 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Learnability of Chain-of-Thought Verifiers: Soundness and Completeness Trade-offs
Mar 03, 2026Large language models with chain-of-thought generation have demonstrated great potential for producing complex mathematical proofs. However, their reasoning can often go astray, leading to increasing interest in formal and learned verifiers. A major challenge in learning verifiers, especially when their output will be used by the prover, is that this feedback loop may produce substantial distribution shift. Motivated by this challenge, we propose an online learning framework for learning chain-of-thought verifiers that, given a problem and a sequence of reasoning steps, check the correctness of the solution. Highlighting the asymmetric role of soundness (failure in catching errors in a proof) and completeness (flagging correct proofs as wrong) mistakes of the verifier, we introduce novel extensions of the Littlestone dimension which tightly characterize the mistake bounds for learning a verifier in the realizable setting. We provide optimal algorithms for finding the Pareto-frontier (the smallest total number of mistakes given a budget of soundness mistakes) as well as minimizing a linear combination of asymmetric costs. We further show how our learned verifiers can be used to boost the accuracy of a collection of weak provers, and enable generation of proofs beyond what they were trained on. With the mild assumption that one of the provers can generate the next reasoning step correctly with some minimal probability, we show how to learn a strong prover with small error and abstention rates.
Algorithm Design and Stronger Guarantees for the Improving Multi-Armed Bandits Problem
Nov 13, 2025The improving multi-armed bandits problem is a formal model for allocating effort under uncertainty, motivated by scenarios such as investing research effort into new technologies, performing clinical trials, and hyperparameter selection from learning curves. Each pull of an arm provides reward that increases monotonically with diminishing returns. A growing line of work has designed algorithms for improving bandits, albeit with somewhat pessimistic worst-case guarantees. Indeed, strong lower bounds of $Ω(k)$ and $Ω(\sqrt{k})$ multiplicative approximation factors are known for both deterministic and randomized algorithms (respectively) relative to the optimal arm, where $k$ is the number of bandit arms. In this work, we propose two new parameterized families of bandit algorithms and bound the sample complexity of learning the near-optimal algorithm from each family using offline data. The first family we define includes the optimal randomized algorithm from prior work. We show that an appropriately chosen algorithm from this family can achieve stronger guarantees, with optimal dependence on $k$, when the arm reward curves satisfy additional properties related to the strength of concavity. Our second family contains algorithms that both guarantee best-arm identification on well-behaved instances and revert to worst case guarantees on poorly-behaved instances. Taking a statistical learning perspective on the bandit rewards optimization problem, we achieve stronger data-dependent guarantees without the need for actually verifying whether the assumptions are satisfied.
Conservative classifiers do consistently well with improving agents: characterizing statistical and online learning
Jun 05, 2025Machine learning is now ubiquitous in societal decision-making, for example in evaluating job candidates or loan applications, and it is increasingly important to take into account how classified agents will react to the learning algorithms. The majority of recent literature on strategic classification has focused on reducing and countering deceptive behaviors by the classified agents, but recent work of Attias et al. identifies surprising properties of learnability when the agents genuinely improve in order to attain the desirable classification, such as smaller generalization error than standard PAC-learning. In this paper we characterize so-called learnability with improvements across multiple new axes. We introduce an asymmetric variant of minimally consistent concept classes and use it to provide an exact characterization of proper learning with improvements in the realizable setting. While prior work studies learnability only under general, arbitrary agent improvement regions, we give positive results for more natural Euclidean ball improvement sets. In particular, we characterize improper learning under a mild generative assumption on the data distribution. We further show how to learn in more challenging settings, achieving lower generalization error under well-studied bounded noise models and obtaining mistake bounds in realizable and agnostic online learning. We resolve open questions posed by Attias et al. for both proper and improper learning.
On Learning Verifiers for Chain-of-Thought Reasoning
May 28, 2025Chain-of-Thought reasoning has emerged as a powerful approach for solving complex mathematical and logical problems. However, it can often veer off track through incorrect or unsubstantiated inferences. Formal mathematical reasoning, which can be checked with a formal verifier, is one approach to addressing this issue. However, currently LLMs are simply not good enough to solve complex problems in a formal way, and even just formalizing an informal problem statement can be challenging. Motivated by this fact, in this work we consider the problem of learning reliable verifiers for natural language Chain-of-Thought reasoning. That is, given a problem statement and step-by-step solution in natural language, the aim of the verifier is to output [Yes] if the reasoning steps in the solution are all valid, and [No] otherwise. In this work we give a formal PAC-learning framework for studying this problem. We propose and analyze several natural verification goals, at different levels of strength, in this framework. We provide sample complexity upper-bounds for learning verifiers satisfying these goals, as well as lower-bound and impossibility results for learning other natural verification objectives without additional assumptions.
