 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Learning Verifiers for Chain-of-Thought Reasoning
May 28, 2025Chain-of-Thought reasoning has emerged as a powerful approach for solving complex mathematical and logical problems. However, it can often veer off track through incorrect or unsubstantiated inferences. Formal mathematical reasoning, which can be checked with a formal verifier, is one approach to addressing this issue. However, currently LLMs are simply not good enough to solve complex problems in a formal way, and even just formalizing an informal problem statement can be challenging. Motivated by this fact, in this work we consider the problem of learning reliable verifiers for natural language Chain-of-Thought reasoning. That is, given a problem statement and step-by-step solution in natural language, the aim of the verifier is to output [Yes] if the reasoning steps in the solution are all valid, and [No] otherwise. In this work we give a formal PAC-learning framework for studying this problem. We propose and analyze several natural verification goals, at different levels of strength, in this framework. We provide sample complexity upper-bounds for learning verifiers satisfying these goals, as well as lower-bound and impossibility results for learning other natural verification objectives without additional assumptions.
Learning in Structured Stackelberg Games
Apr 11, 2025We study structured Stackelberg games, in which both players (the leader and the follower) observe information about the state of the world at time of play. Importantly, this information may contain information about the follower, which the leader may use when deciding her strategy. Under this setting, we show that no-regret learning is possible if and only if the set of mappings from contexts to follower types that the leader uses to learn is not ``too complex''. Specifically, we find that standard learning theoretic measures of complexity do not characterize learnability in our setting and we give a new dimension which does, which we term the Stackelberg-Littlestone dimension. In the distributional setting, we give analogous results by showing that standard complexity measures do not characterize the sample complexity of learning, but a new dimension called the Stackelberg-Natarajan dimension does. We then show that an appropriate empirical risk minimization procedure achieves the corresponding sample complexity.
Sample complexity of data-driven tuning of model hyperparameters in neural networks with structured parameter-dependent dual function
Jan 23, 2025
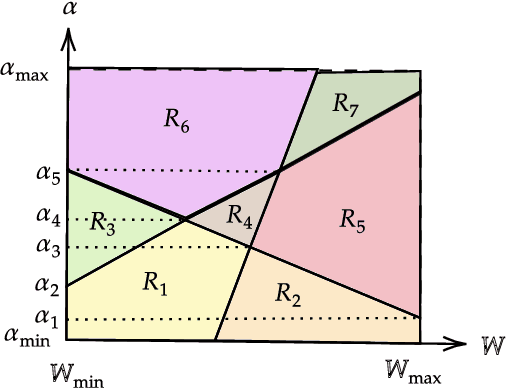
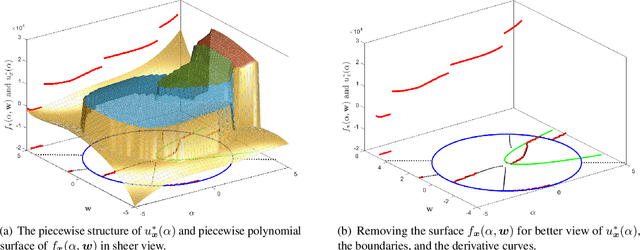
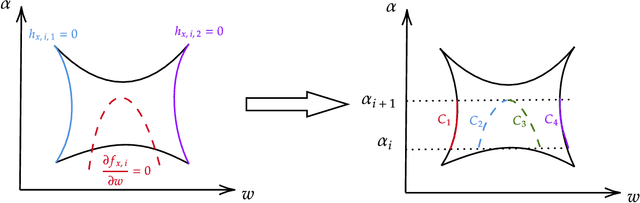
Modern machine learning algorithms, especially deep learning based techniques, typically involve careful hyperparameter tuning to achieve the best performance. Despite the surge of intense interest in practical techniques like Bayesian optimization and random search based approaches to automating this laborious and compute-intensive task, the fundamental learning theoretic complexity of tuning hyperparameters for deep neural networks is poorly understood. Inspired by this glaring gap, we initiate the formal study of hyperparameter tuning complexity in deep learning through a recently introduced data driven setting. We assume that we have a series of deep learning tasks, and we have to tune hyperparameters to do well on average over the distribution of tasks. A major difficulty is that the utility function as a function of the hyperparameter is very volatile and furthermore, it is given implicitly by an optimization problem over the model parameters. This is unlike previous work in data driven design, where one can typically explicitly model the algorithmic behavior as a function of the hyperparameters. To tackle this challenge, we introduce a new technique to characterize the discontinuities and oscillations of the utility function on any fixed problem instance as we vary the hyperparameter, our analysis relies on subtle concepts including tools from differential/algebraic geometry and constrained optimization. This can be used to show that the learning theoretic complexity of the corresponding family of utility functions is bounded. We instantiate our results and provide sample complexity bounds for concrete applications tuning a hyperparameter that interpolates neural activation functions and setting the kernel parameter in graph neural networks.
