 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Do Language Models Compose Functions?
Oct 02, 2025While large language models (LLMs) appear to be increasingly capable of solving compositional tasks, it is an open question whether they do so using compositional mechanisms. In this work, we investigate how feedforward LLMs solve two-hop factual recall tasks, which can be expressed compositionally as $g(f(x))$. We first confirm that modern LLMs continue to suffer from the "compositionality gap": i.e. their ability to compute both $z = f(x)$ and $y = g(z)$ does not entail their ability to compute the composition $y = g(f(x))$. Then, using logit lens on their residual stream activations, we identify two processing mechanisms, one which solves tasks $\textit{compositionally}$, computing $f(x)$ along the way to computing $g(f(x))$, and one which solves them $\textit{directly}$, without any detectable signature of the intermediate variable $f(x)$. Finally, we find that which mechanism is employed appears to be related to the embedding space geometry, with the idiomatic mechanism being dominant in cases where there exists a linear mapping from $x$ to $g(f(x))$ in the embedding spaces. We fully release our data and code at: https://github.com/apoorvkh/composing-functions .
$100K or 100 Days: Trade-offs when Pre-Training with Academic Resources
Oct 30, 2024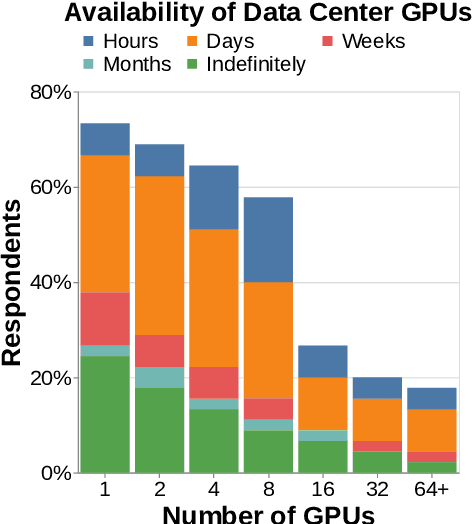
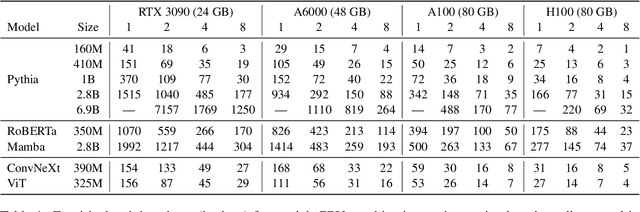
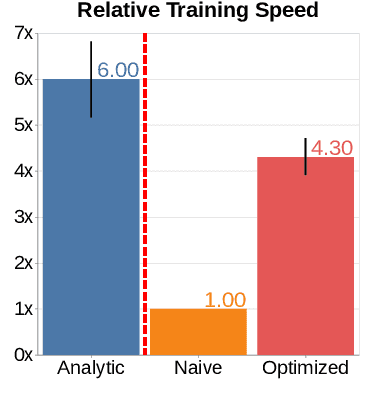
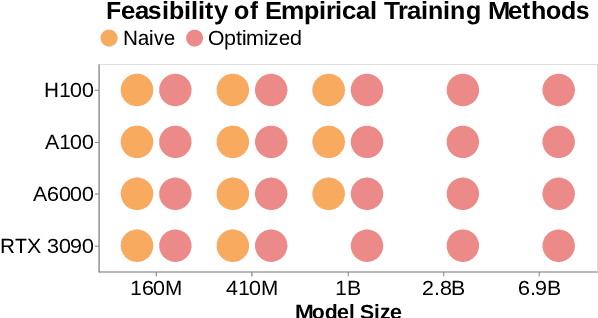
Pre-training is notoriously compute-intensive and academic researchers are notoriously under-resourced. It is, therefore, commonly assumed that academics can't pre-train models. In this paper, we seek to clarify this assumption. We first survey academic researchers to learn about their available compute and then empirically measure the time to replicate models on such resources. We introduce a benchmark to measure the time to pre-train models on given GPUs and also identify ideal settings for maximizing training speed. We run our benchmark on a range of models and academic GPUs, spending 2,000 GPU-hours on our experiments. Our results reveal a brighter picture for academic pre-training: for example, although Pythia-1B was originally trained on 64 GPUs for 3 days, we find it is also possible to replicate this model (with the same hyper-parameters) in 3x fewer GPU-days: i.e. on 4 GPUs in 18 days. We conclude with a cost-benefit analysis to help clarify the trade-offs between price and pre-training time. We believe our benchmark will help academic researchers conduct experiments that require training larger models on more data. We fully release our codebase at: https://github.com/apoorvkh/academic-pretraining.