PAC Learning with Improvements
Mar 05, 2025One of the most basic lower bounds in machine learning is that in nearly any nontrivial setting, it takes $\textit{at least}$ $1/\epsilon$ samples to learn to error $\epsilon$ (and more, if the classifier being learned is complex). However, suppose that data points are agents who have the ability to improve by a small amount if doing so will allow them to receive a (desired) positive classification. In that case, we may actually be able to achieve $\textit{zero}$ error by just being "close enough". For example, imagine a hiring test used to measure an agent's skill at some job such that for some threshold $\theta$, agents who score above $\theta$ will be successful and those who score below $\theta$ will not (i.e., learning a threshold on the line). Suppose also that by putting in effort, agents can improve their skill level by some small amount $r$. In that case, if we learn an approximation $\hat{\theta}$ of $\theta$ such that $\theta \leq \hat{\theta} \leq \theta + r$ and use it for hiring, we can actually achieve error zero, in the sense that (a) any agent classified as positive is truly qualified, and (b) any agent who truly is qualified can be classified as positive by putting in effort. Thus, the ability for agents to improve has the potential to allow for a goal one could not hope to achieve in standard models, namely zero error. In this paper, we explore this phenomenon more broadly, giving general results and examining under what conditions the ability of agents to improve can allow for a reduction in the sample complexity of learning, or alternatively, can make learning harder. We also examine both theoretically and empirically what kinds of improvement-aware algorithms can take into account agents who have the ability to improve to a limited extent when it is in their interest to do so.
Tuning Algorithmic and Architectural Hyperparameters in Graph-Based Semi-Supervised Learning with Provable Guarantees
Feb 18, 2025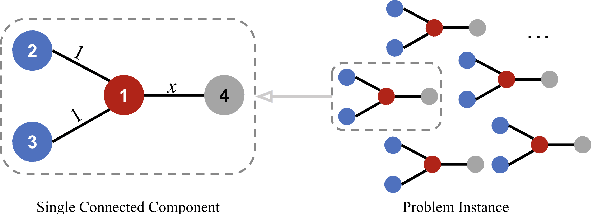

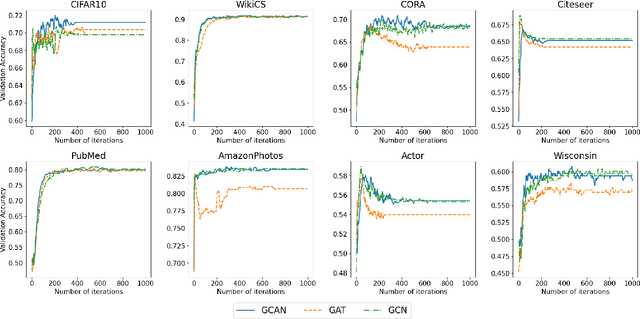
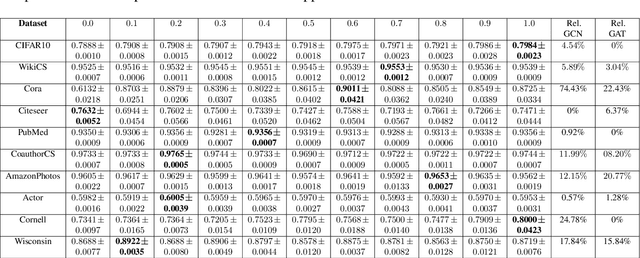
Graph-based semi-supervised learning is a powerful paradigm in machine learning for modeling and exploiting the underlying graph structure that captures the relationship between labeled and unlabeled data. A large number of classical as well as modern deep learning based algorithms have been proposed for this problem, often having tunable hyperparameters. We initiate a formal study of tuning algorithm hyperparameters from parameterized algorithm families for this problem. We obtain novel $O(\log n)$ pseudo-dimension upper bounds for hyperparameter selection in three classical label propagation-based algorithm families, where $n$ is the number of nodes, implying bounds on the amount of data needed for learning provably good parameters. We further provide matching $\Omega(\log n)$ pseudo-dimension lower bounds, thus asymptotically characterizing the learning-theoretic complexity of the parameter tuning problem. We extend our study to selecting architectural hyperparameters in modern graph neural networks. We bound the Rademacher complexity for tuning the self-loop weighting in recently proposed Simplified Graph Convolution (SGC) networks. We further propose a tunable architecture that interpolates graph convolutional neural networks (GCN) and graph attention networks (GAT) in every layer, and provide Rademacher complexity bounds for tuning the interpolation coefficient.