Provable Hyperparameter Tuning for Structured Pfaffian Settings
Sep 06, 2024Data-driven algorithm design automatically adapts algorithms to specific application domains, achieving better performance. In the context of parameterized algorithms, this approach involves tuning the algorithm parameters using problem instances drawn from the problem distribution of the target application domain. While empirical evidence supports the effectiveness of data-driven algorithm design, providing theoretical guarantees for several parameterized families remains challenging. This is due to the intricate behaviors of their corresponding utility functions, which typically admit piece-wise and discontinuity structures. In this work, we present refined frameworks for providing learning guarantees for parameterized data-driven algorithm design problems in both distributional and online learning settings. For the distributional learning setting, we introduce the Pfaffian GJ framework, an extension of the classical GJ framework, capable of providing learning guarantees for function classes for which the computation involves Pfaffian functions. Unlike the GJ framework, which is limited to function classes with computation characterized by rational functions, our proposed framework can deal with function classes involving Pfaffian functions, which are much more general and widely applicable. We then show that for many parameterized algorithms of interest, their utility function possesses a refined piece-wise structure, which automatically translates to learning guarantees using our proposed framework. For the online learning setting, we provide a new tool for verifying dispersion property of a sequence of loss functions. This sufficient condition allows no-regret learning for sequences of piece-wise structured loss functions where the piece-wise structure involves Pfaffian transition boundaries.
Subsidy design for better social outcomes
Sep 04, 2024Overcoming the impact of selfish behavior of rational players in multiagent systems is a fundamental problem in game theory. Without any intervention from a central agent, strategic users take actions in order to maximize their personal utility, which can lead to extremely inefficient overall system performance, often indicated by a high Price of Anarchy. Recent work (Lin et al. 2021) investigated and formalized yet another undesirable behavior of rational agents, that of avoiding freely available information about the game for selfish reasons, leading to worse social outcomes. A central planner can significantly mitigate these issues by injecting a subsidy to reduce certain costs associated with the system and obtain net gains in the system performance. Crucially, the planner needs to determine how to allocate this subsidy effectively. We formally show that designing subsidies that perfectly optimize the social good, in terms of minimizing the Price of Anarchy or preventing the information avoidance behavior, is computationally hard under standard complexity theoretic assumptions. On the positive side, we show that we can learn provably good values of subsidy in repeated games coming from the same domain. This data-driven subsidy design approach avoids solving computationally hard problems for unseen games by learning over polynomially many games. We also show that optimal subsidy can be learned with no-regret given an online sequence of games, under mild assumptions on the cost matrix. Our study focuses on two distinct games: a Bayesian extension of the well-studied fair cost-sharing game, and a component maintenance game with engineering applications.
Regret Minimization in Stackelberg Games with Side Information
Feb 22, 2024

In its most basic form, a Stackelberg game is a two-player game in which a leader commits to a (mixed) strategy, and a follower best-responds. Stackelberg games are perhaps one of the biggest success stories of algorithmic game theory over the last decade, as algorithms for playing in Stackelberg games have been deployed in many real-world domains including airport security, anti-poaching efforts, and cyber-crime prevention. However, these algorithms often fail to take into consideration the additional information available to each player (e.g. traffic patterns, weather conditions, network congestion), a salient feature of reality which may significantly affect both players' optimal strategies. We formalize such settings as Stackelberg games with side information, in which both players observe an external context before playing. The leader then commits to a (possibly context-dependent) strategy, and the follower best-responds to both the leader's strategy and the context. We focus on the online setting in which a sequence of followers arrive over time, and the context may change from round-to-round. In sharp contrast to the non-contextual version, we show that it is impossible for the leader to achieve good performance (measured by regret) in the full adversarial setting (i.e., when both the context and the follower are chosen by an adversary). However, it turns out that a little bit of randomness goes a long way. Motivated by our impossibility result, we show that no-regret learning is possible in two natural relaxations: the setting in which the sequence of followers is chosen stochastically and the sequence of contexts is adversarial, and the setting in which the sequence of contexts is stochastic and the sequence of followers is chosen by an adversary.
