 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTracing the Heart's Pathways: ECG Representation Learning from a Cardiac Conduction Perspective
Dec 30, 2025The multi-lead electrocardiogram (ECG) stands as a cornerstone of cardiac diagnosis. Recent strides in electrocardiogram self-supervised learning (eSSL) have brightened prospects for enhancing representation learning without relying on high-quality annotations. Yet earlier eSSL methods suffer a key limitation: they focus on consistent patterns across leads and beats, overlooking the inherent differences in heartbeats rooted in cardiac conduction processes, while subtle but significant variations carry unique physiological signatures. Moreover, representation learning for ECG analysis should align with ECG diagnostic guidelines, which progress from individual heartbeats to single leads and ultimately to lead combinations. This sequential logic, however, is often neglected when applying pre-trained models to downstream tasks. To address these gaps, we propose CLEAR-HUG, a two-stage framework designed to capture subtle variations in cardiac conduction across leads while adhering to ECG diagnostic guidelines. In the first stage, we introduce an eSSL model termed Conduction-LEAd Reconstructor (CLEAR), which captures both specific variations and general commonalities across heartbeats. Treating each heartbeat as a distinct entity, CLEAR employs a simple yet effective sparse attention mechanism to reconstruct signals without interference from other heartbeats. In the second stage, we implement a Hierarchical lead-Unified Group head (HUG) for disease diagnosis, mirroring clinical workflow. Experimental results across six tasks show a 6.84% improvement, validating the effectiveness of CLEAR-HUG. This highlights its ability to enhance representations of cardiac conduction and align patterns with expert diagnostic guidelines.
Minimal Semantic Sufficiency Meets Unsupervised Domain Generalization
Sep 19, 2025The generalization ability of deep learning has been extensively studied in supervised settings, yet it remains less explored in unsupervised scenarios. Recently, the Unsupervised Domain Generalization (UDG) task has been proposed to enhance the generalization of models trained with prevalent unsupervised learning techniques, such as Self-Supervised Learning (SSL). UDG confronts the challenge of distinguishing semantics from variations without category labels. Although some recent methods have employed domain labels to tackle this issue, such domain labels are often unavailable in real-world contexts. In this paper, we address these limitations by formalizing UDG as the task of learning a Minimal Sufficient Semantic Representation: a representation that (i) preserves all semantic information shared across augmented views (sufficiency), and (ii) maximally removes information irrelevant to semantics (minimality). We theoretically ground these objectives from the perspective of information theory, demonstrating that optimizing representations to achieve sufficiency and minimality directly reduces out-of-distribution risk. Practically, we implement this optimization through Minimal-Sufficient UDG (MS-UDG), a learnable model by integrating (a) an InfoNCE-based objective to achieve sufficiency; (b) two complementary components to promote minimality: a novel semantic-variation disentanglement loss and a reconstruction-based mechanism for capturing adequate variation. Empirically, MS-UDG sets a new state-of-the-art on popular unsupervised domain-generalization benchmarks, consistently outperforming existing SSL and UDG methods, without category or domain labels during representation learning.
Exploiting Layer Normalization Fine-tuning in Visual Transformer Foundation Models for Classification
Aug 11, 2025LayerNorm is pivotal in Vision Transformers (ViTs), yet its fine-tuning dynamics under data scarcity and domain shifts remain underexplored. This paper shows that shifts in LayerNorm parameters after fine-tuning (LayerNorm shifts) are indicative of the transitions between source and target domains; its efficacy is contingent upon the degree to which the target training samples accurately represent the target domain, as quantified by our proposed Fine-tuning Shift Ratio ($FSR$). Building on this, we propose a simple yet effective rescaling mechanism using a scalar $\lambda$ that is negatively correlated to $FSR$ to align learned LayerNorm shifts with those ideal shifts achieved under fully representative data, combined with a cyclic framework that further enhances the LayerNorm fine-tuning. Extensive experiments across natural and pathological images, in both in-distribution (ID) and out-of-distribution (OOD) settings, and various target training sample regimes validate our framework. Notably, OOD tasks tend to yield lower $FSR$ and higher $\lambda$ in comparison to ID cases, especially with scarce data, indicating under-represented target training samples. Moreover, ViTFs fine-tuned on pathological data behave more like ID settings, favoring conservative LayerNorm updates. Our findings illuminate the underexplored dynamics of LayerNorm in transfer learning and provide practical strategies for LayerNorm fine-tuning.
