 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvably Data-driven Multiple Hyper-parameter Tuning with Structured Loss Function
Feb 02, 2026Data-driven algorithm design automates hyperparameter tuning, but its statistical foundations remain limited because model performance can depend on hyperparameters in implicit and highly non-smooth ways. Existing guarantees focus on the simple case of a one-dimensional (scalar) hyperparameter. This leaves the practically important, multi-dimensional hyperparameter tuning setting unresolved. We address this open question by establishing the first general framework for establishing generalization guarantees for tuning multi-dimensional hyperparameters in data-driven settings. Our approach strengthens the generalization guarantee framework for semi-algebraic function classes by exploiting tools from real algebraic geometry, yielding sharper, more broadly applicable guarantees. We then extend the analysis to hyperparameter tuning using the validation loss under minimal assumptions, and derive improved bounds when additional structure is available. Finally, we demonstrate the scope of the framework with new learnability results, including data-driven weighted group lasso and weighted fused lasso.
Model-Free Counterfactual Subset Selection at Scale
Feb 12, 2025Ensuring transparency in AI decision-making requires interpretable explanations, particularly at the instance level. Counterfactual explanations are a powerful tool for this purpose, but existing techniques frequently depend on synthetic examples, introducing biases from unrealistic assumptions, flawed models, or skewed data. Many methods also assume full dataset availability, an impractical constraint in real-time environments where data flows continuously. In contrast, streaming explanations offer adaptive, real-time insights without requiring persistent storage of the entire dataset. This work introduces a scalable, model-free approach to selecting diverse and relevant counterfactual examples directly from observed data. Our algorithm operates efficiently in streaming settings, maintaining $O(\log k)$ update complexity per item while ensuring high-quality counterfactual selection. Empirical evaluations on both real-world and synthetic datasets demonstrate superior performance over baseline methods, with robust behavior even under adversarial conditions.
Sample complexity of data-driven tuning of model hyperparameters in neural networks with structured parameter-dependent dual function
Jan 23, 2025
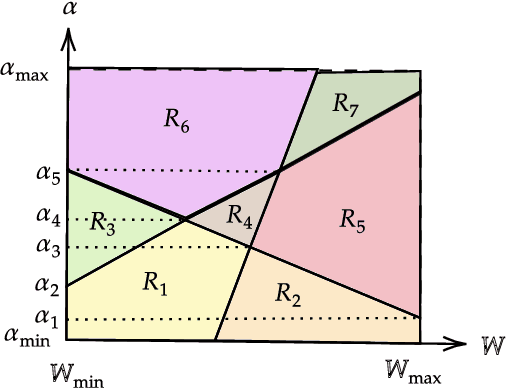
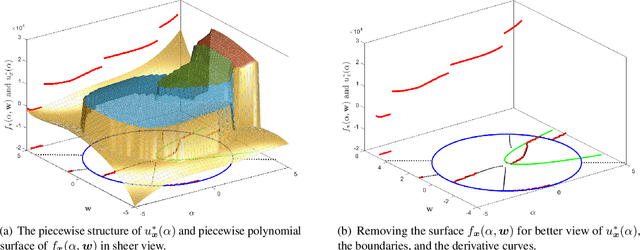
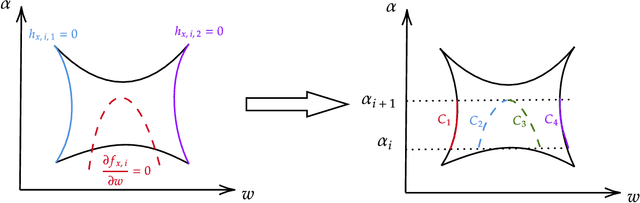
Modern machine learning algorithms, especially deep learning based techniques, typically involve careful hyperparameter tuning to achieve the best performance. Despite the surge of intense interest in practical techniques like Bayesian optimization and random search based approaches to automating this laborious and compute-intensive task, the fundamental learning theoretic complexity of tuning hyperparameters for deep neural networks is poorly understood. Inspired by this glaring gap, we initiate the formal study of hyperparameter tuning complexity in deep learning through a recently introduced data driven setting. We assume that we have a series of deep learning tasks, and we have to tune hyperparameters to do well on average over the distribution of tasks. A major difficulty is that the utility function as a function of the hyperparameter is very volatile and furthermore, it is given implicitly by an optimization problem over the model parameters. This is unlike previous work in data driven design, where one can typically explicitly model the algorithmic behavior as a function of the hyperparameters. To tackle this challenge, we introduce a new technique to characterize the discontinuities and oscillations of the utility function on any fixed problem instance as we vary the hyperparameter, our analysis relies on subtle concepts including tools from differential/algebraic geometry and constrained optimization. This can be used to show that the learning theoretic complexity of the corresponding family of utility functions is bounded. We instantiate our results and provide sample complexity bounds for concrete applications tuning a hyperparameter that interpolates neural activation functions and setting the kernel parameter in graph neural networks.
