 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimeWarp: Evaluating Web Agents by Revisiting the Past
Mar 05, 2026The improvement of web agents on current benchmarks raises the question: Do today's agents perform just as well when the web changes? We introduce TimeWarp, a benchmark that emulates the evolving web using containerized environments that vary in UI, design, and layout. TimeWarp consists of three web environments, each with six UI versions spanning different eras of the internet, paired with a set of complex, realistic tasks requiring different forms of web navigation. Our experiments reveal web agents' vulnerability to changes and the limitations of behavior cloning (BC) on single-version trajectories. To address this, we propose TimeTraj, a simple yet effective algorithm that uses plan distillation to collect trajectories across multiple versions. By training agents on teacher rollouts using our BC-variant, we achieve substantial performance gains: $20.4\%\rightarrow37.7\%$ for Qwen-3 4B and $0\%\rightarrow27.0\%$ for Llama-3.1 8B models. We hope our work helps researchers study generalization across web designs and unlock a new paradigm for collecting plans rather than trajectories, thereby improving the robustness of web agents.
BriefMe: A Legal NLP Benchmark for Assisting with Legal Briefs
Jun 07, 2025A core part of legal work that has been under-explored in Legal NLP is the writing and editing of legal briefs. This requires not only a thorough understanding of the law of a jurisdiction, from judgments to statutes, but also the ability to make new arguments to try to expand the law in a new direction and make novel and creative arguments that are persuasive to judges. To capture and evaluate these legal skills in language models, we introduce BRIEFME, a new dataset focused on legal briefs. It contains three tasks for language models to assist legal professionals in writing briefs: argument summarization, argument completion, and case retrieval. In this work, we describe the creation of these tasks, analyze them, and show how current models perform. We see that today's large language models (LLMs) are already quite good at the summarization and guided completion tasks, even beating human-generated headings. Yet, they perform poorly on other tasks in our benchmark: realistic argument completion and retrieving relevant legal cases. We hope this dataset encourages more development in Legal NLP in ways that will specifically aid people in performing legal work.
Language Agents Mirror Human Causal Reasoning Biases. How Can We Help Them Think Like Scientists?
May 14, 2025Language model (LM) agents are increasingly used as autonomous decision-makers who need to actively gather information to guide their decisions. A crucial cognitive skill for such agents is the efficient exploration and understanding of the causal structure of the world -- key to robust, scientifically grounded reasoning. Yet, it remains unclear whether LMs possess this capability or exhibit systematic biases leading to erroneous conclusions. In this work, we examine LMs' ability to explore and infer causal relationships, using the well-established "Blicket Test" paradigm from developmental psychology. We find that LMs reliably infer the common, intuitive disjunctive causal relationships but systematically struggle with the unusual, yet equally (or sometimes even more) evidenced conjunctive ones. This "disjunctive bias" persists across model families, sizes, and prompting strategies, and performance further declines as task complexity increases. Interestingly, an analogous bias appears in human adults, suggesting that LMs may have inherited deep-seated reasoning heuristics from their training data. To this end, we quantify similarities between LMs and humans, finding that LMs exhibit adult-like inference profiles (but not children-like). Finally, we propose a test-time sampling method which explicitly samples and eliminates hypotheses about causal relationships from the LM. This scalable approach significantly reduces the disjunctive bias and moves LMs closer to the goal of scientific, causally rigorous reasoning.
Efficient Exploration and Discriminative World Model Learning with an Object-Centric Abstraction
Aug 21, 2024In the face of difficult exploration problems in reinforcement learning, we study whether giving an agent an object-centric mapping (describing a set of items and their attributes) allow for more efficient learning. We found this problem is best solved hierarchically by modelling items at a higher level of state abstraction to pixels, and attribute change at a higher level of temporal abstraction to primitive actions. This abstraction simplifies the transition dynamic by making specific future states easier to predict. We make use of this to propose a fully model-based algorithm that learns a discriminative world model, plans to explore efficiently with only a count-based intrinsic reward, and can subsequently plan to reach any discovered (abstract) states. We demonstrate the model's ability to (i) efficiently solve single tasks, (ii) transfer zero-shot and few-shot across item types and environments, and (iii) plan across long horizons. Across a suite of 2D crafting and MiniHack environments, we empirically show our model significantly out-performs state-of-the-art low-level methods (without abstraction), as well as performant model-free and model-based methods using the same abstraction. Finally, we show how to reinforce learn low level object-perturbing policies, as well as supervise learn the object mapping itself.