Structure-aware Semantic Discrepancy and Consistency for 3D Medical Image Self-supervised Learning
Jul 03, 20253D medical image self-supervised learning (mSSL) holds great promise for medical analysis. Effectively supporting broader applications requires considering anatomical structure variations in location, scale, and morphology, which are crucial for capturing meaningful distinctions. However, previous mSSL methods partition images with fixed-size patches, often ignoring the structure variations. In this work, we introduce a novel perspective on 3D medical images with the goal of learning structure-aware representations. We assume that patches within the same structure share the same semantics (semantic consistency) while those from different structures exhibit distinct semantics (semantic discrepancy). Based on this assumption, we propose an mSSL framework named $S^2DC$, achieving Structure-aware Semantic Discrepancy and Consistency in two steps. First, $S^2DC$ enforces distinct representations for different patches to increase semantic discrepancy by leveraging an optimal transport strategy. Second, $S^2DC$ advances semantic consistency at the structural level based on neighborhood similarity distribution. By bridging patch-level and structure-level representations, $S^2DC$ achieves structure-aware representations. Thoroughly evaluated across 10 datasets, 4 tasks, and 3 modalities, our proposed method consistently outperforms the state-of-the-art methods in mSSL.
SD-MAD: Sign-Driven Few-shot Multi-Anomaly Detection in Medical Images
May 22, 2025Medical anomaly detection (AD) is crucial for early clinical intervention, yet it faces challenges due to limited access to high-quality medical imaging data, caused by privacy concerns and data silos. Few-shot learning has emerged as a promising approach to alleviate these limitations by leveraging the large-scale prior knowledge embedded in vision-language models (VLMs). Recent advancements in few-shot medical AD have treated normal and abnormal cases as a one-class classification problem, often overlooking the distinction among multiple anomaly categories. Thus, in this paper, we propose a framework tailored for few-shot medical anomaly detection in the scenario where the identification of multiple anomaly categories is required. To capture the detailed radiological signs of medical anomaly categories, our framework incorporates diverse textual descriptions for each category generated by a Large-Language model, under the assumption that different anomalies in medical images may share common radiological signs in each category. Specifically, we introduce SD-MAD, a two-stage Sign-Driven few-shot Multi-Anomaly Detection framework: (i) Radiological signs are aligned with anomaly categories by amplifying inter-anomaly discrepancy; (ii) Aligned signs are selected further to mitigate the effect of the under-fitting and uncertain-sample issue caused by limited medical data, employing an automatic sign selection strategy at inference. Moreover, we propose three protocols to comprehensively quantify the performance of multi-anomaly detection. Extensive experiments illustrate the effectiveness of our method.
Personalize to generalize: Towards a universal medical multi-modality generalization through personalization
Nov 13, 2024The differences among medical imaging modalities, driven by distinct underlying principles, pose significant challenges for generalization in multi-modal medical tasks. Beyond modality gaps, individual variations, such as differences in organ size and metabolic rate, further impede a model's ability to generalize effectively across both modalities and diverse populations. Despite the importance of personalization, existing approaches to multi-modal generalization often neglect individual differences, focusing solely on common anatomical features. This limitation may result in weakened generalization in various medical tasks. In this paper, we unveil that personalization is critical for multi-modal generalization. Specifically, we propose an approach to achieve personalized generalization through approximating the underlying personalized invariant representation ${X}_h$ across various modalities by leveraging individual-level constraints and a learnable biological prior. We validate the feasibility and benefits of learning a personalized ${X}_h$, showing that this representation is highly generalizable and transferable across various multi-modal medical tasks. Extensive experimental results consistently show that the additionally incorporated personalization significantly improves performance and generalization across diverse scenarios, confirming its effectiveness.
Learning Segment Similarity and Alignment in Large-Scale Content Based Video Retrieval
Sep 20, 2023With the explosive growth of web videos in recent years, large-scale Content-Based Video Retrieval (CBVR) becomes increasingly essential in video filtering, recommendation, and copyright protection. Segment-level CBVR (S-CBVR) locates the start and end time of similar segments in finer granularity, which is beneficial for user browsing efficiency and infringement detection especially in long video scenarios. The challenge of S-CBVR task is how to achieve high temporal alignment accuracy with efficient computation and low storage consumption. In this paper, we propose a Segment Similarity and Alignment Network (SSAN) in dealing with the challenge which is firstly trained end-to-end in S-CBVR. SSAN is based on two newly proposed modules in video retrieval: (1) An efficient Self-supervised Keyframe Extraction (SKE) module to reduce redundant frame features, (2) A robust Similarity Pattern Detection (SPD) module for temporal alignment. In comparison with uniform frame extraction, SKE not only saves feature storage and search time, but also introduces comparable accuracy and limited extra computation time. In terms of temporal alignment, SPD localizes similar segments with higher accuracy and efficiency than existing deep learning methods. Furthermore, we jointly train SSAN with SKE and SPD and achieve an end-to-end improvement. Meanwhile, the two key modules SKE and SPD can also be effectively inserted into other video retrieval pipelines and gain considerable performance improvements. Experimental results on public datasets show that SSAN can obtain higher alignment accuracy while saving storage and online query computational cost compared to existing methods.