Analyzing Modular Approaches for Visual Question Decomposition
Nov 10, 2023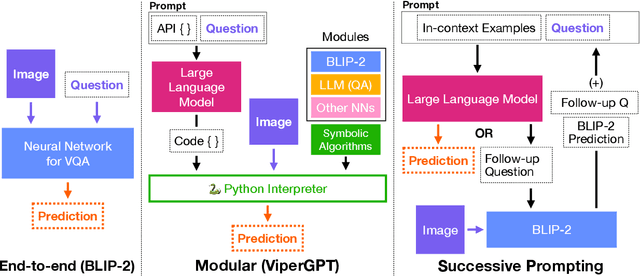
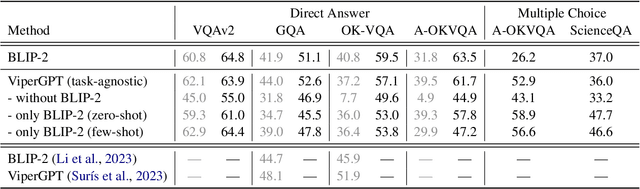

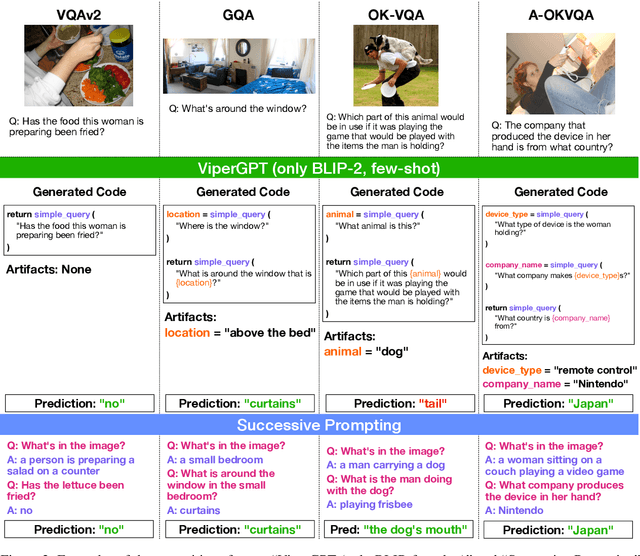
Modular neural networks without additional training have recently been shown to surpass end-to-end neural networks on challenging vision-language tasks. The latest such methods simultaneously introduce LLM-based code generation to build programs and a number of skill-specific, task-oriented modules to execute them. In this paper, we focus on ViperGPT and ask where its additional performance comes from and how much is due to the (state-of-art, end-to-end) BLIP-2 model it subsumes vs. additional symbolic components. To do so, we conduct a controlled study (comparing end-to-end, modular, and prompting-based methods across several VQA benchmarks). We find that ViperGPT's reported gains over BLIP-2 can be attributed to its selection of task-specific modules, and when we run ViperGPT using a more task-agnostic selection of modules, these gains go away. Additionally, ViperGPT retains much of its performance if we make prominent alterations to its selection of modules: e.g. removing or retaining only BLIP-2. Finally, we compare ViperGPT against a prompting-based decomposition strategy and find that, on some benchmarks, modular approaches significantly benefit by representing subtasks with natural language, instead of code.