ICAL: Continual Learning of Multimodal Agents by Transforming Trajectories into Actionable Insights
Jun 20, 2024Large-scale generative language and vision-language models (LLMs and VLMs) excel in few-shot in-context learning for decision making and instruction following. However, they require high-quality exemplar demonstrations to be included in their context window. In this work, we ask: Can LLMs and VLMs generate their own prompt examples from generic, sub-optimal demonstrations? We propose In-Context Abstraction Learning (ICAL), a method that builds a memory of multimodal experience insights from sub-optimal demonstrations and human feedback. Given a noisy demonstration in a new domain, VLMs abstract the trajectory into a general program by fixing inefficient actions and annotating cognitive abstractions: task relationships, object state changes, temporal subgoals, and task construals. These abstractions are refined and adapted interactively through human feedback while the agent attempts to execute the trajectory in a similar environment. The resulting abstractions, when used as exemplars in the prompt, significantly improve decision-making in retrieval-augmented LLM and VLM agents. Our ICAL agent surpasses the state-of-the-art in dialogue-based instruction following in TEACh, multimodal web agents in VisualWebArena, and action anticipation in Ego4D. In TEACh, we achieve a 12.6% improvement in goal-condition success. In VisualWebArena, our task success rate improves over the SOTA from 14.3% to 22.7%. In Ego4D action forecasting, we improve over few-shot GPT-4V and remain competitive with supervised models. We show finetuning our retrieval-augmented in-context agent yields additional improvements. Our approach significantly reduces reliance on expert-crafted examples and consistently outperforms in-context learning from action plans that lack such insights.
Collaborating with language models for embodied reasoning
Feb 01, 2023Reasoning in a complex and ambiguous environment is a key goal for Reinforcement Learning (RL) agents. While some sophisticated RL agents can successfully solve difficult tasks, they require a large amount of training data and often struggle to generalize to new unseen environments and new tasks. On the other hand, Large Scale Language Models (LSLMs) have exhibited strong reasoning ability and the ability to to adapt to new tasks through in-context learning. However, LSLMs do not inherently have the ability to interrogate or intervene on the environment. In this work, we investigate how to combine these complementary abilities in a single system consisting of three parts: a Planner, an Actor, and a Reporter. The Planner is a pre-trained language model that can issue commands to a simple embodied agent (the Actor), while the Reporter communicates with the Planner to inform its next command. We present a set of tasks that require reasoning, test this system's ability to generalize zero-shot and investigate failure cases, and demonstrate how components of this system can be trained with reinforcement-learning to improve performance.
Distilling Internet-Scale Vision-Language Models into Embodied Agents
Jan 29, 2023



Instruction-following agents must ground language into their observation and action spaces. Learning to ground language is challenging, typically requiring domain-specific engineering or large quantities of human interaction data. To address this challenge, we propose using pretrained vision-language models (VLMs) to supervise embodied agents. We combine ideas from model distillation and hindsight experience replay (HER), using a VLM to retroactively generate language describing the agent's behavior. Simple prompting allows us to control the supervision signal, teaching an agent to interact with novel objects based on their names (e.g., planes) or their features (e.g., colors) in a 3D rendered environment. Fewshot prompting lets us teach abstract category membership, including pre-existing categories (food vs toys) and ad-hoc ones (arbitrary preferences over objects). Our work outlines a new and effective way to use internet-scale VLMs, repurposing the generic language grounding acquired by such models to teach task-relevant groundings to embodied agents.
Learning to Navigate Wikipedia by Taking Random Walks
Oct 31, 2022A fundamental ability of an intelligent web-based agent is seeking out and acquiring new information. Internet search engines reliably find the correct vicinity but the top results may be a few links away from the desired target. A complementary approach is navigation via hyperlinks, employing a policy that comprehends local content and selects a link that moves it closer to the target. In this paper, we show that behavioral cloning of randomly sampled trajectories is sufficient to learn an effective link selection policy. We demonstrate the approach on a graph version of Wikipedia with 38M nodes and 387M edges. The model is able to efficiently navigate between nodes 5 and 20 steps apart 96% and 92% of the time, respectively. We then use the resulting embeddings and policy in downstream fact verification and question answering tasks where, in combination with basic TF-IDF search and ranking methods, they are competitive results to the state-of-the-art methods.
