 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Reinforced Self-Training (ReST) for Language Modeling
Aug 21, 2023Reinforcement learning from human feedback (RLHF) can improve the quality of large language model's (LLM) outputs by aligning them with human preferences. We propose a simple algorithm for aligning LLMs with human preferences inspired by growing batch reinforcement learning (RL), which we call Reinforced Self-Training (ReST). Given an initial LLM policy, ReST produces a dataset by generating samples from the policy, which are then used to improve the LLM policy using offline RL algorithms. ReST is more efficient than typical online RLHF methods because the training dataset is produced offline, which allows data reuse. While ReST is a general approach applicable to all generative learning settings, we focus on its application to machine translation. Our results show that ReST can substantially improve translation quality, as measured by automated metrics and human evaluation on machine translation benchmarks in a compute and sample-efficient manner.
MuZero with Self-competition for Rate Control in VP9 Video Compression
Feb 14, 2022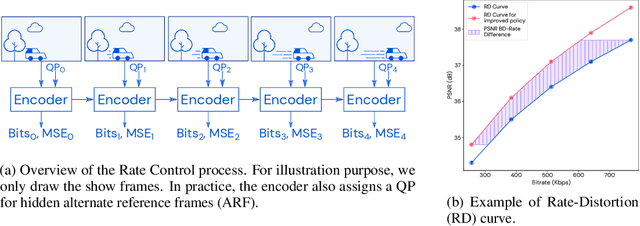

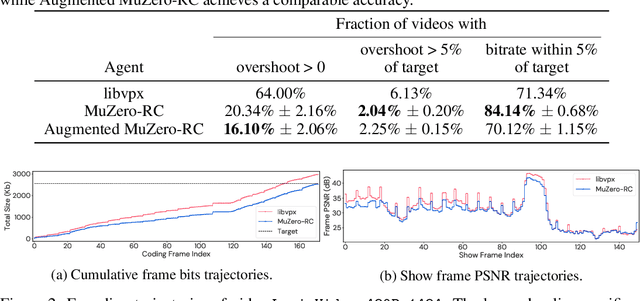
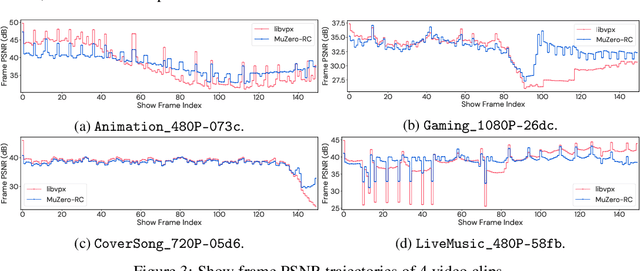
Video streaming usage has seen a significant rise as entertainment, education, and business increasingly rely on online video. Optimizing video compression has the potential to increase access and quality of content to users, and reduce energy use and costs overall. In this paper, we present an application of the MuZero algorithm to the challenge of video compression. Specifically, we target the problem of learning a rate control policy to select the quantization parameters (QP) in the encoding process of libvpx, an open source VP9 video compression library widely used by popular video-on-demand (VOD) services. We treat this as a sequential decision making problem to maximize the video quality with an episodic constraint imposed by the target bitrate. Notably, we introduce a novel self-competition based reward mechanism to solve constrained RL with variable constraint satisfaction difficulty, which is challenging for existing constrained RL methods. We demonstrate that the MuZero-based rate control achieves an average 6.28% reduction in size of the compressed videos for the same delivered video quality level (measured as PSNR BD-rate) compared to libvpx's two-pass VBR rate control policy, while having better constraint satisfaction behavior.
Neural Rate Control for Video Encoding using Imitation Learning
Dec 09, 2020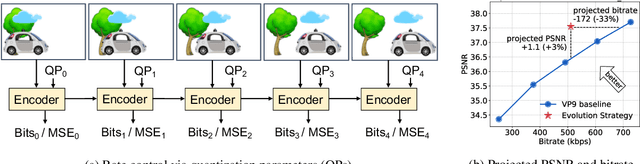
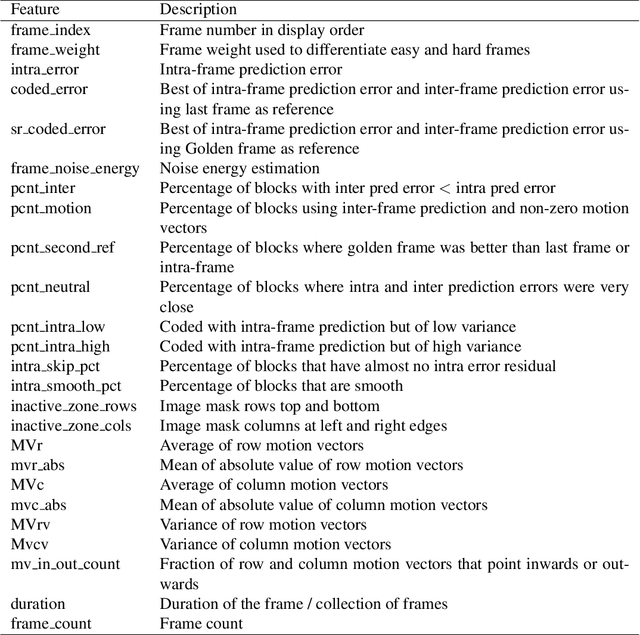
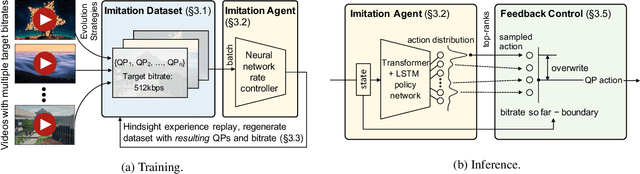
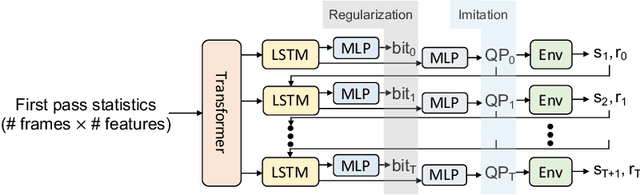
In modern video encoders, rate control is a critical component and has been heavily engineered. It decides how many bits to spend to encode each frame, in order to optimize the rate-distortion trade-off over all video frames. This is a challenging constrained planning problem because of the complex dependency among decisions for different video frames and the bitrate constraint defined at the end of the episode. We formulate the rate control problem as a Partially Observable Markov Decision Process (POMDP), and apply imitation learning to learn a neural rate control policy. We demonstrate that by learning from optimal video encoding trajectories obtained through evolution strategies, our learned policy achieves better encoding efficiency and has minimal constraint violation. In addition to imitating the optimal actions, we find that additional auxiliary losses, data augmentation/refinement and inference-time policy improvements are critical for learning a good rate control policy. We evaluate the learned policy against the rate control policy in libvpx, a widely adopted open source VP9 codec library, in the two-pass variable bitrate (VBR) mode. We show that over a diverse set of real-world videos, our learned policy achieves 8.5% median bitrate reduction without sacrificing video quality.
DDSP: Differentiable Digital Signal Processing
Jan 14, 2020



