 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Data Governance for Brain Foundation Models
Jan 23, 2026Brain foundation models bring the foundation model paradigm to the field of neuroscience. Like language and image foundation models, they are general-purpose AI systems pretrained on large-scale datasets that adapt readily to downstream tasks. Unlike text-and-image based models, however, they train on brain data: large-datasets of EEG, fMRI, and other neural data types historically collected within tightly governed clinical and research settings. This paper contends that training foundation models on neural data opens new normative territory. Neural data carry stronger expectations of, and claims to, protection than text or images, given their body-derived nature and historical governance within clinical and research settings. Yet the foundation model paradigm subjects them to practices of large-scale repurposing, cross-context stitching, and open-ended downstream application. Furthermore, these practices are now accessible to a much broader range of actors, including commercial developers, against a backdrop of fragmented and unclear governance. To map this territory, we first describe brain foundation models' technical foundations and training-data ecosystem. We then draw on AI ethics, neuroethics, and bioethics to organize concerns across privacy, consent, bias, benefit sharing, and governance. For each, we propose both agenda-setting questions and baseline safeguards as the field matures.
Computer Vision and Conflicting Values: Describing People with Automated Alt Text
May 26, 2021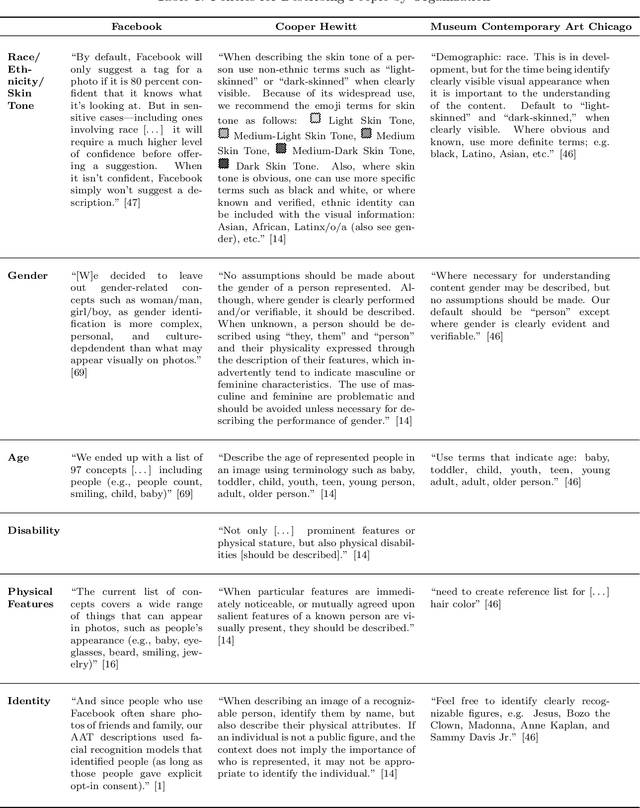
Scholars have recently drawn attention to a range of controversial issues posed by the use of computer vision for automatically generating descriptions of people in images. Despite these concerns, automated image description has become an important tool to ensure equitable access to information for blind and low vision people. In this paper, we investigate the ethical dilemmas faced by companies that have adopted the use of computer vision for producing alt text: textual descriptions of images for blind and low vision people, We use Facebook's automatic alt text tool as our primary case study. First, we analyze the policies that Facebook has adopted with respect to identity categories, such as race, gender, age, etc., and the company's decisions about whether to present these terms in alt text. We then describe an alternative -- and manual -- approach practiced in the museum community, focusing on how museums determine what to include in alt text descriptions of cultural artifacts. We compare these policies, using notable points of contrast to develop an analytic framework that characterizes the particular apprehensions behind these policy choices. We conclude by considering two strategies that seem to sidestep some of these concerns, finding that there are no easy ways to avoid the normative dilemmas posed by the use of computer vision to automate alt text.
An Ethical Highlighter for People-Centric Dataset Creation
Nov 27, 2020Important ethical concerns arising from computer vision datasets of people have been receiving significant attention, and a number of datasets have been withdrawn as a result. To meet the academic need for people-centric datasets, we propose an analytical framework to guide ethical evaluation of existing datasets and to serve future dataset creators in avoiding missteps. Our work is informed by a review and analysis of prior works and highlights where such ethical challenges arise.