 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometry-Guided Self-Supervision for Ultra-Fine-Grained Recognition with Limited Data
Apr 21, 2026This paper investigates the intrinsic geometrical features of highly similar objects and introduces a general self-supervised framework called the Geometric Attribute Exploration Network (GAEor), which is designed to address the ultra-fine-grained visual categorization (Ultra-FGVC) task in data-limited scenarios. Unlike prior work that often captures subtle yet critical distinctions, GAEor generates geometric attributes as novel alternative recognition cues. These attributes are determined by various details within the object, aligned with its geometric patterns, such as the intricate vein structures in soybean leaves. Crucially, each category exhibits distinct geometric descriptors that serve as powerful cues, even among objects with minimal visual variation -- a factor largely overlooked in recent research. GAEor discovers these geometric attributes by first amplifying geometry-relevant details via visual feedback from a backbone network, then embedding the relative polar coordinates of these details into the final representation. Extensive experiments demonstrate that GAEor significantly sets new state-of-the-art records in five widely-used Ultra-FGVC benchmarks.
Divide-and-Conquer Approach to Holistic Cognition in High-Similarity Contexts with Limited Data
Apr 21, 2026Ultra-fine-grained visual categorization (Ultra-FGVC) aims to classify highly similar subcategories within fine-grained objects using limited training samples. However, holistic yet discriminative cues, such as leaf contours in extremely similar cultivars, remain under-explored in current studies, thereby limiting recognition performance. Though crucial, modeling holistic cues with complex morphological structures typically requires massive training samples, posing significant challenges in data-limited scenarios. To address this challenge, we propose a novel Divide-and-Conquer Holistic Cognition Network (DHCNet) that implements a divide-and-conquer strategy by decomposing holistic cues into spatially-associated subtle discrepancies and progressively establishing the holistic cognition process, significantly simplifying holistic cognition while reducing dependency on training data. Technically, DHCNet begins by progressively analyzing subtle discrepancies, transitioning from smaller local patches to larger ones using a self-shuffling operation on local regions. Simultaneously, it leverages the unaffected local regions to potentially guide the perception of the original topological structure among the shuffled patches, thereby aiding in the establishment of spatial associations for these discrepancies. Additionally, DHCNet incorporates the online refinement of these holistic cues discovered from local regions into the training process to iteratively improve their quality. As a result, DHCNet uses these holistic cues as supervisory signals to fine-tune the parameters of the recognition model, thus improving its sensitivity to holistic cues across the entire objects. Extensive evaluations demonstrate that DHCNet achieves remarkable performance on five widely-used Ultra-FGVC datasets.
Minimal Semantic Sufficiency Meets Unsupervised Domain Generalization
Sep 19, 2025The generalization ability of deep learning has been extensively studied in supervised settings, yet it remains less explored in unsupervised scenarios. Recently, the Unsupervised Domain Generalization (UDG) task has been proposed to enhance the generalization of models trained with prevalent unsupervised learning techniques, such as Self-Supervised Learning (SSL). UDG confronts the challenge of distinguishing semantics from variations without category labels. Although some recent methods have employed domain labels to tackle this issue, such domain labels are often unavailable in real-world contexts. In this paper, we address these limitations by formalizing UDG as the task of learning a Minimal Sufficient Semantic Representation: a representation that (i) preserves all semantic information shared across augmented views (sufficiency), and (ii) maximally removes information irrelevant to semantics (minimality). We theoretically ground these objectives from the perspective of information theory, demonstrating that optimizing representations to achieve sufficiency and minimality directly reduces out-of-distribution risk. Practically, we implement this optimization through Minimal-Sufficient UDG (MS-UDG), a learnable model by integrating (a) an InfoNCE-based objective to achieve sufficiency; (b) two complementary components to promote minimality: a novel semantic-variation disentanglement loss and a reconstruction-based mechanism for capturing adequate variation. Empirically, MS-UDG sets a new state-of-the-art on popular unsupervised domain-generalization benchmarks, consistently outperforming existing SSL and UDG methods, without category or domain labels during representation learning.