Most generative models of audio directly generate samples in one of two domains: time or frequency. While sufficient to express any signal, these representations are inefficient, as they do not utilize existing knowledge of how sound is generated and perceived. A third approach (vocoders/synthesizers) successfully incorporates strong domain knowledge of signal processing and perception, but has been less actively researched due to limited expressivity and difficulty integrating with modern auto-differentiation-based machine learning methods. In this paper, we introduce the Differentiable Digital Signal Processing (DDSP) library, which enables direct integration of classic signal processing elements with deep learning methods. Focusing on audio synthesis, we achieve high-fidelity generation without the need for large autoregressive models or adversarial losses, demonstrating that DDSP enables utilizing strong inductive biases without losing the expressive power of neural networks. Further, we show that combining interpretable modules permits manipulation of each separate model component, with applications such as independent control of pitch and loudness, realistic extrapolation to pitches not seen during training, blind dereverberation of room acoustics, transfer of extracted room acoustics to new environments, and transformation of timbre between disparate sources. In short, DDSP enables an interpretable and modular approach to generative modeling, without sacrificing the benefits of deep learning. The library is publicly available at https://github.com/magenta/ddsp and we welcome further contributions from the community and domain experts.
Graph Matching Networks for Learning the Similarity of Graph Structured Objects
May 12, 2019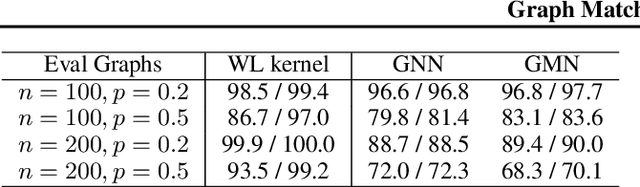

