 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetection and Classification of mental illnesses on social media using RoBERTa
Nov 23, 2020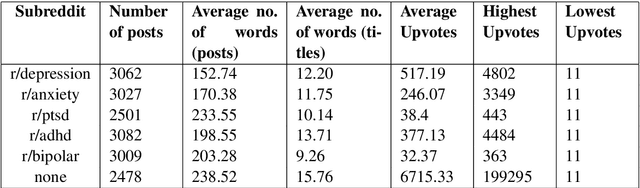
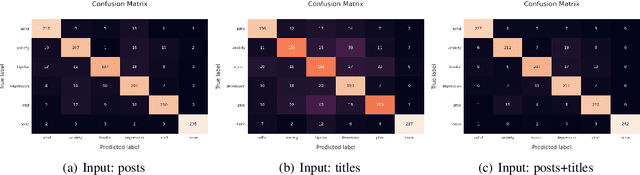

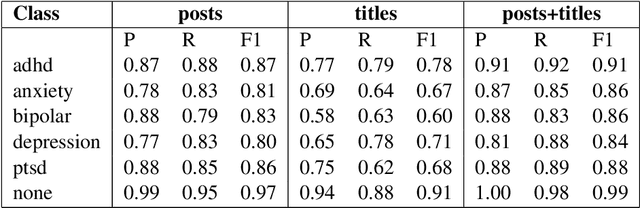
Given the current social distancing regulations across the world, social media has become the primary mode of communication for most people. This has resulted in the isolation of many people suffering from mental illnesses who are unable to receive assistance in person. They have increasingly turned to social media to express themselves and to look for guidance in dealing with their illnesses. Keeping this in mind, we propose a solution to detect and classify mental illness posts on social media thereby enabling users to seek appropriate help. In this work, we detect and classify five prominent kinds of mental illnesses: depression, anxiety, bipolar disorder, ADHD and PTSD by analyzing unstructured user data on social media platforms. In addition, we are sharing a new high-quality dataset to drive research on this topic. We believe that our work is the first multi-class model that uses a Transformer-based architecture such as RoBERTa to analyze people's emotions and psychology. We also demonstrate how we stress-test our model using behavioral testing. With this research, we hope to be able to contribute to the public health system by automating some of the detection and classification process.
Drug Repurposing for Cancer: An NLP Approach to Identify Low-Cost Therapies
Dec 05, 2019

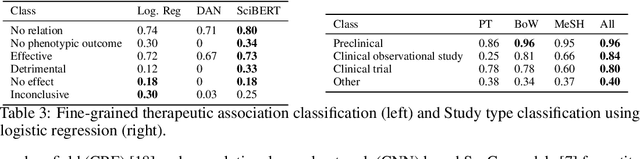
More than 200 generic drugs approved by the U.S. Food and Drug Administration for non-cancer indications have shown promise for treating cancer. Due to their long history of safe patient use, low cost, and widespread availability, repurposing of generic drugs represents a major opportunity to rapidly improve outcomes for cancer patients and reduce healthcare costs worldwide. Evidence on the efficacy of non-cancer generic drugs being tested for cancer exists in scientific publications, but trying to manually identify and extract such evidence is intractable. In this paper, we introduce a system to automate this evidence extraction from PubMed abstracts. Our primary contribution is to define the natural language processing pipeline required to obtain such evidence, comprising the following modules: querying, filtering, cancer type entity extraction, therapeutic association classification, and study type classification. Using the subject matter expertise on our team, we create our own datasets for these specialized domain-specific tasks. We obtain promising performance in each of the modules by utilizing modern language modeling techniques and plan to treat them as baseline approaches for future improvement of individual components.