 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForecastGAN: A Decomposition-Based Adversarial Framework for Multi-Horizon Time Series Forecasting
Nov 06, 2025



Time series forecasting is essential across domains from finance to supply chain management. This paper introduces ForecastGAN, a novel decomposition based adversarial framework addressing limitations in existing approaches for multi-horizon predictions. Although transformer models excel in long-term forecasting, they often underperform in short-term scenarios and typically ignore categorical features. ForecastGAN operates through three integrated modules: a Decomposition Module that extracts seasonality and trend components; a Model Selection Module that identifies optimal neural network configurations based on forecasting horizon; and an Adversarial Training Module that enhances prediction robustness through Conditional Generative Adversarial Network training. Unlike conventional approaches, ForecastGAN effectively integrates both numerical and categorical features. We validate our framework on eleven benchmark multivariate time series datasets that span various forecasting horizons. The results show that ForecastGAN consistently outperforms state-of-the-art transformer models for short-term forecasting while remaining competitive for long-term horizons. This research establishes a more generalizable approach to time series forecasting that adapts to specific contexts while maintaining strong performance across diverse data characteristics without extensive hyperparameter tuning.
LayerMix: Enhanced Data Augmentation through Fractal Integration for Robust Deep Learning
Jan 08, 2025



Deep learning models have demonstrated remarkable performance across various computer vision tasks, yet their vulnerability to distribution shifts remains a critical challenge. Despite sophisticated neural network architectures, existing models often struggle to maintain consistent performance when confronted with Out-of-Distribution (OOD) samples, including natural corruptions, adversarial perturbations, and anomalous patterns. We introduce LayerMix, an innovative data augmentation approach that systematically enhances model robustness through structured fractal-based image synthesis. By meticulously integrating structural complexity into training datasets, our method generates semantically consistent synthetic samples that significantly improve neural network generalization capabilities. Unlike traditional augmentation techniques that rely on random transformations, LayerMix employs a structured mixing pipeline that preserves original image semantics while introducing controlled variability. Extensive experiments across multiple benchmark datasets, including CIFAR-10, CIFAR-100, ImageNet-200, and ImageNet-1K demonstrate LayerMixs superior performance in classification accuracy and substantially enhances critical Machine Learning (ML) safety metrics, including resilience to natural image corruptions, robustness against adversarial attacks, improved model calibration and enhanced prediction consistency. LayerMix represents a significant advancement toward developing more reliable and adaptable artificial intelligence systems by addressing the fundamental challenges of deep learning generalization. The code is available at https://github.com/ahmadmughees/layermix.