ALSA: Anchors in Logit Space for Out-of-Distribution Accuracy Estimation
Aug 27, 2025Estimating model accuracy on unseen, unlabeled datasets is crucial for real-world machine learning applications, especially under distribution shifts that can degrade performance. Existing methods often rely on predicted class probabilities (softmax scores) or data similarity metrics. While softmax-based approaches benefit from representing predictions on the standard simplex, compressing logits into probabilities leads to information loss. Meanwhile, similarity-based methods can be computationally expensive and domain-specific, limiting their broader applicability. In this paper, we introduce ALSA (Anchors in Logit Space for Accuracy estimation), a novel framework that preserves richer information by operating directly in the logit space. Building on theoretical insights and empirical observations, we demonstrate that the aggregation and distribution of logits exhibit a strong correlation with the predictive performance of the model. To exploit this property, ALSA employs an anchor-based modeling strategy: multiple learnable anchors are initialized in logit space, each assigned an influence function that captures subtle variations in the logits. This allows ALSA to provide robust and accurate performance estimates across a wide range of distribution shifts. Extensive experiments on vision, language, and graph benchmarks demonstrate ALSA's superiority over both softmax- and similarity-based baselines. Notably, ALSA's robustness under significant distribution shifts highlights its potential as a practical tool for reliable model evaluation.
GIQ: Benchmarking 3D Geometric Reasoning of Vision Foundation Models with Simulated and Real Polyhedra
Jun 11, 2025
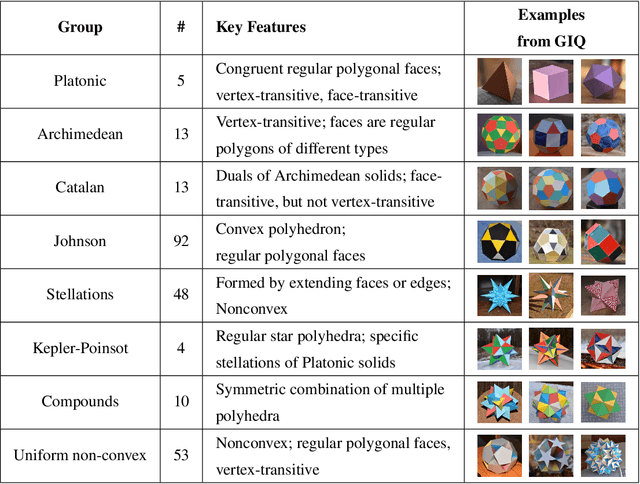
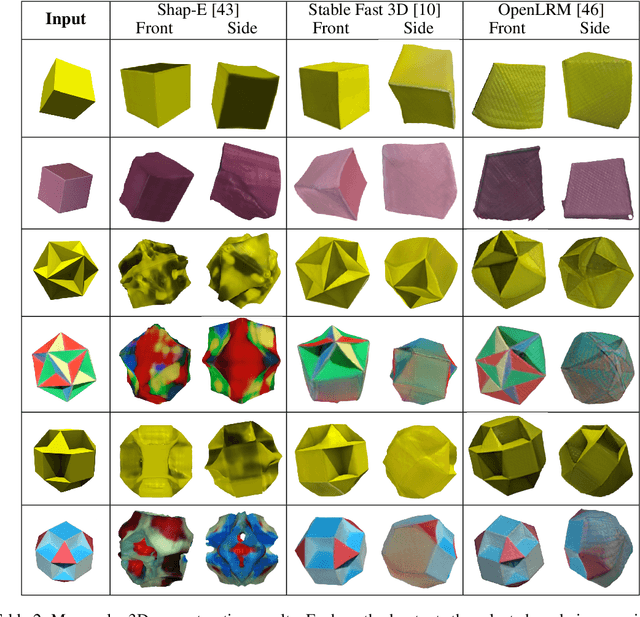
Monocular 3D reconstruction methods and vision-language models (VLMs) demonstrate impressive results on standard benchmarks, yet their true understanding of geometric properties remains unclear. We introduce GIQ , a comprehensive benchmark specifically designed to evaluate the geometric reasoning capabilities of vision and vision-language foundation models. GIQ comprises synthetic and real-world images of 224 diverse polyhedra - including Platonic, Archimedean, Johnson, and Catalan solids, as well as stellations and compound shapes - covering varying levels of complexity and symmetry. Through systematic experiments involving monocular 3D reconstruction, 3D symmetry detection, mental rotation tests, and zero-shot shape classification tasks, we reveal significant shortcomings in current models. State-of-the-art reconstruction algorithms trained on extensive 3D datasets struggle to reconstruct even basic geometric forms accurately. While foundation models effectively detect specific 3D symmetry elements via linear probing, they falter significantly in tasks requiring detailed geometric differentiation, such as mental rotation. Moreover, advanced vision-language assistants exhibit remarkably low accuracy on complex polyhedra, systematically misinterpreting basic properties like face geometry, convexity, and compound structures. GIQ is publicly available, providing a structured platform to highlight and address critical gaps in geometric intelligence, facilitating future progress in robust, geometry-aware representation learning.
