 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePixtral 12B
Oct 09, 2024



We introduce Pixtral-12B, a 12--billion-parameter multimodal language model. Pixtral-12B is trained to understand both natural images and documents, achieving leading performance on various multimodal benchmarks, surpassing a number of larger models. Unlike many open-source models, Pixtral is also a cutting-edge text model for its size, and does not compromise on natural language performance to excel in multimodal tasks. Pixtral uses a new vision encoder trained from scratch, which allows it to ingest images at their natural resolution and aspect ratio. This gives users flexibility on the number of tokens used to process an image. Pixtral is also able to process any number of images in its long context window of 128K tokens. Pixtral 12B substanially outperforms other open models of similar sizes (Llama-3.2 11B \& Qwen-2-VL 7B). It also outperforms much larger open models like Llama-3.2 90B while being 7x smaller. We further contribute an open-source benchmark, MM-MT-Bench, for evaluating vision-language models in practical scenarios, and provide detailed analysis and code for standardized evaluation protocols for multimodal LLMs. Pixtral-12B is released under Apache 2.0 license.
Learning to Navigate Wikipedia by Taking Random Walks
Oct 31, 2022A fundamental ability of an intelligent web-based agent is seeking out and acquiring new information. Internet search engines reliably find the correct vicinity but the top results may be a few links away from the desired target. A complementary approach is navigation via hyperlinks, employing a policy that comprehends local content and selects a link that moves it closer to the target. In this paper, we show that behavioral cloning of randomly sampled trajectories is sufficient to learn an effective link selection policy. We demonstrate the approach on a graph version of Wikipedia with 38M nodes and 387M edges. The model is able to efficiently navigate between nodes 5 and 20 steps apart 96% and 92% of the time, respectively. We then use the resulting embeddings and policy in downstream fact verification and question answering tasks where, in combination with basic TF-IDF search and ranking methods, they are competitive results to the state-of-the-art methods.
MuZero with Self-competition for Rate Control in VP9 Video Compression
Feb 14, 2022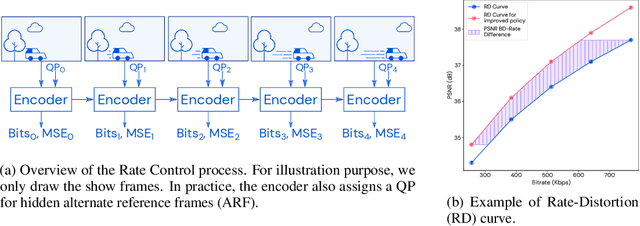

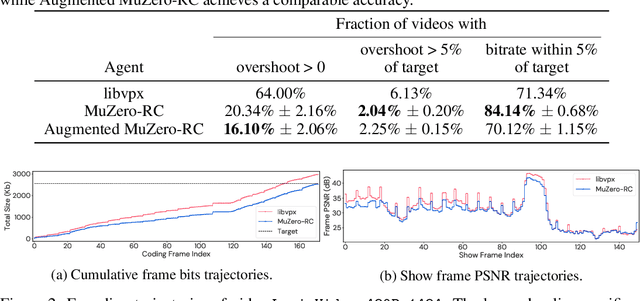
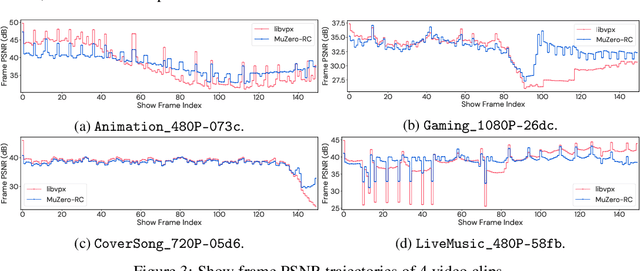
Video streaming usage has seen a significant rise as entertainment, education, and business increasingly rely on online video. Optimizing video compression has the potential to increase access and quality of content to users, and reduce energy use and costs overall. In this paper, we present an application of the MuZero algorithm to the challenge of video compression. Specifically, we target the problem of learning a rate control policy to select the quantization parameters (QP) in the encoding process of libvpx, an open source VP9 video compression library widely used by popular video-on-demand (VOD) services. We treat this as a sequential decision making problem to maximize the video quality with an episodic constraint imposed by the target bitrate. Notably, we introduce a novel self-competition based reward mechanism to solve constrained RL with variable constraint satisfaction difficulty, which is challenging for existing constrained RL methods. We demonstrate that the MuZero-based rate control achieves an average 6.28% reduction in size of the compressed videos for the same delivered video quality level (measured as PSNR BD-rate) compared to libvpx's two-pass VBR rate control policy, while having better constraint satisfaction behavior.