What's in a Decade? Transforming Faces Through Time
Oct 17, 2022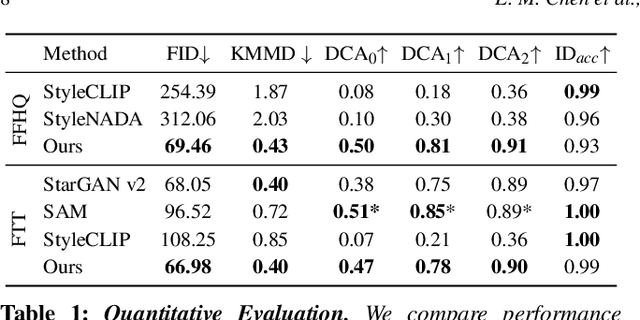

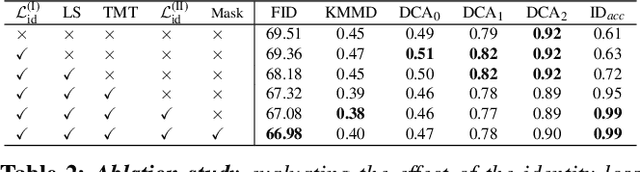
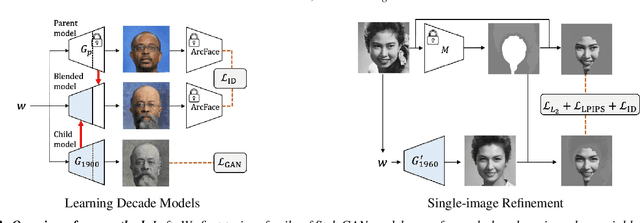
How can one visually characterize people in a decade? In this work, we assemble the Faces Through Time dataset, which contains over a thousand portrait images from each decade, spanning the 1880s to the present day. Using our new dataset, we present a framework for resynthesizing portrait images across time, imagining how a portrait taken during a particular decade might have looked like, had it been taken in other decades. Our framework optimizes a family of per-decade generators that reveal subtle changes that differentiate decade--such as different hairstyles or makeup--while maintaining the identity of the input portrait. Experiments show that our method is more effective in resynthesizing portraits across time compared to state-of-the-art image-to-image translation methods, as well as attribute-based and language-guided portrait editing models. Our code and data will be available at https://facesthroughtime.github.io
A-OKVQA: A Benchmark for Visual Question Answering using World Knowledge
Jun 03, 2022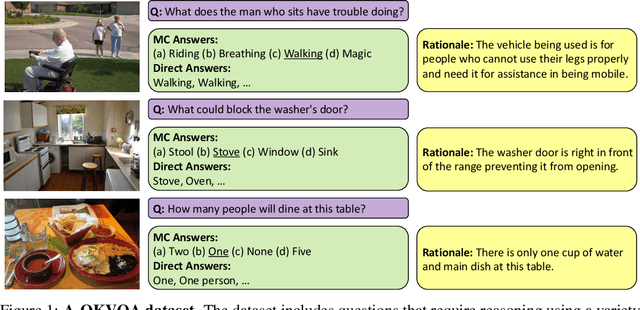

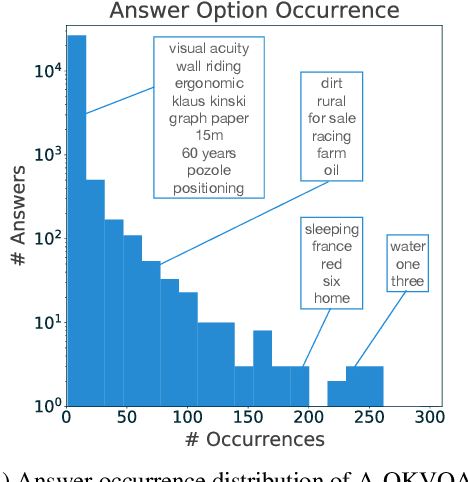
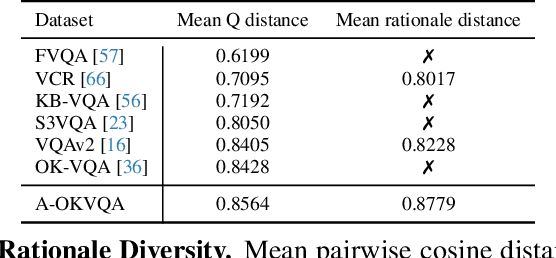
The Visual Question Answering (VQA) task aspires to provide a meaningful testbed for the development of AI models that can jointly reason over visual and natural language inputs. Despite a proliferation of VQA datasets, this goal is hindered by a set of common limitations. These include a reliance on relatively simplistic questions that are repetitive in both concepts and linguistic structure, little world knowledge needed outside of the paired image, and limited reasoning required to arrive at the correct answer. We introduce A-OKVQA, a crowdsourced dataset composed of a