SH17: A Dataset for Human Safety and Personal Protective Equipment Detection in Manufacturing Industry
Jul 05, 2024
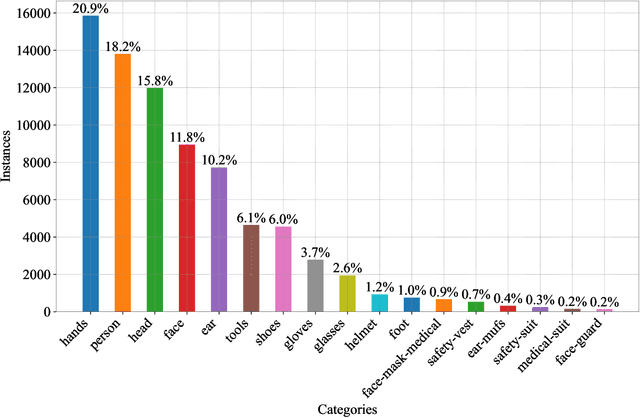
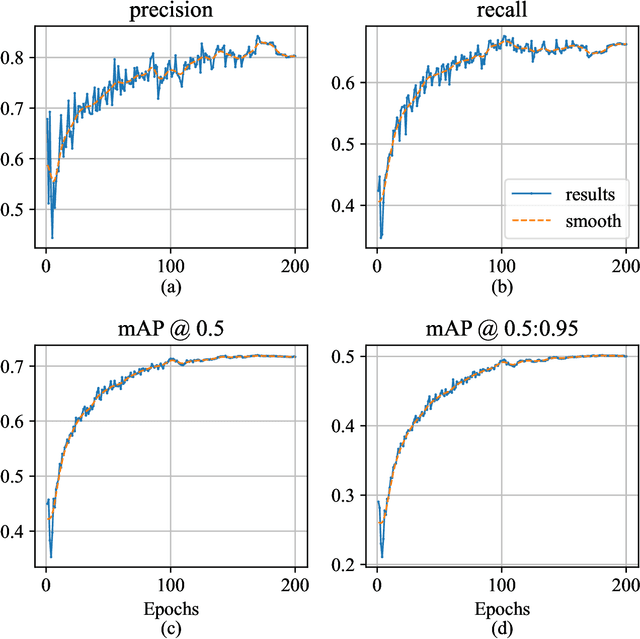
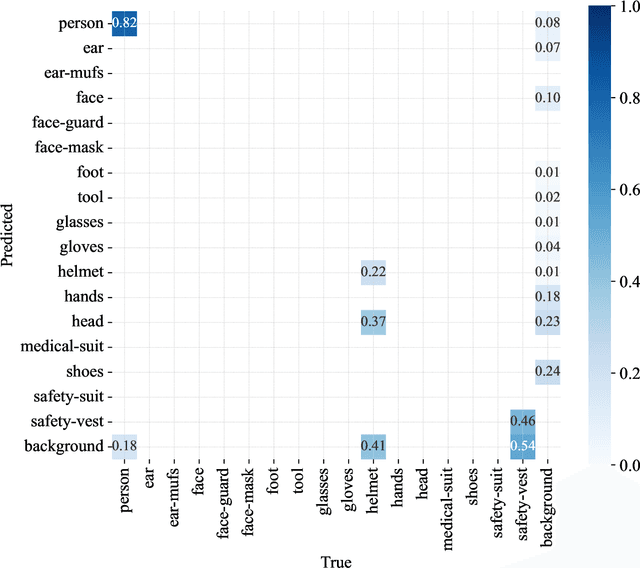
Workplace accidents continue to pose significant risks for human safety, particularly in industries such as construction and manufacturing, and the necessity for effective Personal Protective Equipment (PPE) compliance has become increasingly paramount. Our research focuses on the development of non-invasive techniques based on the Object Detection (OD) and Convolutional Neural Network (CNN) to detect and verify the proper use of various types of PPE such as helmets, safety glasses, masks, and protective clothing. This study proposes the SH17 Dataset, consisting of 8,099 annotated images containing 75,994 instances of 17 classes collected from diverse industrial environments, to train and validate the OD models. We have trained state-of-the-art OD models for benchmarking, and initial results demonstrate promising accuracy levels with You Only Look Once (YOLO)v9-e model variant exceeding 70.9% in PPE detection. The performance of the model validation on cross-domain datasets suggests that integrating these technologies can significantly improve safety management systems, providing a scalable and efficient solution for industries striving to meet human safety regulations and protect their workforce. The dataset is available at https://github.com/ahmadmughees/sh17dataset.
Capacity Constraint Analysis Using Object Detection for Smart Manufacturing
Jan 31, 2024The increasing popularity of Deep Learning (DL) based Object Detection (OD) methods and their real-world applications have opened new venues in smart manufacturing. Traditional industries struck by capacity constraints after Coronavirus Disease (COVID-19) require non-invasive methods for in-depth operations' analysis to optimize and increase their revenue. In this study, we have initially developed a Convolutional Neural Network (CNN) based OD model to tackle this issue. This model is trained to accurately identify the presence of chairs and individuals on the production floor. The identified objects are then passed to the CNN based tracker, which tracks them throughout their life cycle in the workstation. The extracted meta-data is further processed through a novel framework for the capacity constraint analysis. We identified that the Station C is only 70.6% productive through 6 months. Additionally, the time spent at each station is recorded and aggregated for each object. This data proves helpful in conducting annual audits and effectively managing labor and material over time.