VPI-Mlogs: A web-based machine learning solution for applications in petrophysics
Oct 06, 2024Machine learning is an important part of the data science field. In petrophysics, machine learning algorithms and applications have been widely approached. In this context, Vietnam Petroleum Institute (VPI) has researched and deployed several effective prediction models, namely missing log prediction, fracture zone and fracture density forecast, etc. As one of our solutions, VPI-MLogs is a web-based deployment platform which integrates data preprocessing, exploratory data analysis, visualisation and model execution. Using the most popular data analysis programming language, Python, this approach gives users a powerful tool to deal with the petrophysical logs section. The solution helps to narrow the gap between common knowledge and petrophysics insights. This article will focus on the web-based application which integrates many solutions to grasp petrophysical data.
Provable Hyperparameter Tuning for Structured Pfaffian Settings
Sep 06, 2024Data-driven algorithm design automatically adapts algorithms to specific application domains, achieving better performance. In the context of parameterized algorithms, this approach involves tuning the algorithm parameters using problem instances drawn from the problem distribution of the target application domain. While empirical evidence supports the effectiveness of data-driven algorithm design, providing theoretical guarantees for several parameterized families remains challenging. This is due to the intricate behaviors of their corresponding utility functions, which typically admit piece-wise and discontinuity structures. In this work, we present refined frameworks for providing learning guarantees for parameterized data-driven algorithm design problems in both distributional and online learning settings. For the distributional learning setting, we introduce the Pfaffian GJ framework, an extension of the classical GJ framework, capable of providing learning guarantees for function classes for which the computation involves Pfaffian functions. Unlike the GJ framework, which is limited to function classes with computation characterized by rational functions, our proposed framework can deal with function classes involving Pfaffian functions, which are much more general and widely applicable. We then show that for many parameterized algorithms of interest, their utility function possesses a refined piece-wise structure, which automatically translates to learning guarantees using our proposed framework. For the online learning setting, we provide a new tool for verifying dispersion property of a sequence of loss functions. This sufficient condition allows no-regret learning for sequences of piece-wise structured loss functions where the piece-wise structure involves Pfaffian transition boundaries.
XMainframe: A Large Language Model for Mainframe Modernization
Aug 05, 2024



Mainframe operating systems, despite their inception in the 1940s, continue to support critical sectors like finance and government. However, these systems are often viewed as outdated, requiring extensive maintenance and modernization. Addressing this challenge necessitates innovative tools that can understand and interact with legacy codebases. To this end, we introduce XMainframe, a state-of-the-art large language model (LLM) specifically designed with knowledge of mainframe legacy systems and COBOL codebases. Our solution involves the creation of an extensive data collection pipeline to produce high-quality training datasets, enhancing XMainframe's performance in this specialized domain. Additionally, we present MainframeBench, a comprehensive benchmark for assessing mainframe knowledge, including multiple-choice questions, question answering, and COBOL code summarization. Our empirical evaluations demonstrate that XMainframe consistently outperforms existing state-of-the-art LLMs across these tasks. Specifically, XMainframe achieves 30% higher accuracy than DeepSeek-Coder on multiple-choice questions, doubles the BLEU score of Mixtral-Instruct 8x7B on question answering, and scores six times higher than GPT-3.5 on COBOL summarization. Our work highlights the potential of XMainframe to drive significant advancements in managing and modernizing legacy systems, thereby enhancing productivity and saving time for software developers.
