 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPEX-MEM: Agentic Semi-Structured Memory with Temporal Reasoning for Long-Term Conversational AI
Apr 15, 2026Large language models still struggle with reliable long-term conversational memory: simply enlarging context windows or applying naive retrieval often introduces noise and destabilizes responses. We present APEX-MEM, a conversational memory system that combines three key innovations: (1) a property graph which uses domain-agnostic ontology to structure conversations as temporally grounded events in an entity-centric framework, (2) append-only storage that preserves the full temporal evolution of information, and (3) a multi-tool retrieval agent that understands and resolves conflicting or evolving information at query time, producing a compact and contextually relevant memory summary. This retrieval-time resolution preserves the full interaction history while suppressing irrelevant details. APEX-MEM achieves 88.88% accuracy on LOCOMO's Question Answering task and 86.2% on LongMemEval, outperforming state-of-the-art session-aware approaches and demonstrating that structured property graphs enable more temporally coherent long-term conversational reasoning.
The Semantic Scholar Open Data Platform
Jan 24, 2023



The volume of scientific output is creating an urgent need for automated tools to help scientists keep up with developments in their field. Semantic Scholar (S2) is an open data platform and website aimed at accelerating science by helping scholars discover and understand scientific literature. We combine public and proprietary data sources using state-of-the-art techniques for scholarly PDF content extraction and automatic knowledge graph construction to build the Semantic Scholar Academic Graph, the largest open scientific literature graph to-date, with 200M+ papers, 80M+ authors, 550M+ paper-authorship edges, and 2.4B+ citation edges. The graph includes advanced semantic features such as structurally parsed text, natural language summaries, and vector embeddings. In this paper, we describe the components of the S2 data processing pipeline and the associated APIs offered by the platform. We will update this living document to reflect changes as we add new data offerings and improve existing services.
Fairness-aware Class Imbalanced Learning
Sep 21, 2021



Class imbalance is a common challenge in many NLP tasks, and has clear connections to bias, in that bias in training data often leads to higher accuracy for majority groups at the expense of minority groups. However there has traditionally been a disconnect between research on class-imbalanced learning and mitigating bias, and only recently have the two been looked at through a common lens. In this work we evaluate long-tail learning methods for tweet sentiment and occupation classification, and extend a margin-loss based approach with methods to enforce fairness. We empirically show through controlled experiments that the proposed approaches help mitigate both class imbalance and demographic biases.
Evaluating Debiasing Techniques for Intersectional Biases
Sep 21, 2021

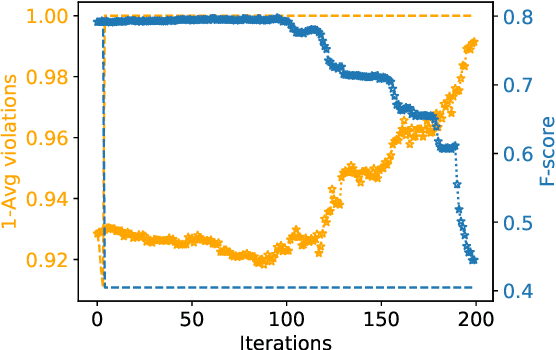
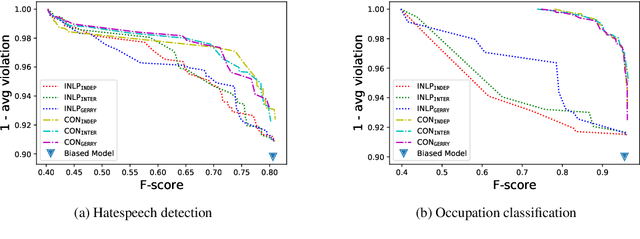
Bias is pervasive in NLP models, motivating the development of automatic debiasing techniques. Evaluation of NLP debiasing methods has largely been limited to binary attributes in isolation, e.g., debiasing with respect to binary gender or race, however many corpora involve multiple such attributes, possibly with higher cardinality. In this paper we argue that a truly fair model must consider `gerrymandering' groups which comprise not only single attributes, but also intersectional groups. We evaluate a form of bias-constrained model which is new to NLP, as well an extension of the iterative nullspace projection technique which can handle multiple protected attributes.
Drug Repurposing for Cancer: An NLP Approach to Identify Low-Cost Therapies
Dec 05, 2019

