 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeterogenous graph neural networks for species distribution modeling
Mar 14, 2025Species distribution models (SDMs) are necessary for measuring and predicting occurrences and habitat suitability of species and their relationship with environmental factors. We introduce a novel presence-only SDM with graph neural networks (GNN). In our model, species and locations are treated as two distinct node sets, and the learning task is predicting detection records as the edges that connect locations to species. Using GNN for SDM allows us to model fine-grained interactions between species and the environment. We evaluate the potential of this methodology on the six-region dataset compiled by National Center for Ecological Analysis and Synthesis (NCEAS) for benchmarking SDMs. For each of the regions, the heterogeneous GNN model is comparable to or outperforms previously-benchmarked single-species SDMs as well as a feed-forward neural network baseline model.
Collaborating with language models for embodied reasoning
Feb 01, 2023Reasoning in a complex and ambiguous environment is a key goal for Reinforcement Learning (RL) agents. While some sophisticated RL agents can successfully solve difficult tasks, they require a large amount of training data and often struggle to generalize to new unseen environments and new tasks. On the other hand, Large Scale Language Models (LSLMs) have exhibited strong reasoning ability and the ability to to adapt to new tasks through in-context learning. However, LSLMs do not inherently have the ability to interrogate or intervene on the environment. In this work, we investigate how to combine these complementary abilities in a single system consisting of three parts: a Planner, an Actor, and a Reporter. The Planner is a pre-trained language model that can issue commands to a simple embodied agent (the Actor), while the Reporter communicates with the Planner to inform its next command. We present a set of tasks that require reasoning, test this system's ability to generalize zero-shot and investigate failure cases, and demonstrate how components of this system can be trained with reinforcement-learning to improve performance.
Learning to Navigate Wikipedia by Taking Random Walks
Oct 31, 2022A fundamental ability of an intelligent web-based agent is seeking out and acquiring new information. Internet search engines reliably find the correct vicinity but the top results may be a few links away from the desired target. A complementary approach is navigation via hyperlinks, employing a policy that comprehends local content and selects a link that moves it closer to the target. In this paper, we show that behavioral cloning of randomly sampled trajectories is sufficient to learn an effective link selection policy. We demonstrate the approach on a graph version of Wikipedia with 38M nodes and 387M edges. The model is able to efficiently navigate between nodes 5 and 20 steps apart 96% and 92% of the time, respectively. We then use the resulting embeddings and policy in downstream fact verification and question answering tasks where, in combination with basic TF-IDF search and ranking methods, they are competitive results to the state-of-the-art methods.
Neural Naturalist: Generating Fine-Grained Image Comparisons
Sep 20, 2019
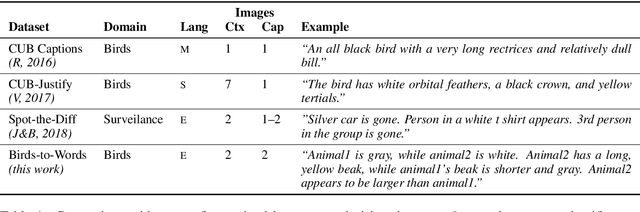
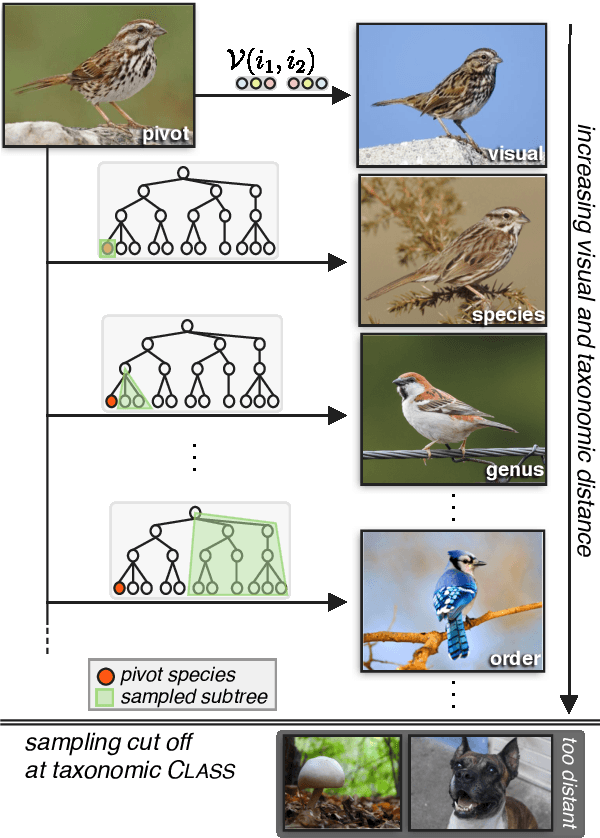
We introduce the new Birds-to-Words dataset of 41k sentences describing fine-grained differences between photographs of birds. The language collected is highly detailed, while remaining understandable to the everyday observer (e.g., "heart-shaped face," "squat body"). Paragraph-length descriptions naturally adapt to varying levels of taxonomic and visual distance---drawn from a novel stratified sampling approach---with the appropriate level of detail. We propose a new model called Neural Naturalist that uses a joint image encoding and comparative module to generate comparative language, and evaluate the results with humans who must use the descriptions to distinguish real images. Our results indicate promising potential for neural models to explain differences in visual embedding space using natural language, as well as a concrete path for machine learning to aid citizen scientists in their effort to preserve biodiversity.