WisWheat: A Three-Tiered Vision-Language Dataset for Wheat Management
Jun 06, 2025Wheat management strategies play a critical role in determining yield. Traditional management decisions often rely on labour-intensive expert inspections, which are expensive, subjective and difficult to scale. Recently, Vision-Language Models (VLMs) have emerged as a promising solution to enable scalable, data-driven management support. However, due to a lack of domain-specific knowledge, directly applying VLMs to wheat management tasks results in poor quantification and reasoning capabilities, ultimately producing vague or even misleading management recommendations. In response, we propose WisWheat, a wheat-specific dataset with a three-layered design to enhance VLM performance on wheat management tasks: (1) a foundational pretraining dataset of 47,871 image-caption pairs for coarsely adapting VLMs to wheat morphology; (2) a quantitative dataset comprising 7,263 VQA-style image-question-answer triplets for quantitative trait measuring tasks; and (3) an Instruction Fine-tuning dataset with 4,888 samples targeting biotic and abiotic stress diagnosis and management plan for different phenological stages. Extensive experimental results demonstrate that fine-tuning open-source VLMs (e.g., Qwen2.5 7B) on our dataset leads to significant performance improvements. Specifically, the Qwen2.5 VL 7B fine-tuned on our wheat instruction dataset achieves accuracy scores of 79.2% and 84.6% on wheat stress and growth stage conversation tasks respectively, surpassing even general-purpose commercial models such as GPT-4o by a margin of 11.9% and 34.6%.
SD-MAD: Sign-Driven Few-shot Multi-Anomaly Detection in Medical Images
May 22, 2025Medical anomaly detection (AD) is crucial for early clinical intervention, yet it faces challenges due to limited access to high-quality medical imaging data, caused by privacy concerns and data silos. Few-shot learning has emerged as a promising approach to alleviate these limitations by leveraging the large-scale prior knowledge embedded in vision-language models (VLMs). Recent advancements in few-shot medical AD have treated normal and abnormal cases as a one-class classification problem, often overlooking the distinction among multiple anomaly categories. Thus, in this paper, we propose a framework tailored for few-shot medical anomaly detection in the scenario where the identification of multiple anomaly categories is required. To capture the detailed radiological signs of medical anomaly categories, our framework incorporates diverse textual descriptions for each category generated by a Large-Language model, under the assumption that different anomalies in medical images may share common radiological signs in each category. Specifically, we introduce SD-MAD, a two-stage Sign-Driven few-shot Multi-Anomaly Detection framework: (i) Radiological signs are aligned with anomaly categories by amplifying inter-anomaly discrepancy; (ii) Aligned signs are selected further to mitigate the effect of the under-fitting and uncertain-sample issue caused by limited medical data, employing an automatic sign selection strategy at inference. Moreover, we propose three protocols to comprehensively quantify the performance of multi-anomaly detection. Extensive experiments illustrate the effectiveness of our method.