A-OKVQA: A Benchmark for Visual Question Answering using World Knowledge
Jun 03, 2022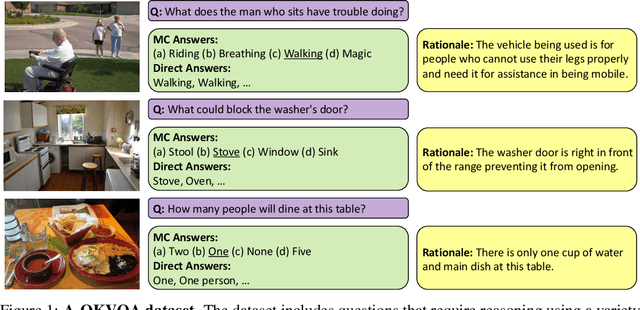

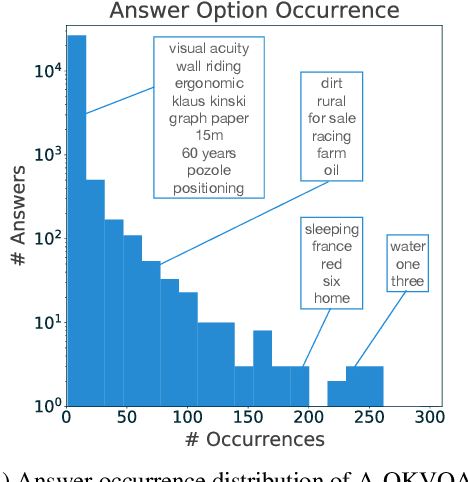
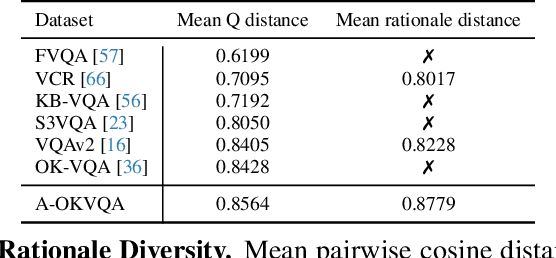
The Visual Question Answering (VQA) task aspires to provide a meaningful testbed for the development of AI models that can jointly reason over visual and natural language inputs. Despite a proliferation of VQA datasets, this goal is hindered by a set of common limitations. These include a reliance on relatively simplistic questions that are repetitive in both concepts and linguistic structure, little world knowledge needed outside of the paired image, and limited reasoning required to arrive at the correct answer. We introduce A-OKVQA, a crowdsourced dataset composed of a diverse set of about 25K questions requiring a broad base of commonsense and world knowledge to answer. In contrast to the existing knowledge-based VQA datasets, the questions generally cannot be answered by simply querying a knowledge base, and instead require some form of commonsense reasoning about the scene depicted in the image. We demonstrate the potential of this new dataset through a detailed analysis of its contents and baseline performance measurements over a variety of state-of-the-art vision-language models. Project page: http://a-okvqa.allenai.org/
KRISP: Integrating Implicit and Symbolic Knowledge for Open-Domain Knowledge-Based VQA
Dec 20, 2020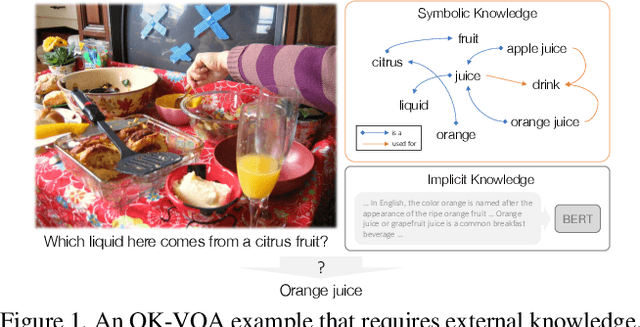



One of the most challenging question types in VQA is when answering the question requires outside knowledge not present in the image. In this work we study open-domain knowledge, the setting when the knowledge required to answer a question is not given/annotated, neither at training nor test time. We tap into two types of knowledge representations and reasoning. First, implicit knowledge which can be learned effectively from unsupervised language pre-training and supervised training data with transformer-based models. Second, explicit, symbolic knowledge encoded in knowledge bases. Our approach combines both - exploiting the powerful implicit reasoning of transformer models for answer prediction, and integrating symbolic representations from a knowledge graph, while never losing their explicit semantics to an implicit embedding. We combine diverse sources of knowledge to cover the wide variety of knowledge needed to solve knowledge-based questions. We show our approach, KRISP (Knowledge Reasoning with Implicit and Symbolic rePresentations), significantly outperforms state-of-the-art on OK-VQA, the largest available dataset for open-domain knowledge-based VQA. We show with extensive ablations that while our model successfully exploits implicit knowledge reasoning, the symbolic answer module which explicitly connects the knowledge graph to the answer vocabulary is critical to the performance of our method and generalizes to rare answers.