 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Disfluency Detection to Intent Detection and Slot Filling
Sep 17, 2022



We present the first empirical study investigating the influence of disfluency detection on downstream tasks of intent detection and slot filling. We perform this study for Vietnamese -- a low-resource language that has no previous study as well as no public dataset available for disfluency detection. First, we extend the fluent Vietnamese intent detection and slot filling dataset PhoATIS by manually adding contextual disfluencies and annotating them. Then, we conduct experiments using strong baselines for disfluency detection and joint intent detection and slot filling, which are based on pre-trained language models. We find that: (i) disfluencies produce negative effects on the performances of the downstream intent detection and slot filling tasks, and (ii) in the disfluency context, the pre-trained multilingual language model XLM-R helps produce better intent detection and slot filling performances than the pre-trained monolingual language model PhoBERT, and this is opposite to what generally found in the fluency context.
COVID-19 Named Entity Recognition for Vietnamese
Apr 08, 2021

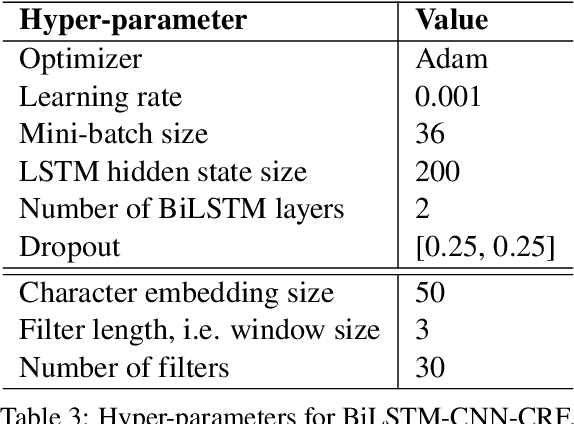
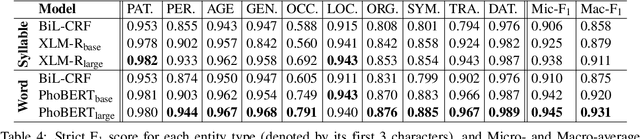
The current COVID-19 pandemic has lead to the creation of many corpora that facilitate NLP research and downstream applications to help fight the pandemic. However, most of these corpora are exclusively for English. As the pandemic is a global problem, it is worth creating COVID-19 related datasets for languages other than English. In this paper, we present the first manually-annotated COVID-19 domain-specific dataset for Vietnamese. Particularly, our dataset is annotated for the named entity recognition (NER) task with newly-defined entity types that can be used in other future epidemics. Our dataset also contains the largest number of entities compared to existing Vietnamese NER datasets. We empirically conduct experiments using strong baselines on our dataset, and find that: automatic Vietnamese word segmentation helps improve the NER results and the highest performances are obtained by fine-tuning pre-trained language models where the monolingual model PhoBERT for Vietnamese (Nguyen and Nguyen, 2020) produces higher results than the multilingual model XLM-R (Conneau et al., 2020). We publicly release our dataset at: https://github.com/VinAIResearch/PhoNER_COVID19
Intent detection and slot filling for Vietnamese
Apr 05, 2021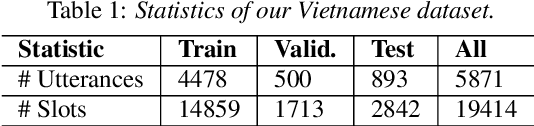
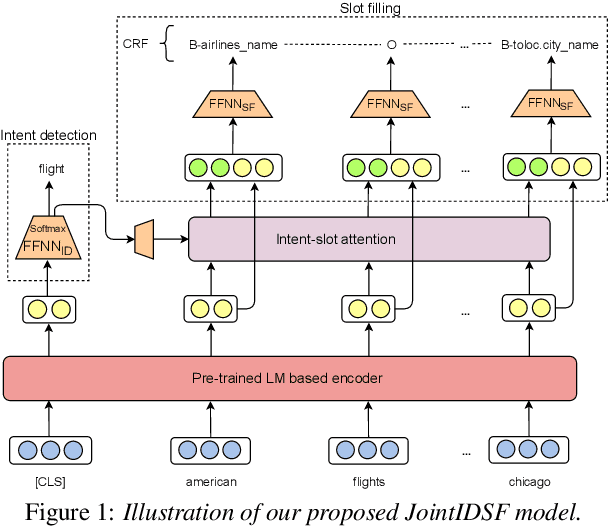