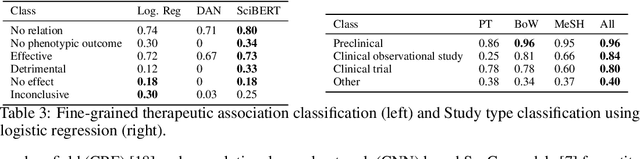
More than 200 generic drugs approved by the U.S. Food and Drug Administration for non-cancer indications have shown promise for treating cancer. Due to their long history of safe patient use, low cost, and widespread availability, repurposing of generic drugs represents a major opportunity to rapidly improve outcomes for cancer patients and reduce healthcare costs worldwide. Evidence on the efficacy of non-cancer generic drugs being tested for cancer exists in scientific publications, but trying to manually identify and extract such evidence is intractable. In this paper, we introduce a system to automate this evidence extraction from PubMed abstracts. Our primary contribution is to define the natural language processing pipeline required to obtain such evidence, comprising the following modules: querying, filtering, cancer type entity extraction, therapeutic association classification, and study type classification. Using the subject matter expertise on our team, we create our own datasets for these specialized domain-specific tasks. We obtain promising performance in each of the modules by utilizing modern language modeling techniques and plan to treat them as baseline approaches for future improvement of individual components.
Deep Ordinal Regression for Pledge Specificity Prediction
Aug 31, 2019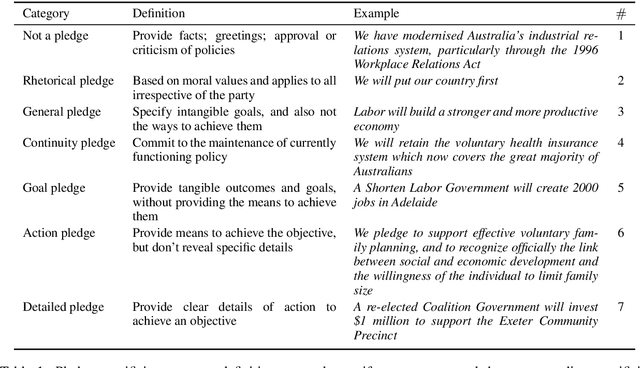
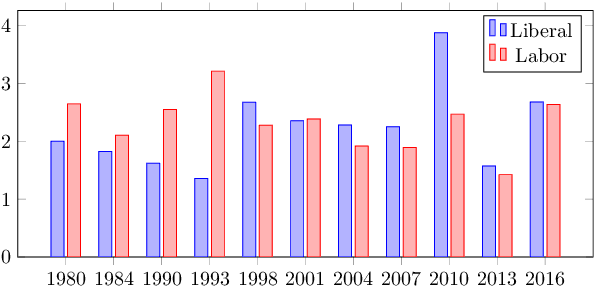


Many pledges are made in the course of an election campaign, forming important corpora for political analysis of campaign strategy and governmental accountability. At present, there are no publicly available annotated datasets of pledges, and most political analyses rely on manual analysis. In this paper we collate a novel dataset of manifestos from eleven Australian federal election cycles, with over 12,000 sentences annotated with specificity (e.g., rhetorical vs.\ detailed pledge) on a fine-grained scale. We propose deep ordinal regression approaches for specificity prediction, under both supervised and semi-supervised settings, and provide empirical results demonstrating the effectiveness of the proposed techniques over several baseline approaches. We analyze the utility of pledge specificity modeling across a spectrum of policy issues in performing ideology prediction, and further provide qualitative analysis in terms of capturing party-specific issue salience across election cycles.
Target Based Speech Act Classification in Political Campaign Text
May 20, 2019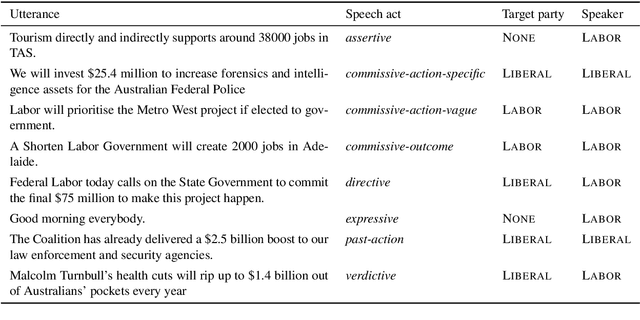
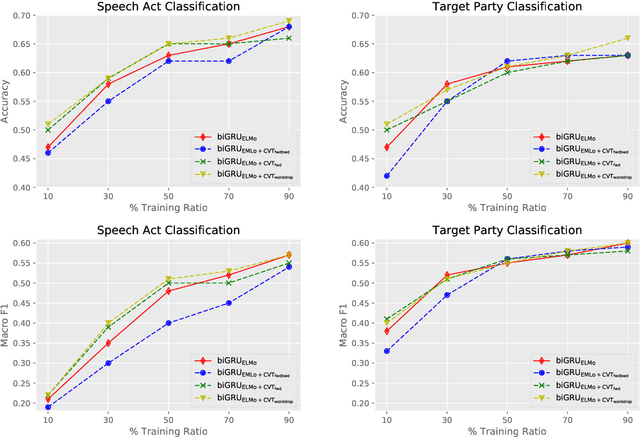