Fairness-aware Class Imbalanced Learning
Sep 21, 2021



Class imbalance is a common challenge in many NLP tasks, and has clear connections to bias, in that bias in training data often leads to higher accuracy for majority groups at the expense of minority groups. However there has traditionally been a disconnect between research on class-imbalanced learning and mitigating bias, and only recently have the two been looked at through a common lens. In this work we evaluate long-tail learning methods for tweet sentiment and occupation classification, and extend a margin-loss based approach with methods to enforce fairness. We empirically show through controlled experiments that the proposed approaches help mitigate both class imbalance and demographic biases.
Learning Causal Bayesian Networks from Text
Nov 26, 2020
Causal relationships form the basis for reasoning and decision-making in Artificial Intelligence systems. To exploit the large volume of textual data available today, the automatic discovery of causal relationships from text has emerged as a significant challenge in recent years. Existing approaches in this realm are limited to the extraction of low-level relations among individual events. To overcome the limitations of the existing approaches, in this paper, we propose a method for automatic inference of causal relationships from human written language at conceptual level. To this end, we leverage the characteristics of hierarchy of concepts and linguistic variables created from text, and represent the extracted causal relationships in the form of a Causal Bayesian Network. Our experiments demonstrate superiority of our approach over the existing approaches in inferring complex causal reasoning from the text.
IndoLEM and IndoBERT: A Benchmark Dataset and Pre-trained Language Model for Indonesian NLP