Intent detection and slot filling are important tasks in spoken and natural language understanding. However, Vietnamese is a low-resource language in these research topics. In this paper, we present the first public intent detection and slot filling dataset for Vietnamese. In addition, we also propose a joint model for intent detection and slot filling, that extends the recent state-of-the-art JointBERT+CRF model with an intent-slot attention layer in order to explicitly incorporate intent context information into slot filling via "soft" intent label embedding. Experimental results on our Vietnamese dataset show that our proposed model significantly outperforms JointBERT+CRF. We publicly release our dataset and the implementation of our model at: https://github.com/VinAIResearch/JointIDSF
WNUT-2020 Task 2: Identification of Informative COVID-19 English Tweets
Oct 16, 2020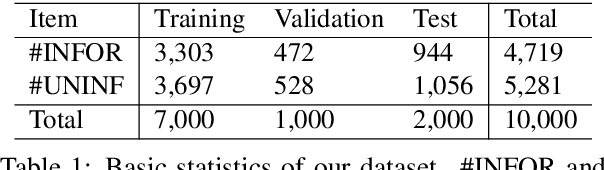
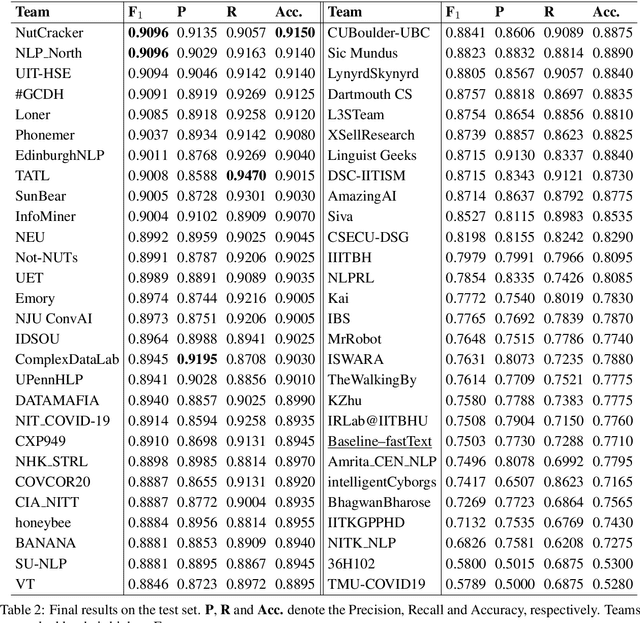
In this paper, we provide an overview of the WNUT-2020 shared task on the identification of informative COVID-19 English Tweets. We describe how we construct a corpus of 10K Tweets and organize the development and evaluation phases for this task. In addition, we also present a brief summary of results obtained from the final system evaluation submissions of 55 teams, finding that (i) many systems obtain very high performance, up to 0.91 F1 score, (ii) the majority of the submissions achieve substantially higher results than the baseline fastText (Joulin et al., 2017), and (iii) fine-tuning pre-trained language models on relevant language data followed by supervised training performs well in this task.
A Pilot Study of Text-to-SQL Semantic Parsing for Vietnamese
Oct 05, 2020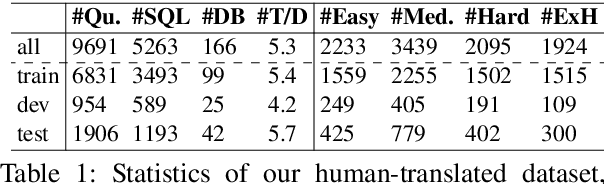

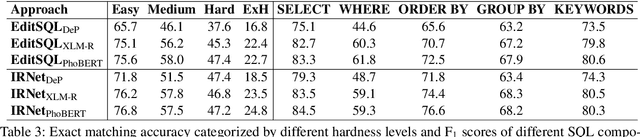
Semantic parsing is an important NLP task. However, Vietnamese is a low-resource language in this research area. In this paper, we present the first public large-scale Text-to-SQL semantic parsing dataset for Vietnamese. We extend and evaluate two strong semantic parsing baselines EditSQL (Zhang et al., 2019) and IRNet (Guo et al., 2019) on our dataset. We compare the two baselines with key configurations and find that: automatic Vietnamese word segmentation improves the parsing results of both baselines; the normalized pointwise mutual information (NPMI) score (Bouma, 2009) is useful for schema linking; latent syntactic features extracted from a neural dependency parser for Vietnamese also improve the results; and the monolingual language model PhoBERT for Vietnamese (Nguyen and Nguyen, 2020) helps produce higher performances than the recent best multilingual language model XLM-R (Conneau et al., 2020).