diverse set of about 25K questions requiring a broad base of commonsense and world knowledge to answer. In contrast to the existing knowledge-based VQA datasets, the questions generally cannot be answered by simply querying a knowledge base, and instead require some form of commonsense reasoning about the scene depicted in the image. We demonstrate the potential of this new dataset through a detailed analysis of its contents and baseline performance measurements over a variety of state-of-the-art vision-language models. Project page: http://a-okvqa.allenai.org/
Simple but Effective: CLIP Embeddings for Embodied AI
Nov 18, 2021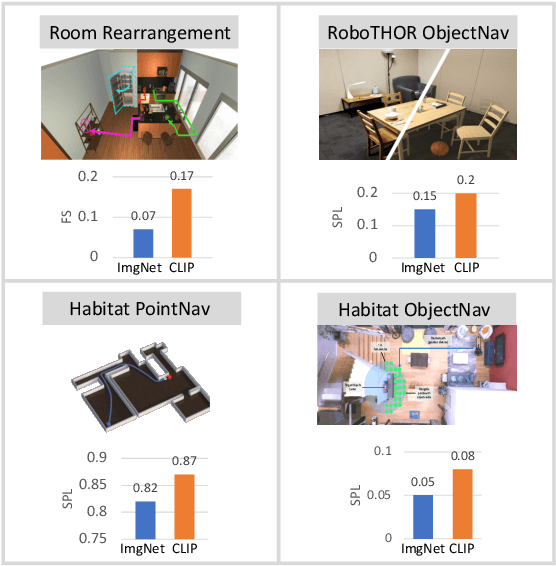
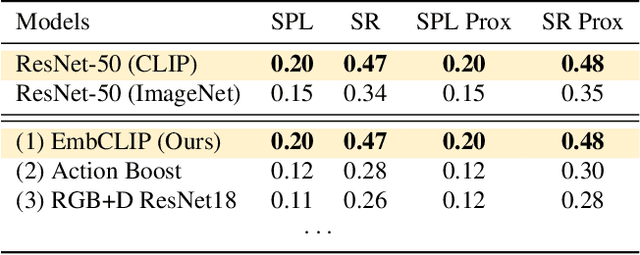
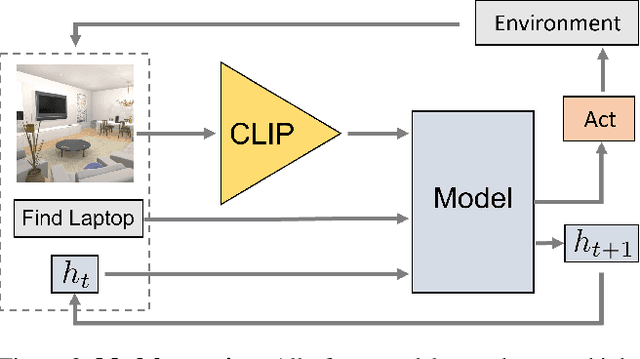
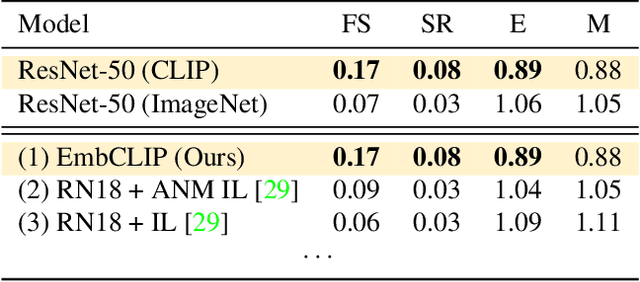
Contrastive language image pretraining (CLIP) encoders have been shown to be beneficial for a range of visual tasks from classification and detection to captioning and image manipulation. We investigate the effectiveness of CLIP visual backbones for embodied AI tasks. We build incredibly simple baselines, named EmbCLIP, with no task specific architectures, inductive biases (such as the use of semantic maps), auxiliary tasks during training, or depth maps -- yet we find that our improved baselines perform very well across a range of tasks and simulators. EmbCLIP tops the RoboTHOR ObjectNav leaderboard by a huge margin of 20 pts (Success Rate). It tops the iTHOR 1-Phase Rearrangement leaderboard, beating the next best submission, which employs Active Neural Mapping, and more than doubling the % Fixed Strict metric (0.08 to 0.17). It also beats the winners of the 2021 Habitat ObjectNav Challenge, which employ auxiliary tasks, depth maps, and human demonstrations, and those of the 2019 Habitat PointNav Challenge. We evaluate the ability of CLIP's visual representations at capturing semantic information