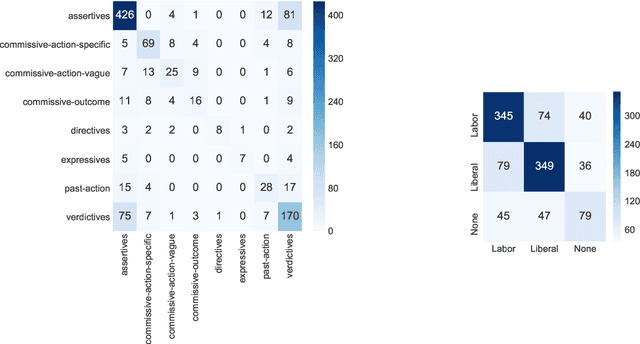
We study pragmatics in political campaign text, through analysis of speech acts and the target of each utterance. We propose a new annotation schema incorporating domain-specific speech acts, such as commissive-action, and present a novel annotated corpus of media releases and speech transcripts from the 2016 Australian election cycle. We show how speech acts and target referents can be modeled as sequential classification, and evaluate several techniques, exploiting contextualized word representations, semi-supervised learning, task dependencies and speaker meta-data.
Content-based Popularity Prediction of Online Petitions Using a Deep Regression Model
May 17, 2018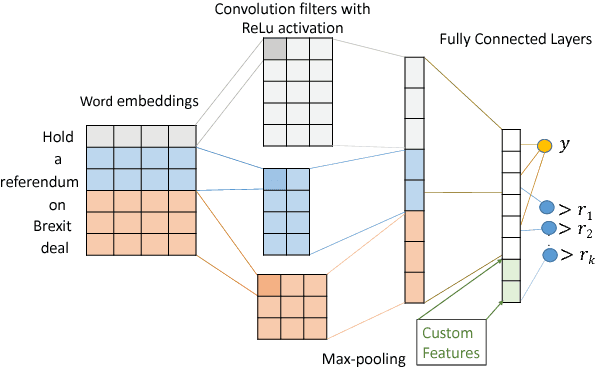
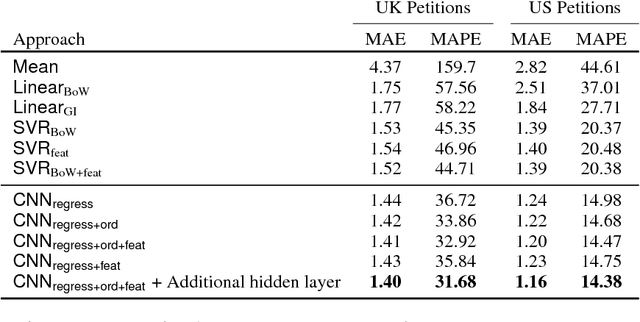
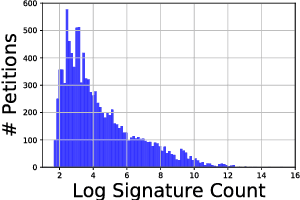

