 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Convolutional Variational Autoencoders to Predict Post-Trauma Health Outcomes from Actigraphy Data
Nov 20, 2020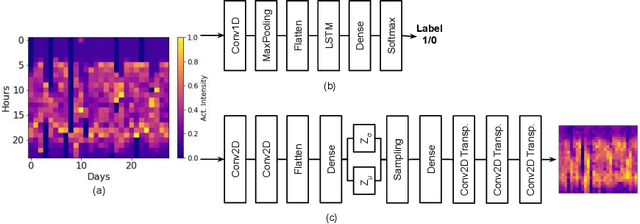
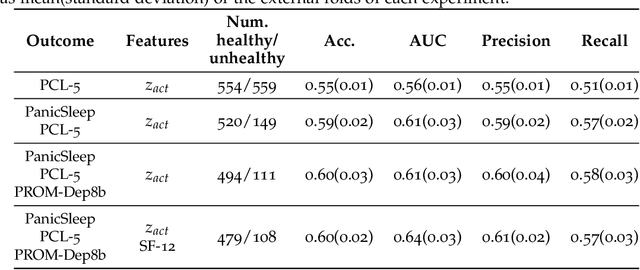
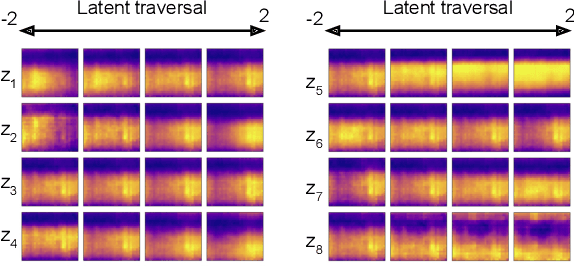
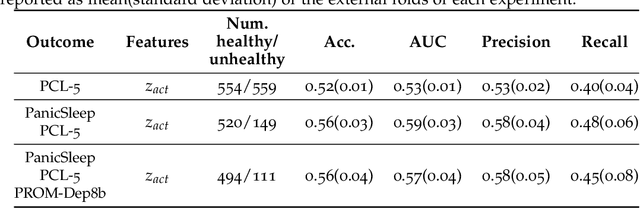
Depression and post-traumatic stress disorder (PTSD) are psychiatric conditions commonly associated with experiencing a traumatic event. Estimating mental health status through non-invasive techniques such as activity-based algorithms can help to identify successful early interventions. In this work, we used locomotor activity captured from 1113 individuals who wore a research grade smartwatch post-trauma. A convolutional variational autoencoder (VAE) architecture was used for unsupervised feature extraction from four weeks of actigraphy data. By using VAE latent variables and the participant's pre-trauma physical health status as features, a logistic regression classifier achieved an area under the receiver operating characteristic curve (AUC) of 0.64 to estimate mental health outcomes. The results indicate that the VAE model is a promising approach for actigraphy data analysis for mental health outcomes in long-term studies.
Representation learning for improved interpretability and classification accuracy of clinical factors from EEG
Oct 30, 2020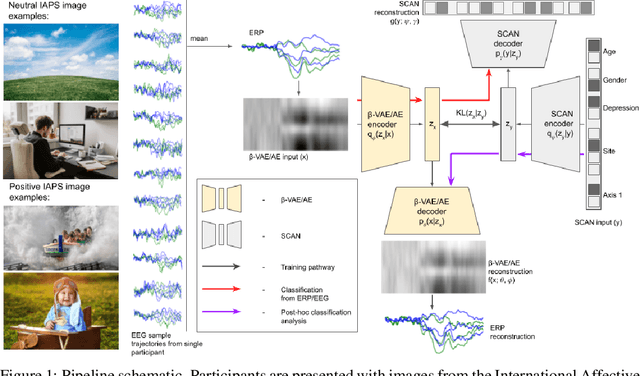
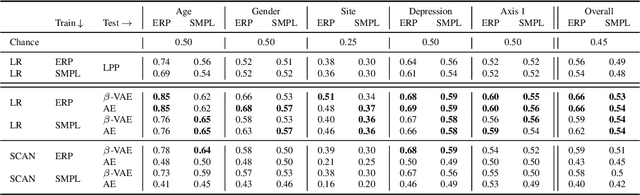
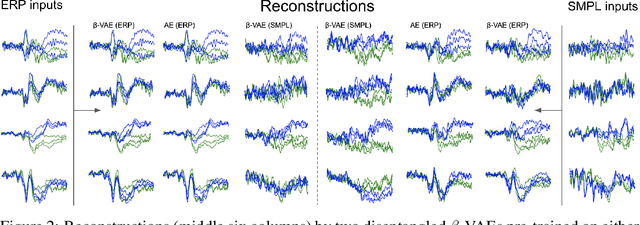

Despite extensive standardization, diagnostic interviews for mental health disorders encompass substantial subjective judgment. Previous studies have demonstrated that EEG-based neural measures can function as reliable objective correlates of depression, or even predictors of depression and its course. However, their clinical utility has not been fully realized because of 1) the lack of automated ways to deal with the inherent noise associated with EEG data at scale, and 2) the lack of knowledge of which aspects of the EEG signal may be markers of a clinical disorder. Here we adapt an unsupervised pipeline from the recent deep representation learning literature to address these problems by 1) learning a disentangled representation using $\beta$-VAE to denoise the signal, and 2) extracting interpretable features associated with a sparse set of clinical labels using a Symbol-Concept Association Network (SCAN). We demonstrate that our method is able to outperform the canonical hand-engineered baseline classification method on a number of factors, including participant age and depression diagnosis. Furthermore, our method recovers a representation that can be used to automatically extract denoised Event Related Potentials (ERPs) from novel, single EEG trajectories, and supports fast supervised re-mapping to various clinical labels, allowing clinicians to re-use a single EEG representation regardless of updates to the standardized diagnostic system. Finally, single factors of the learned disentangled representations often correspond to meaningful markers of clinical factors, as automatically detected by SCAN, allowing for human interpretability and post-hoc expert analysis of the recommendations made by the model.