Sample complexity of data-driven tuning of model hyperparameters in neural networks with structured parameter-dependent dual function
Jan 23, 2025
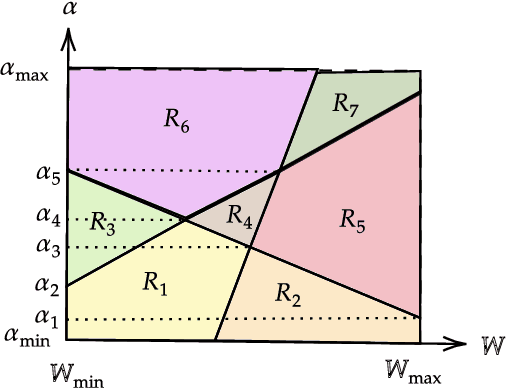
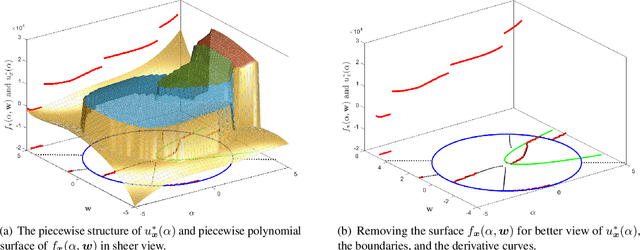
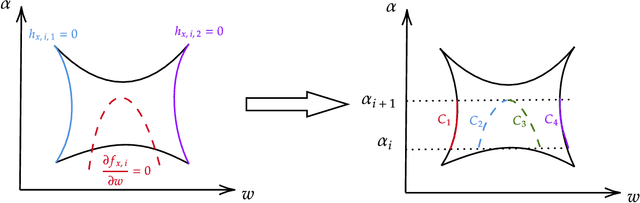
Modern machine learning algorithms, especially deep learning based techniques, typically involve careful hyperparameter tuning to achieve the best performance. Despite the surge of intense interest in practical techniques like Bayesian optimization and random search based approaches to automating this laborious and compute-intensive task, the fundamental learning theoretic complexity of tuning hyperparameters for deep neural networks is poorly understood. Inspired by this glaring gap, we initiate the formal study of hyperparameter tuning complexity in deep learning through a recently introduced data driven setting. We assume that we have a series of deep learning tasks, and we have to tune hyperparameters to do well on average over the distribution of tasks. A major difficulty is that the utility function as a function of the hyperparameter is very volatile and furthermore, it is given implicitly by an optimization problem over the model parameters. This is unlike previous work in data driven design, where one can typically explicitly model the algorithmic behavior as a function of the hyperparameters. To tackle this challenge, we introduce a new technique to characterize the discontinuities and oscillations of the utility function on any fixed problem instance as we vary the hyperparameter, our analysis relies on subtle concepts including tools from differential/algebraic geometry and constrained optimization. This can be used to show that the learning theoretic complexity of the corresponding family of utility functions is bounded. We instantiate our results and provide sample complexity bounds for concrete applications tuning a hyperparameter that interpolates neural activation functions and setting the kernel parameter in graph neural networks.