Spectrally Transformed Kernel Regression
Feb 01, 2024Unlabeled data is a key component of modern machine learning. In general, the role of unlabeled data is to impose a form of smoothness, usually from the similarity information encoded in a base kernel, such as the $\epsilon$-neighbor kernel or the adjacency matrix of a graph. This work revisits the classical idea of spectrally transformed kernel regression (STKR), and provides a new class of general and scalable STKR estimators able to leverage unlabeled data. Intuitively, via spectral transformation, STKR exploits the data distribution for which unlabeled data can provide additional information. First, we show that STKR is a principled and general approach, by characterizing a universal type of "target smoothness", and proving that any sufficiently smooth function can be learned by STKR. Second, we provide scalable STKR implementations for the inductive setting and a general transformation function, while prior work is mostly limited to the transductive setting. Third, we derive statistical guarantees for two scenarios: STKR with a known polynomial transformation, and STKR with kernel PCA when the transformation is unknown. Overall, we believe that this work helps deepen our understanding of how to work with unlabeled data, and its generality makes it easier to inspire new methods.
Learning to Relax: Setting Solver Parameters Across a Sequence of Linear System Instances
Oct 03, 2023Solving a linear system $Ax=b$ is a fundamental scientific computing primitive for which numerous solvers and preconditioners have been developed. These come with parameters whose optimal values depend on the system being solved and are often impossible or too expensive to identify; thus in practice sub-optimal heuristics are used. We consider the common setting in which many related linear systems need to be solved, e.g. during a single numerical simulation. In this scenario, can we sequentially choose parameters that attain a near-optimal overall number of iterations, without extra matrix computations? We answer in the affirmative for Successive Over-Relaxation (SOR), a standard solver whose parameter $\omega$ has a strong impact on its runtime. For this method, we prove that a bandit online learning algorithm -- using only the number of iterations as feedback -- can select parameters for a sequence of instances such that the overall cost approaches that of the best fixed $\omega$ as the sequence length increases. Furthermore, when given additional structural information, we show that a contextual bandit method asymptotically achieves the performance of the instance-optimal policy, which selects the best $\omega$ for each instance. Our work provides the first learning-theoretic treatment of high-precision linear system solvers and the first end-to-end guarantees for data-driven scientific computing, demonstrating theoretically the potential to speed up numerical methods using well-understood learning algorithms.
Meta-Learning Adversarial Bandit Algorithms
Jul 05, 2023We study online meta-learning with bandit feedback, with the goal of improving performance across multiple tasks if they are similar according to some natural similarity measure. As the first to target the adversarial online-within-online partial-information setting, we design meta-algorithms that combine outer learners to simultaneously tune the initialization and other hyperparameters of an inner learner for two important cases: multi-armed bandits (MAB) and bandit linear optimization (BLO). For MAB, the meta-learners initialize and set hyperparameters of the Tsallis-entropy generalization of Exp3, with the task-averaged regret improving if the entropy of the optima-in-hindsight is small. For BLO, we learn to initialize and tune online mirror descent (OMD) with self-concordant barrier regularizers, showing that task-averaged regret varies directly with an action space-dependent measure they induce. Our guarantees rely on proving that unregularized follow-the-leader combined with two levels of low-dimensional hyperparameter tuning is enough to learn a sequence of affine functions of non-Lipschitz and sometimes non-convex Bregman divergences bounding the regret of OMD.
Reliable Learning for Test-time Attacks and Distribution Shift
Apr 06, 2023Machine learning algorithms are often used in environments which are not captured accurately even by the most carefully obtained training data, either due to the possibility of `adversarial' test-time attacks, or on account of `natural' distribution shift. For test-time attacks, we introduce and analyze a novel robust reliability guarantee, which requires a learner to output predictions along with a reliability radius $\eta$, with the meaning that its prediction is guaranteed to be correct as long as the adversary has not perturbed the test point farther than a distance $\eta$. We provide learners that are optimal in the sense that they always output the best possible reliability radius on any test point, and we characterize the reliable region, i.e. the set of points where a given reliability radius is attainable. We additionally analyze reliable learners under distribution shift, where the test points may come from an arbitrary distribution Q different from the training distribution P. For both cases, we bound the probability mass of the reliable region for several interesting examples, for linear separators under nearly log-concave and s-concave distributions, as well as for smooth boundary classifiers under smooth probability distributions.