The iMet Collection 2019 Challenge Dataset
Jun 04, 2019
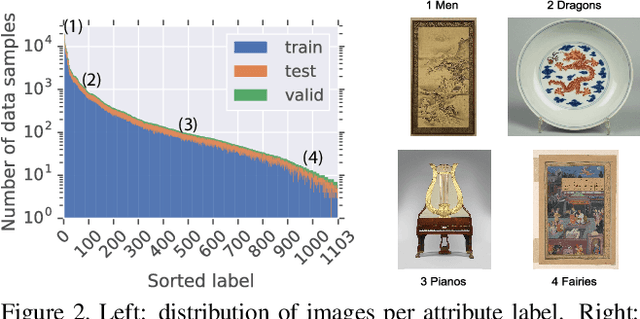
Existing computer vision technologies in artwork recognition focus mainly on instance retrieval or coarse-grained attribute classification. In this work, we present a novel dataset for fine-grained artwork attribute recognition. The images in the dataset are professional photographs of classic artworks from the Metropolitan Museum of Art, and annotations are curated and verified by world-class museum experts. In addition, we also present the iMet Collection 2019 Challenge as part of the FGVC6 workshop. Through the competition, we aim to spur the enthusiasm of the fine-grained visual recognition research community and advance the state-of-the-art in digital curation of museum collections.
Egocentric 6-DoF Tracking of Small Handheld Objects
Apr 16, 2018


Virtual and augmented reality technologies have seen significant growth in the past few years. A key component of such systems is the ability to track the pose of head mounted displays and controllers in 3D space. We tackle the problem of efficient 6-DoF tracking of a handheld controller from egocentric camera perspectives. We collected the HMD Controller dataset which consist of over 540,000 stereo image pairs labelled with the full 6-DoF pose of the handheld controller. Our proposed SSD-AF-Stereo3D model achieves a mean average error of 33.5 millimeters in 3D keypoint prediction and is used in conjunction with an IMU sensor on the controller to enable 6-DoF tracking. We also present results on approaches for model based full 6-DoF tracking. All our models operate under the strict constraints of real time mobile CPU inference.
Real-time Egocentric Gesture Recognition on Mobile Head Mounted Displays
Dec 13, 2017
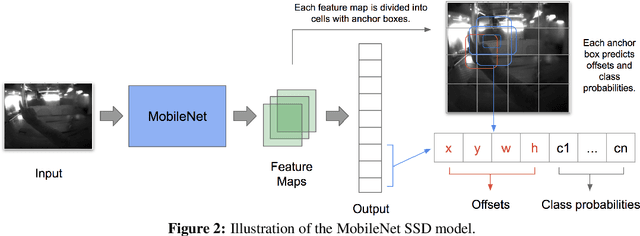
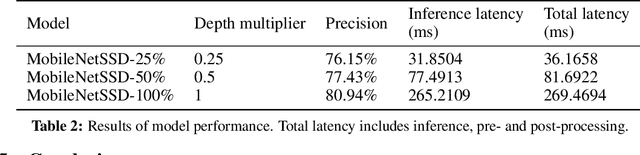
Mobile virtual reality (VR) head mounted displays (HMD) have become popular among consumers in recent years. In this work, we demonstrate real-time egocentric hand gesture detection and localization on mobile HMDs. Our main contributions are: 1) A novel mixed-reality data collection tool to automatic annotate bounding boxes and gesture labels; 2) The largest-to-date egocentric hand gesture and bounding box dataset with more than 400,000 annotated frames; 3) A neural network that runs real time on modern mobile CPUs, and achieves higher than 76% precision on gesture recognition across 8 classes.