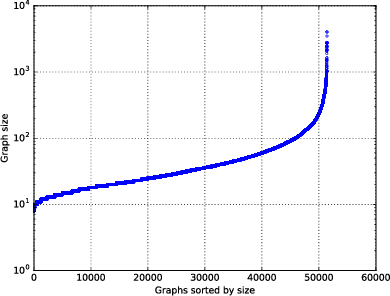

This paper addresses the challenging problem of retrieval and matching of graph structured objects, and makes two key contributions. First, we demonstrate how Graph Neural Networks (GNN), which have emerged as an effective model for various supervised prediction problems defined on structured data, can be trained to produce embedding of graphs in vector spaces that enables efficient similarity reasoning. Second, we propose a novel Graph Matching Network model that, given a pair of graphs as input, computes a similarity score between them by jointly reasoning on the pair through a new cross-graph attention-based matching mechanism. We demonstrate the effectiveness of our models on different domains including the challenging problem of control-flow-graph based function similarity search that plays an important role in the detection of vulnerabilities in software systems. The experimental analysis demonstrates that our models are not only able to exploit structure in the context of similarity learning but they can also outperform domain-specific baseline systems that have been carefully hand-engineered for these problems.
A Generalized Framework for Population Based Training
Feb 05, 2019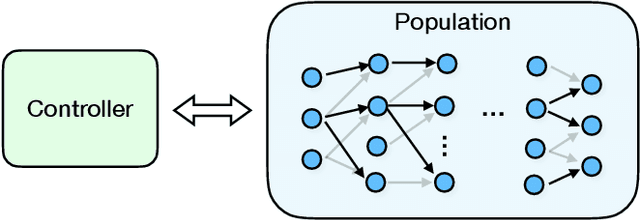
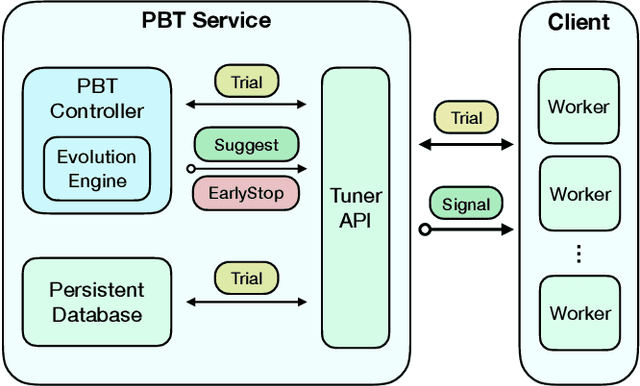

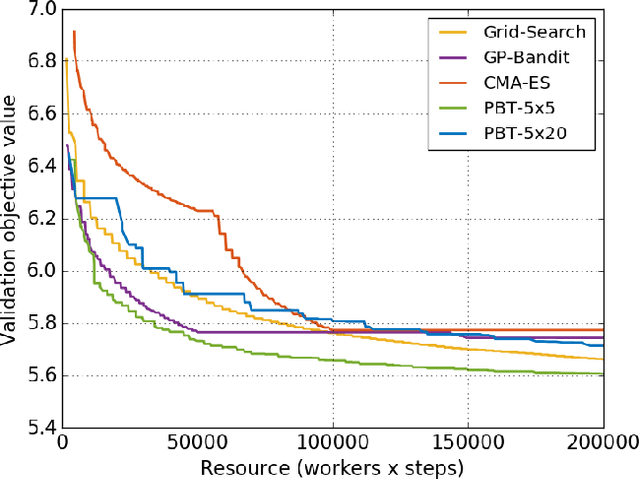
Population Based Training (PBT) is a recent approach that jointly optimizes neural network weights and hyperparameters which periodically copies weights of the best performers and mutates hyperparameters during training. Previous PBT implementations have been synchronized glass-box systems. We propose a general, black-box PBT framework that distributes many asynchronous "trials" (a small number of training steps with warm-starting) across a cluster, coordinated by the PBT controller. The black-box design does not make assumptions on model architectures, loss functions or training procedures. Our system supports dynamic hyperparameter schedules to optimize both differentiable and non-differentiable metrics. We apply our system to train a state-of-the-art WaveNet generative model for human voice synthesis. We show that our PBT system achieves better accuracy, less sensitivity and faster convergence compared to existing methods, given the same computational resource.