Artificial Intelligence Enables Real-Time and Intuitive Control of Prostheses via Nerve Interface
Mar 16, 2022
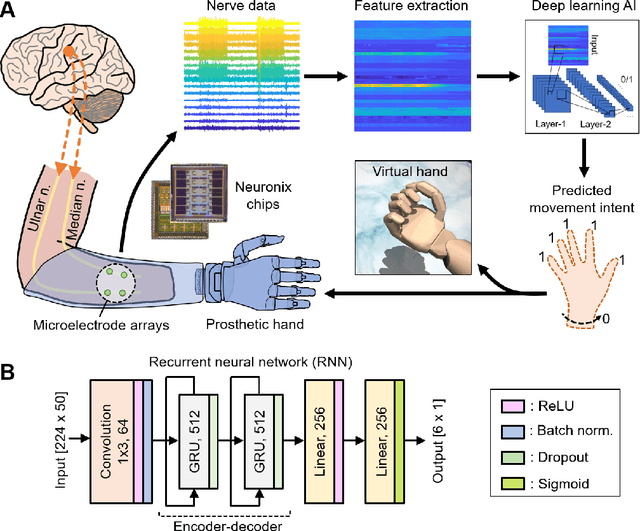


Objective: The next generation prosthetic hand that moves and feels like a real hand requires a robust neural interconnection between the human minds and machines. Methods: Here we present a neuroprosthetic system to demonstrate that principle by employing an artificial intelligence (AI) agent to translate the amputee's movement intent through a peripheral nerve interface. The AI agent is designed based on the recurrent neural network (RNN) and could simultaneously decode six degree-of-freedom (DOF) from multichannel nerve data in real-time. The decoder's performance is characterized in motor decoding experiments with three human amputees. Results: First, we show the AI agent enables amputees to intuitively control a prosthetic hand with individual finger and wrist movements up to 97-98% accuracy. Second, we demonstrate the AI agent's real-time performance by measuring the reaction time and information throughput in a hand gesture matching task. Third, we investigate the AI agent's long-term uses and show the decoder's robust predictive performance over a 16-month implant duration. Conclusion & significance: Our study demonstrates the potential of AI-enabled nerve technology, underling the next generation of dexterous and intuitive prosthetic hands.
A Portable, Self-Contained Neuroprosthetic Hand with Deep Learning-Based Finger Control
Mar 24, 2021

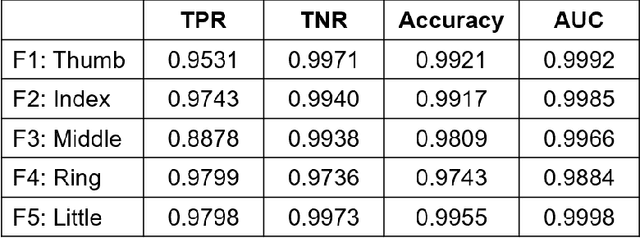
Objective: Deep learning-based neural decoders have emerged as the prominent approach to enable dexterous and intuitive control of neuroprosthetic hands. Yet few studies have materialized the use of deep learning in clinical settings due to its high computational requirements. Methods: Recent advancements of edge computing devices bring the potential to alleviate this problem. Here we present the implementation of a neuroprosthetic hand with embedded deep learning-based control. The neural decoder is designed based on the recurrent neural network (RNN) architecture and deployed on the NVIDIA Jetson Nano - a compacted yet powerful edge computing platform for deep learning inference. This enables the implementation of the neuroprosthetic hand as a portable and self-contained unit with real-time control of individual finger movements. Results: The proposed system is evaluated on a transradial amputee using peripheral nerve signals (ENG) with implanted intrafascicular microelectrodes. The experiment results demonstrate the system's capabilities of providing robust, high-accuracy (95-99%) and low-latency (50-120 msec) control of individual finger movements in various laboratory and real-world environments. Conclusion: Modern edge computing platforms enable the effective use of deep learning-based neural decoders for neuroprosthesis control as an autonomous system. Significance: This work helps pioneer the deployment of deep neural networks in clinical applications underlying a new class of wearable biomedical devices with embedded artificial intelligence.