Nov 02, 2020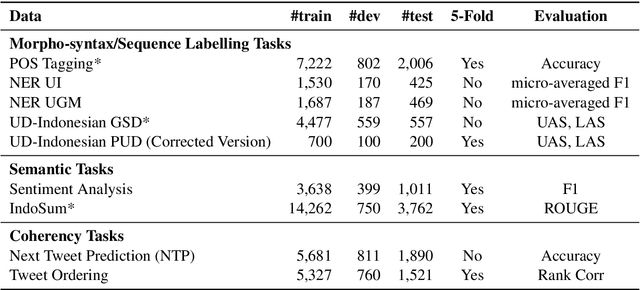
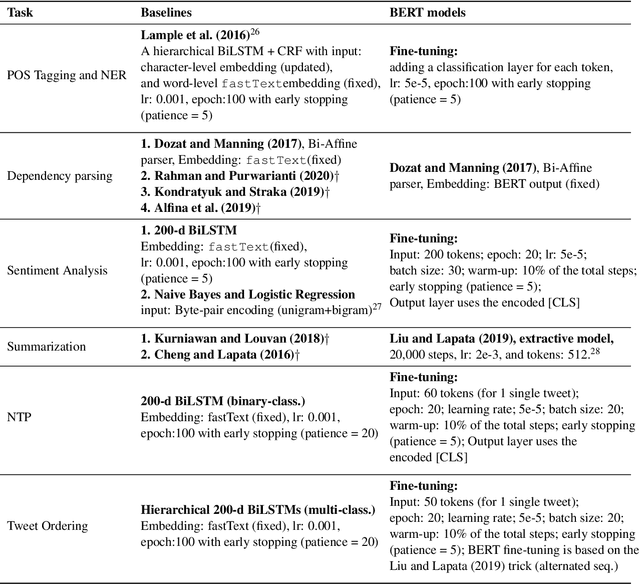
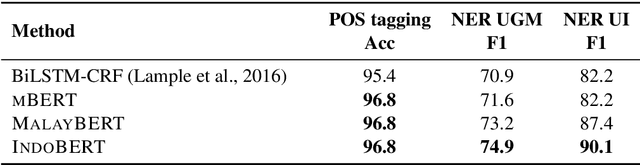
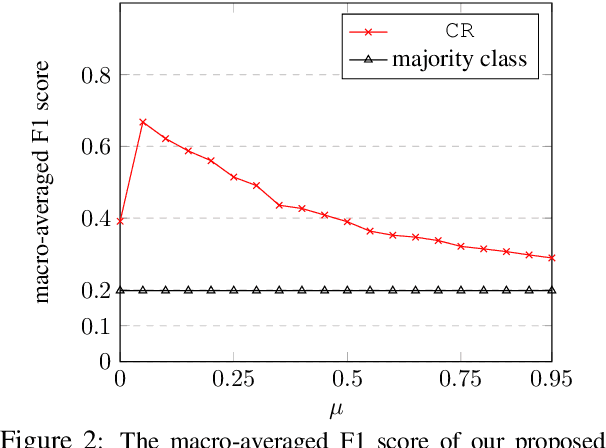
Although the Indonesian language is spoken by almost 200 million people and the 10th most spoken language in the world, it is under-represented in NLP research. Previous work on Indonesian has been hampered by a lack of annotated datasets, a sparsity of language resources, and a lack of resource standardization. In this work, we release the IndoLEM dataset comprising seven tasks for the Indonesian language, spanning morpho-syntax, semantics, and discourse. We additionally release IndoBERT, a new pre-trained language model for Indonesian, and evaluate it over IndoLEM, in addition to benchmarking it against existing resources. Our experiments show that IndoBERT achieves state-of-the-art performance over most of the tasks in IndoLEM.
WNUT-2020 Task 2: Identification of Informative COVID-19 English Tweets
Oct 16, 2020
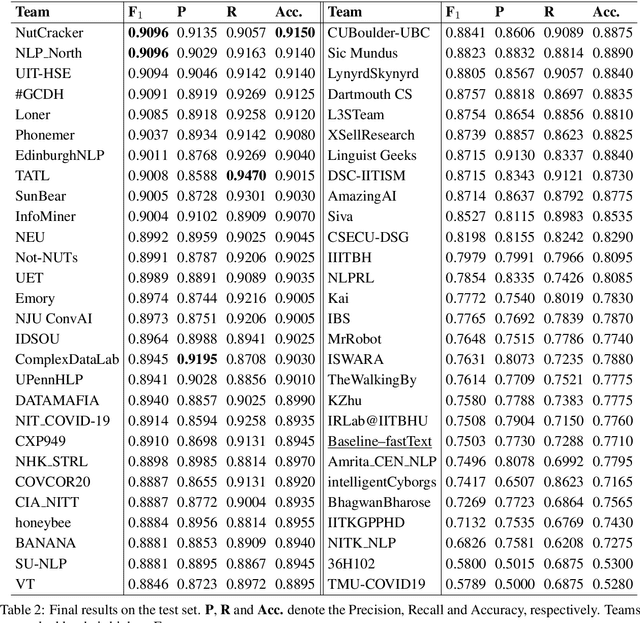
In this paper, we provide an overview of the WNUT-2020 shared task on the identification of informative COVID-19 English Tweets. We describe how we construct a corpus of 10K Tweets and organize the development and evaluation phases for this task. In addition, we also present a brief summary of results obtained from the final system evaluation submissions of 55 teams, finding that (i) many systems obtain very high performance, up to 0.91 F1 score, (ii) the majority of the submissions achieve substantially higher results than the baseline fastText (Joulin et al., 2017), and (iii) fine-tuning pre-trained language models on relevant language data followed by supervised training performs well in this task.