Benchmarking Transferability: A Framework for Fair and Robust Evaluation
Apr 28, 2025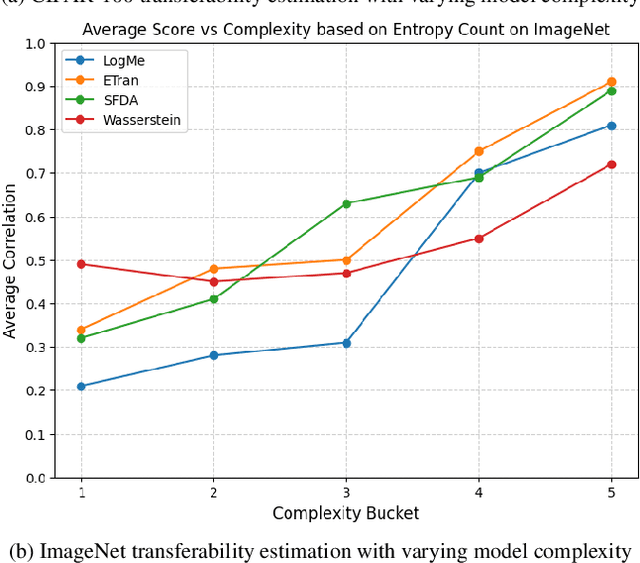


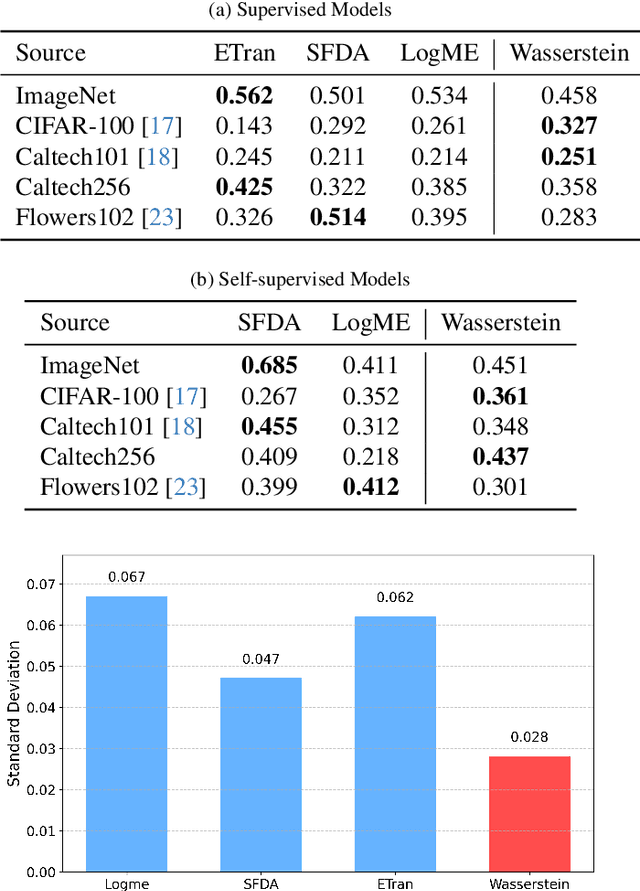
Transferability scores aim to quantify how well a model trained on one domain generalizes to a target domain. Despite numerous methods proposed for measuring transferability, their reliability and practical usefulness remain inconclusive, often due to differing experimental setups, datasets, and assumptions. In this paper, we introduce a comprehensive benchmarking framework designed to systematically evaluate transferability scores across diverse settings. Through extensive experiments, we observe variations in how different metrics perform under various scenarios, suggesting that current evaluation practices may not fully capture each method's strengths and limitations. Our findings underscore the value of standardized assessment protocols, paving the way for more reliable transferability measures and better-informed model selection in cross-domain applications. Additionally, we achieved a 3.5\% improvement using our proposed metric for the head-training fine-tuning experimental setup. Our code is available in this repository: https://github.com/alizkzm/pert_robust_platform.