A Pilot Study of Text-to-SQL Semantic Parsing for Vietnamese
Oct 05, 2020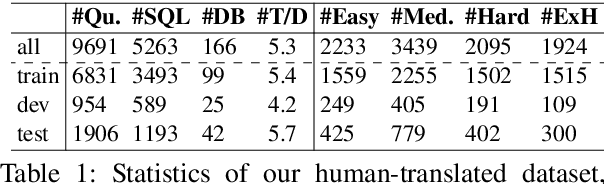

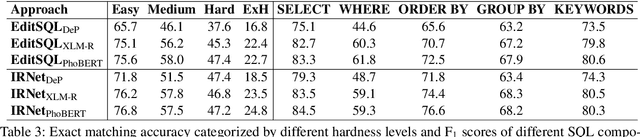
Semantic parsing is an important NLP task. However, Vietnamese is a low-resource language in this research area. In this paper, we present the first public large-scale Text-to-SQL semantic parsing dataset for Vietnamese. We extend and evaluate two strong semantic parsing baselines EditSQL (Zhang et al., 2019) and IRNet (Guo et al., 2019) on our dataset. We compare the two baselines with key configurations and find that: automatic Vietnamese word segmentation improves the parsing results of both baselines; the normalized pointwise mutual information (NPMI) score (Bouma, 2009) is useful for schema linking; latent syntactic features extracted from a neural dependency parser for Vietnamese also improve the results; and the monolingual language model PhoBERT for Vietnamese (Nguyen and Nguyen, 2020) helps produce higher performances than the recent best multilingual language model XLM-R (Conneau et al., 2020).
TATL at W-NUT 2020 Task 2: A Transformer-based Baseline System for Identification of Informative COVID-19 English Tweets
Aug 28, 2020

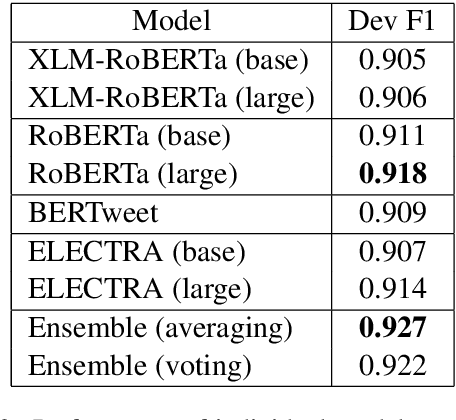

As the COVID-19 outbreak continues to spread throughout the world, more and more information about the pandemic has been shared publicly on social media. For example, there are a huge number of COVID-19 English Tweets daily on Twitter. However, the majority of those Tweets are uninformative, and hence it is important to be able to automatically select only the informative ones for downstream applications. In this short paper, we present our participation in the W-NUT 2020 Shared Task 2: Identification of Informative COVID-19 English Tweets. Inspired by the recent advances in pretrained Transformer language models, we propose a simple yet effective baseline for the task. Despite its simplicity, our proposed approach shows very competitive results in the leaderboard as we ranked 8 over 56 teams participated in total.