing proactive moderation workflow.
* 27 pages, 3 figures. More info at https://www.cs.cornell.edu/~cristian/Proactive_Moderation.html
Gathering Strength, Gathering Storms: The One Hundred Year Study on Artificial Intelligence (AI100) 2021 Study Panel Report
Oct 27, 2022In September 2021, the "One Hundred Year Study on Artificial Intelligence" project (AI100) issued the second report of its planned long-term periodic assessment of artificial intelligence (AI) and its impact on society. It was written by a panel of 17 study authors, each of whom is deeply rooted in AI research, chaired by Michael Littman of Brown University. The report, entitled "Gathering Strength, Gathering Storms," answers a set of 14 questions probing critical areas of AI development addressing the major risks and dangers of AI, its effects on society, its public perception and the future of the field. The report concludes that AI has made a major leap from the lab to people's lives in recent years, which increases the urgency to understand its potential negative effects. The questions were developed by the AI100 Standing Committee, chaired by Peter Stone of the University of Texas at Austin, consisting of a group of AI leaders with expertise in computer science, sociology, ethics, economics, and other disciplines.
An Uncommon Task: Participatory Design in Legal AI
Mar 08, 2022Despite growing calls for participation in AI design, there are to date few empirical studies of what these processes look like and how they can be structured for meaningful engagement with domain experts. In this paper, we examine a notable yet understudied AI design process in the legal domain that took place over a decade ago, the impact of which still informs legal automation efforts today. Specifically, we examine the design and evaluation activities that took place from 2006 to 2011 within the TeXT Retrieval Conference's (TREC) Legal Track, a computational research venue hosted by the National Institute of Standards and Technologies. The Legal Track of TREC is notable in the history of AI research and practice because it relied on a range of participatory approaches to facilitate the design and evaluation of new computational techniques--in this case, for automating attorney document review for civil litigation matters. Drawing on archival research and interviews with coordinators of the Legal Track of TREC, our analysis reveals how an interactive simulation methodology allowed computer scientists and lawyers to become co-designers and helped bridge the chasm between computational research and real-world, high-stakes litigation practice. In analyzing this case from the recent past, our aim is to empirically ground contemporary critiques of AI development and evaluation and the calls for greater participation as a means to address them.
Computer Vision and Conflicting Values: Describing People with Automated Alt Text
May 26, 2021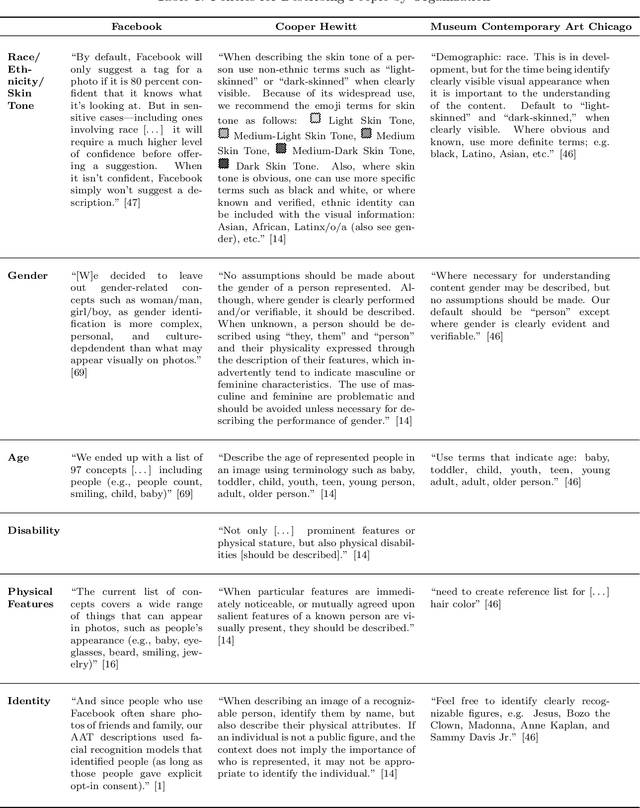
Scholars have recently drawn attention to a range of controversial issues posed by the use of computer vision for automatically generating descriptions of people in images. Despite these concerns, automated image description has become an important tool to ensure equitable access to information for blind and low vision people. In this paper, we investigate the ethical dilemmas faced by companies that have adopted the use of computer vision for producing alt text: textual descriptions of images for blind and low vision people, We use Facebook's automatic alt text tool as our primary case study. First, we analyze the policies that Facebook has adopted with respect to identity categories, such as race, gender, age, etc., and the company's decisions about whether to present these terms in alt text. We then describe an alternative -- and manual -- approach practiced in the museum community, focusing on how museums determine what to include in alt text descriptions of cultural artifacts. We compare these policies, using notable points of contrast to develop an analytic framework that characterizes the particular apprehensions behind these policy choices. We conclude by considering two strategies that seem to sidestep some of these concerns, finding that there are no easy ways to avoid the normative dilemmas posed by the use of computer vision to automate alt text.