Feature Space Perturbation: A Panacea to Enhanced Transferability Estimation
Feb 23, 2025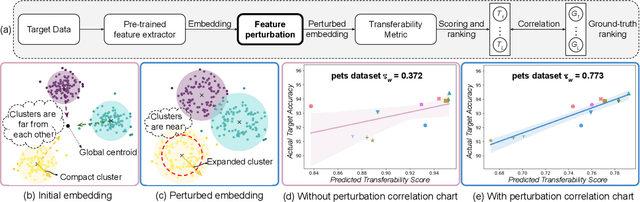
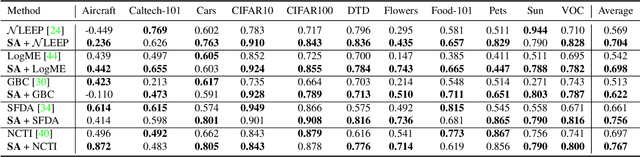

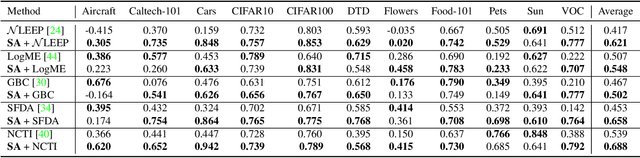
Leveraging a transferability estimation metric facilitates the non-trivial challenge of selecting the optimal model for the downstream task from a pool of pre-trained models. Most existing metrics primarily focus on identifying the statistical relationship between feature embeddings and the corresponding labels within the target dataset, but overlook crucial aspect of model robustness. This oversight may limit their effectiveness in accurately ranking pre-trained models. To address this limitation, we introduce a feature perturbation method that enhances the transferability estimation process by systematically altering the feature space. Our method includes a Spread operation that increases intra-class variability, adding complexity within classes, and an Attract operation that minimizes the distances between different classes, thereby blurring the class boundaries. Through extensive experimentation, we demonstrate the efficacy of our feature perturbation method in providing a more precise and robust estimation of model transferability. Notably, the existing LogMe method exhibited a significant improvement, showing a 28.84% increase in performance after applying our feature perturbation method.
Not all Views are Created Equal: Analyzing Viewpoint Instabilities in Vision Foundation Models
Dec 27, 2024



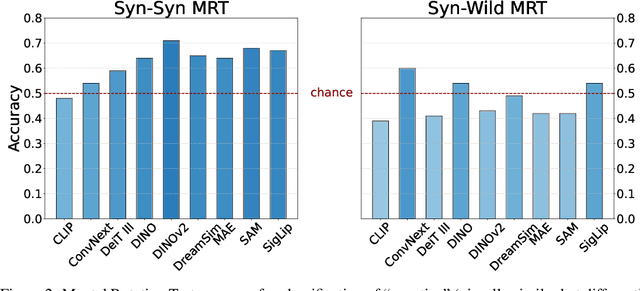
In this paper, we analyze the viewpoint stability of foundational models - specifically, their sensitivity to changes in viewpoint- and define instability as significant feature variations resulting from minor changes in viewing angle, leading to generalization gaps in 3D reasoning tasks. We investigate nine foundational models, focusing on their responses to viewpoint changes, including the often-overlooked accidental viewpoints where specific camera orientations obscure an object's true 3D structure. Our methodology enables recognizing and classifying out-of-distribution (OOD), accidental, and stable viewpoints using feature representations alone, without accessing the actual images. Our findings indicate that while foundation models consistently encode accidental viewpoints, they vary in their interpretation of OOD viewpoints due to inherent biases, at times leading to object misclassifications based on geometric resemblance. Through quantitative and qualitative evaluations on three downstream tasks - classification, VQA, and 3D reconstruction - we illustrate the impact of viewpoint instability and underscore the importance of feature robustness across diverse viewing conditions.