Offline-to-online hyperparameter transfer for stochastic bandits
Jan 06, 2025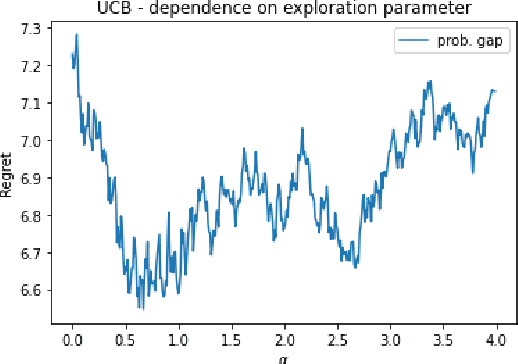

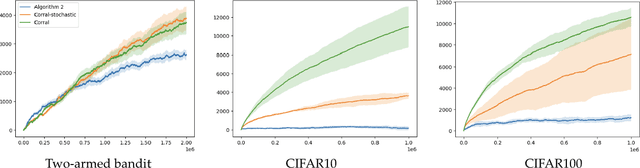
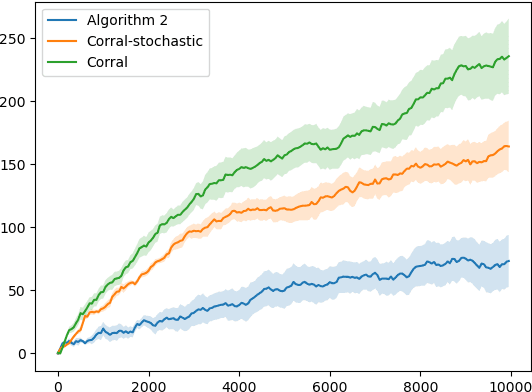
Classic algorithms for stochastic bandits typically use hyperparameters that govern their critical properties such as the trade-off between exploration and exploitation. Tuning these hyperparameters is a problem of great practical significance. However, this is a challenging problem and in certain cases is information theoretically impossible. To address this challenge, we consider a practically relevant transfer learning setting where one has access to offline data collected from several bandit problems (tasks) coming from an unknown distribution over the tasks. Our aim is to use this offline data to set the hyperparameters for a new task drawn from the unknown distribution. We provide bounds on the inter-task (number of tasks) and intra-task (number of arm pulls for each task) sample complexity for learning near-optimal hyperparameters on unseen tasks drawn from the distribution. Our results apply to several classic algorithms, including tuning the exploration parameters in UCB and LinUCB and the noise parameter in GP-UCB. Our experiments indicate the significance and effectiveness of the transfer of hyperparameters from offline problems in online learning with stochastic bandit feedback.
Provable Hyperparameter Tuning for Structured Pfaffian Settings
Sep 06, 2024Data-driven algorithm design automatically adapts algorithms to specific application domains, achieving better performance. In the context of parameterized algorithms, this approach involves tuning the algorithm parameters using problem instances drawn from the problem distribution of the target application domain. While empirical evidence supports the effectiveness of data-driven algorithm design, providing theoretical guarantees for several parameterized families remains challenging. This is due to the intricate behaviors of their corresponding utility functions, which typically admit piece-wise and discontinuity structures. In this work, we present refined frameworks for providing learning guarantees for parameterized data-driven algorithm design problems in both distributional and online learning settings. For the distributional learning setting, we introduce the Pfaffian GJ framework, an extension of the classical GJ framework, capable of providing learning guarantees for function classes for which the computation involves Pfaffian functions. Unlike the GJ framework, which is limited to function classes with computation characterized by rational functions, our proposed framework can deal with function classes involving Pfaffian functions, which are much more general and widely applicable. We then show that for many parameterized algorithms of interest, their utility function possesses a refined piece-wise structure, which automatically translates to learning guarantees using our proposed framework. For the online learning setting, we provide a new tool for verifying dispersion property of a sequence of loss functions. This sufficient condition allows no-regret learning for sequences of piece-wise structured loss functions where the piece-wise structure involves Pfaffian transition boundaries.
Subsidy design for better social outcomes
Sep 04, 2024Overcoming the impact of selfish behavior of rational players in multiagent systems is a fundamental problem in game theory. Without any intervention from a central agent, strategic users take actions in order to maximize their personal utility, which can lead to extremely inefficient overall system performance, often indicated by a high Price of Anarchy. Recent work (Lin et al. 2021) investigated and formalized yet another undesirable behavior of rational agents, that of avoiding freely available information about the game for selfish reasons, leading to worse social outcomes. A central planner can significantly mitigate these issues by injecting a subsidy to reduce certain costs associated with the system and obtain net gains in the system performance. Crucially, the planner needs to determine how to allocate this subsidy effectively. We formally show that designing subsidies that perfectly optimize the social good, in terms of minimizing the Price of Anarchy or preventing the information avoidance behavior, is computationally hard under standard complexity theoretic assumptions. On the positive side, we show that we can learn provably good values of subsidy in repeated games coming from the same domain. This data-driven subsidy design approach avoids solving computationally hard problems for unseen games by learning over polynomially many games. We also show that optimal subsidy can be learned with no-regret given an online sequence of games, under mild assumptions on the cost matrix. Our study focuses on two distinct games: a Bayesian extension of the well-studied fair cost-sharing game, and a component maintenance game with engineering applications.