Online petitions are a cost-effective way for citizens to collectively engage with policy-makers in a democracy. Predicting the popularity of a petition --- commonly measured by its signature count --- based on its textual content has utility for policy-makers as well as those posting the petition. In this work, we model this task using CNN regression with an auxiliary ordinal regression objective. We demonstrate the effectiveness of our proposed approach using UK and US government petition datasets.
Hierarchical Structured Model for Fine-to-coarse Manifesto Text Analysis
May 08, 2018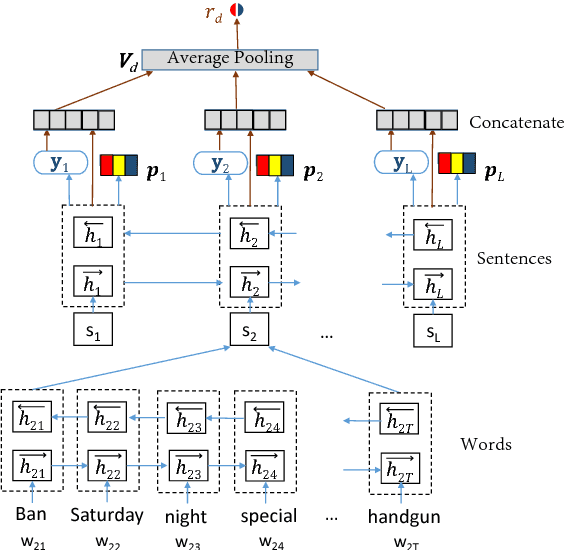
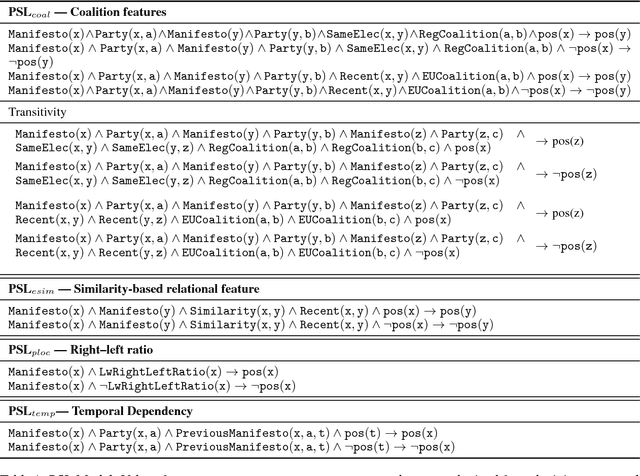
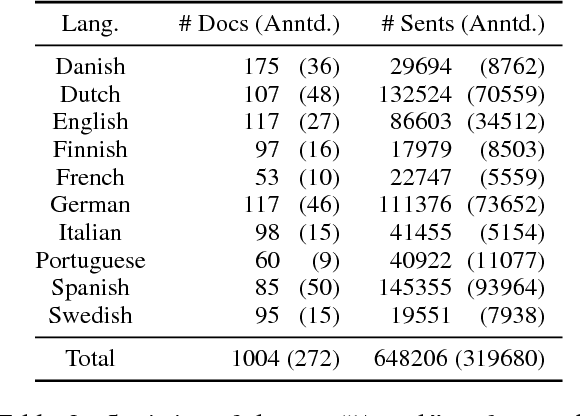
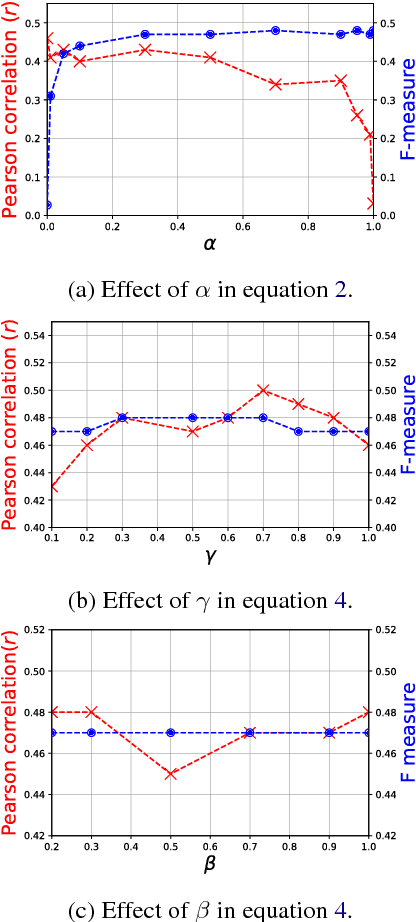
Election manifestos document the intentions, motives, and views of political parties. They are often used for analysing a party's fine-grained position on a particular issue, as well as for coarse-grained positioning of a party on the left--right spectrum. In this paper we propose a two-stage model for automatically performing both levels of analysis over manifestos. In the first step we employ a hierarchical multi-task structured deep model to predict fine- and coarse-grained positions, and in the second step we perform post-hoc calibration of coarse-grained positions using probabilistic soft logic. We empirically show that the proposed model outperforms state-of-art approaches at both granularities using manifestos from twelve countries, written in ten different languages.