Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual NER Transfer for Low-resource Languages
Paper and Code
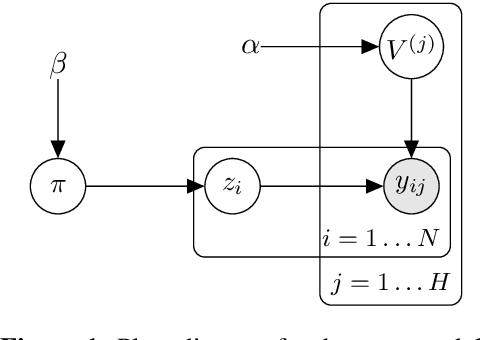


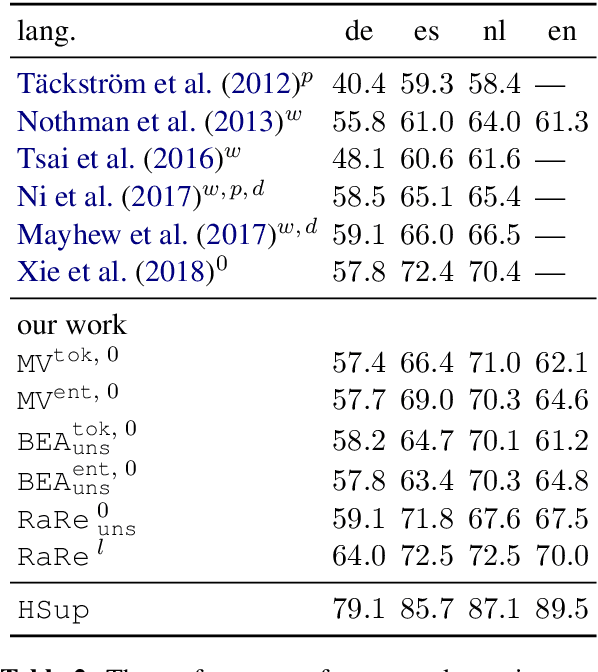
In massively multilingual transfer NLP models over many source languages are applied to a low-resource target language. In contrast to most prior work, which use a single model or a small handful, we consider many such models, which raises the critical problem of poor transfer, particularly from distant languages. We propose two techniques for modulating the transfer: one based on unsupervised truth inference, and another using limited supervision in the target language. Evaluating on named entity recognition over 41 languages, we show that our techniques are much more effective than strong baselines, including standard ensembling, and our unsupervised method rivals oracle selection of the single best individual model.
* The first and the second author have equally contributed to this work
View paper on