 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDrug Repurposing for Cancer: An NLP Approach to Identify Low-Cost Therapies
Dec 05, 2019

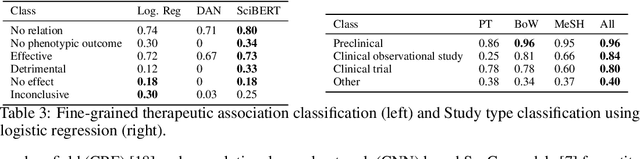
More than 200 generic drugs approved by the U.S. Food and Drug Administration for non-cancer indications have shown promise for treating cancer. Due to their long history of safe patient use, low cost, and widespread availability, repurposing of generic drugs represents a major opportunity to rapidly improve outcomes for cancer patients and reduce healthcare costs worldwide. Evidence on the efficacy of non-cancer generic drugs being tested for cancer exists in scientific publications, but trying to manually identify and extract such evidence is intractable. In this paper, we introduce a system to automate this evidence extraction from PubMed abstracts. Our primary contribution is to define the natural language processing pipeline required to obtain such evidence, comprising the following modules: querying, filtering, cancer type entity extraction, therapeutic association classification, and study type classification. Using the subject matter expertise on our team, we create our own datasets for these specialized domain-specific tasks. We obtain promising performance in each of the modules by utilizing modern language modeling techniques and plan to treat them as baseline approaches for future improvement of individual components.