A Generalized Framework for Population Based Training
Feb 05, 2019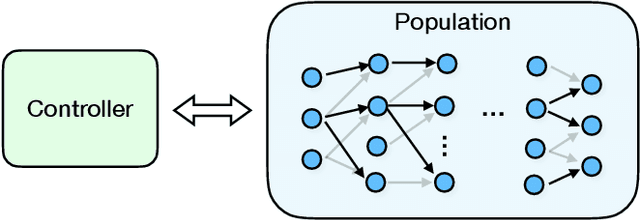
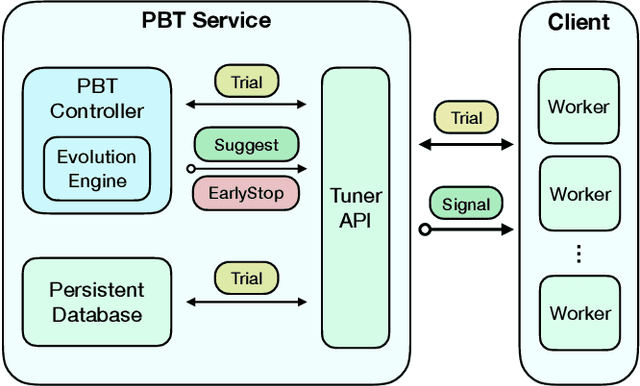

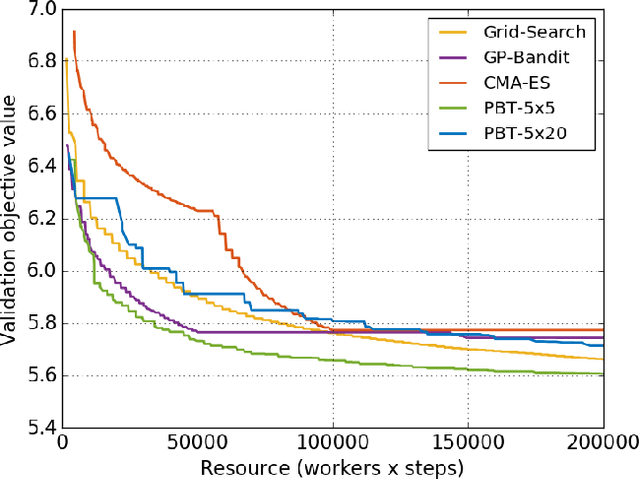
Population Based Training (PBT) is a recent approach that jointly optimizes neural network weights and hyperparameters which periodically copies weights of the best performers and mutates hyperparameters during training. Previous PBT implementations have been synchronized glass-box systems. We propose a general, black-box PBT framework that distributes many asynchronous "trials" (a small number of training steps with warm-starting) across a cluster, coordinated by the PBT controller. The black-box design does not make assumptions on model architectures, loss functions or training procedures. Our system supports dynamic hyperparameter schedules to optimize both differentiable and non-differentiable metrics. We apply our system to train a state-of-the-art WaveNet generative model for human voice synthesis. We show that our PBT system achieves better accuracy, less sensitivity and faster convergence compared to existing methods, given the same computational resource.
Robust Hierarchical Clustering
Jul 13, 2014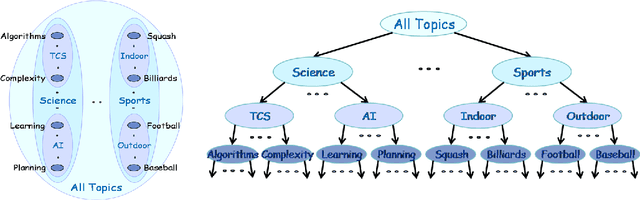
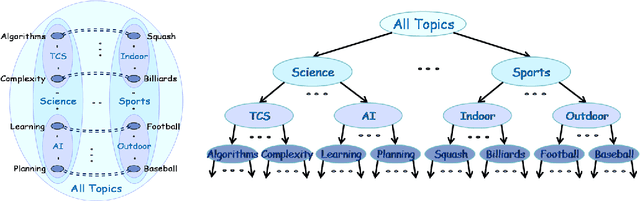
One of the most widely used techniques for data clustering is agglomerative clustering. Such algorithms have been long used across many different fields ranging from computational biology to social sciences to computer vision in part because their output is easy to interpret. Unfortunately, it is well known, however, that many of the classic agglomerative clustering algorithms are not robust to noise. In this paper we propose and analyze a new robust algorithm for bottom-up agglomerative clustering. We show that our algorithm can be used to cluster accurately in cases where the data satisfies a number of natural properties and where the traditional agglomerative algorithms fail. We also show how to adapt our algorithm to the inductive setting where our given data is only a small random sample of the entire data set. Experimental evaluations on synthetic and real world data sets show that our algorithm achieves better performance than other hierarchical algorithms in the presence of noise.