about input observations -- primitives that are useful for navigation-heavy embodied tasks -- and find that CLIP's representations encode these primitives more effectively than ImageNet-pretrained backbones. Finally, we extend one of our baselines, producing an agent capable of zero-shot object navigation that can navigate to objects that were not used as targets during training.
Who's Waldo? Linking People Across Text and Images
Aug 17, 2021

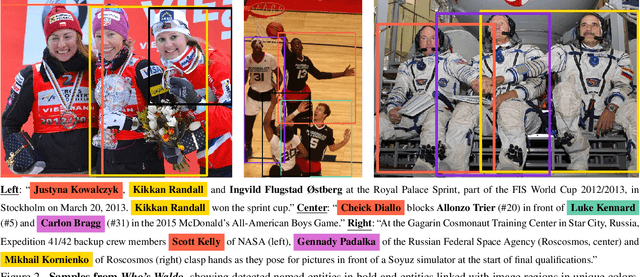
We present a task and benchmark dataset for person-centric visual grounding, the problem of linking between people named in a caption and people pictured in an image. In contrast to prior work in visual grounding, which is predominantly object-based, our new task masks out the names of people in captions in order to encourage methods trained on such image-caption pairs to focus on contextual cues (such as rich interactions between multiple people), rather than learning associations between names and appearances. To facilitate this task, we introduce a new dataset, Who's Waldo, mined automatically from image-caption data on Wikimedia Commons. We propose a Transformer-based method that outperforms several strong baselines on this task, and are releasing our data to the research community to spur work on contextual models that consider both vision and language.
An Ethical Highlighter for People-Centric Dataset Creation
Nov 27, 2020Important ethical concerns arising from computer vision datasets of people have been receiving significant attention, and a number of datasets have been withdrawn as a result. To meet the academic need for people-centric datasets, we propose an analytical framework to guide ethical evaluation of existing datasets and to serve future dataset creators in avoiding missteps. Our work is informed by a review and analysis of prior works and highlights where such ethical challenges arise.