Artificial intelligence in communication impacts language and social relationships
Feb 10, 2021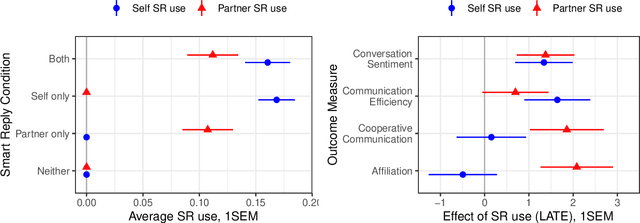
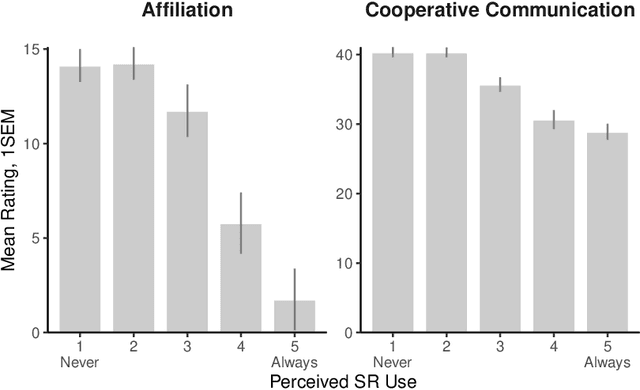
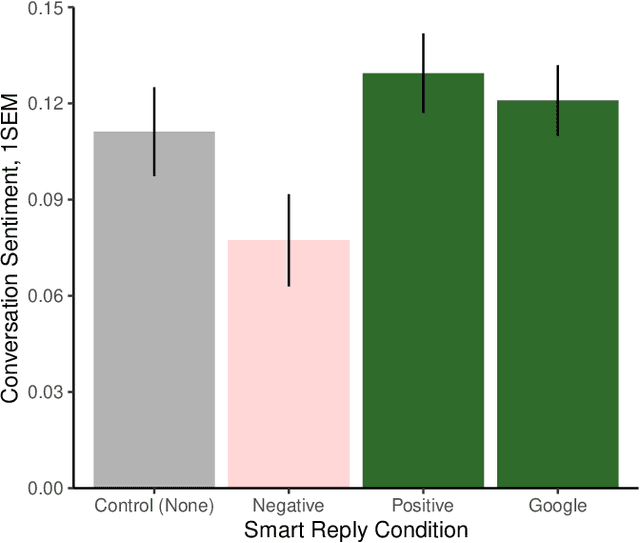
Artificial intelligence (AI) is now widely used to facilitate social interaction, but its impact on social relationships and communication is not well understood. We study the social consequences of one of the most pervasive AI applications: algorithmic response suggestions ("smart replies"). Two randomized experiments (n = 1036) provide evidence that a commercially-deployed AI changes how people interact with and perceive one another in pro-social and anti-social ways. We find that using algorithmic responses increases communication efficiency, use of positive emotional language, and positive evaluations by communication partners. However, consistent with common assumptions about the negative implications of AI, people are evaluated more negatively if they are suspected to be using algorithmic responses. Thus, even though AI can increase communication efficiency and improve interpersonal perceptions, it risks changing users' language production and continues to be viewed negatively.