WikiUMLS: Aligning UMLS to Wikipedia via Cross-lingual Neural Ranking
May 08, 2020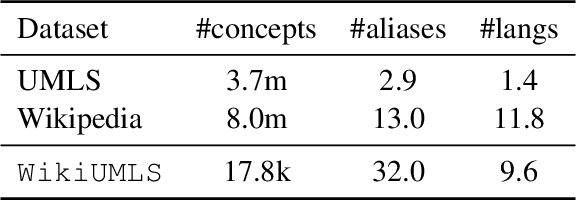
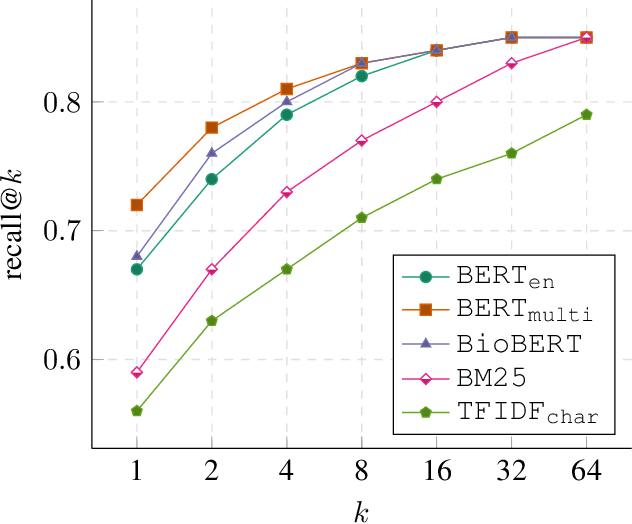

We present our work on aligning the Unified Medical Language System (UMLS) to Wikipedia, to facilitate manual alignment of the two resources. We propose a cross-lingual neural reranking model to match a UMLS concept with a Wikipedia page, which achieves a recall@1 of 71%, a substantial improvement of 20% over word- and char-level BM25, enabling manual alignment with minimal effort. We release our resources, including ranked Wikipedia pages for 700k UMLS concepts, and WikiUMLS, a dataset for training and evaluation of alignment models between UMLS and Wikipedia. This will provide easier access to Wikipedia for health professionals, patients, and NLP systems, including in multilingual settings.
Multilingual NER Transfer for Low-resource Languages
Feb 01, 2019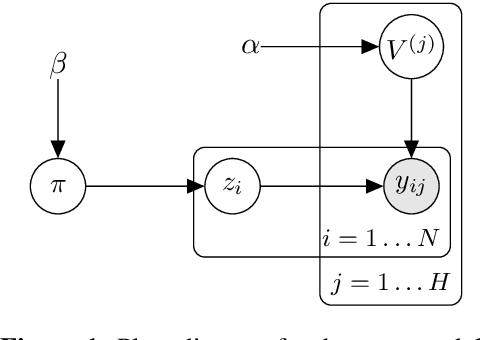


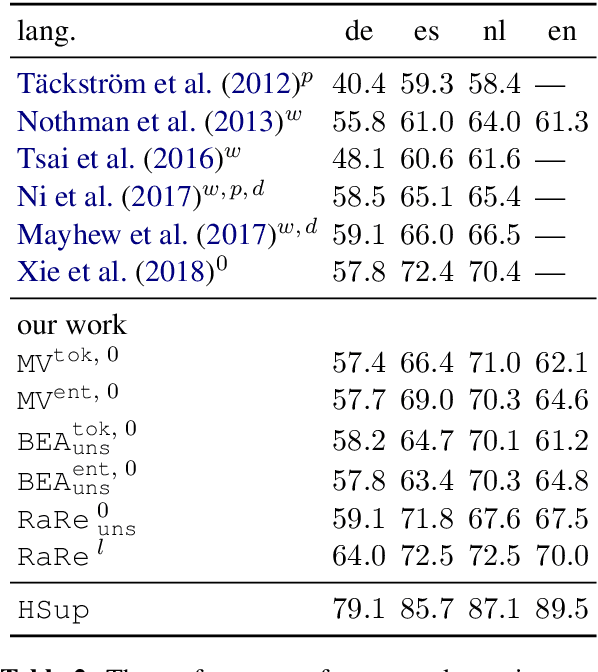
In massively multilingual transfer NLP models over many source languages are applied to a low-resource target language. In contrast to most prior work, which use a single model or a small handful, we consider many such models, which raises the critical problem of poor transfer, particularly from distant languages. We propose two techniques for modulating the transfer: one based on unsupervised truth inference, and another using limited supervision in the target language. Evaluating on named entity recognition over 41 languages, we show that our techniques are much more effective than strong baselines, including standard ensembling, and our unsupervised method rivals oracle selection of the single best individual model.