Boundary-aware Backward-Compatible Representation via Adversarial Learning in Image Retrieval
May 04, 2023Image retrieval plays an important role in the Internet world. Usually, the core parts of mainstream visual retrieval systems include an online service of the embedding model and a large-scale vector database. For traditional model upgrades, the old model will not be replaced by the new one until the embeddings of all the images in the database are re-computed by the new model, which takes days or weeks for a large amount of data. Recently, backward-compatible training (BCT) enables the new model to be immediately deployed online by making the new embeddings directly comparable to the old ones. For BCT, improving the compatibility of two models with less negative impact on retrieval performance is the key challenge. In this paper, we introduce AdvBCT, an Adversarial Backward-Compatible Training method with an elastic boundary constraint that takes both compatibility and discrimination into consideration. We first employ adversarial learning to minimize the distribution disparity between embeddings of the new model and the old model. Meanwhile, we add an elastic boundary constraint during training to improve compatibility and discrimination efficiently. Extensive experiments on GLDv2, Revisited Oxford (ROxford), and Revisited Paris (RParis) demonstrate that our method outperforms other BCT methods on both compatibility and discrimination. The implementation of AdvBCT will be publicly available at https://github.com/Ashespt/AdvBCT.
A Large-scale Comprehensive Dataset and Copy-overlap Aware Evaluation Protocol for Segment-level Video Copy Detection
Mar 05, 2022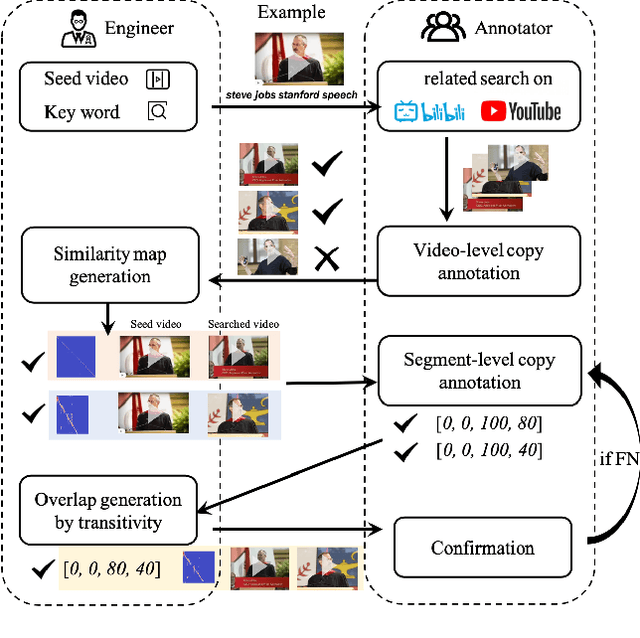
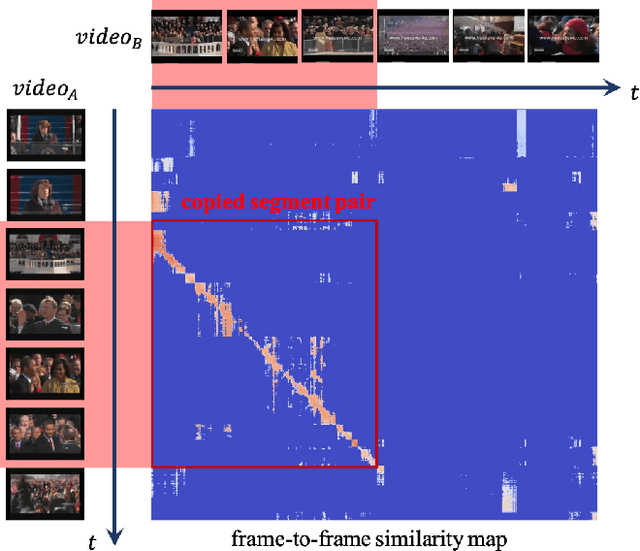
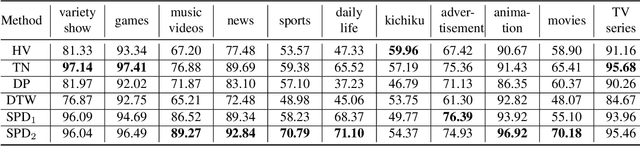
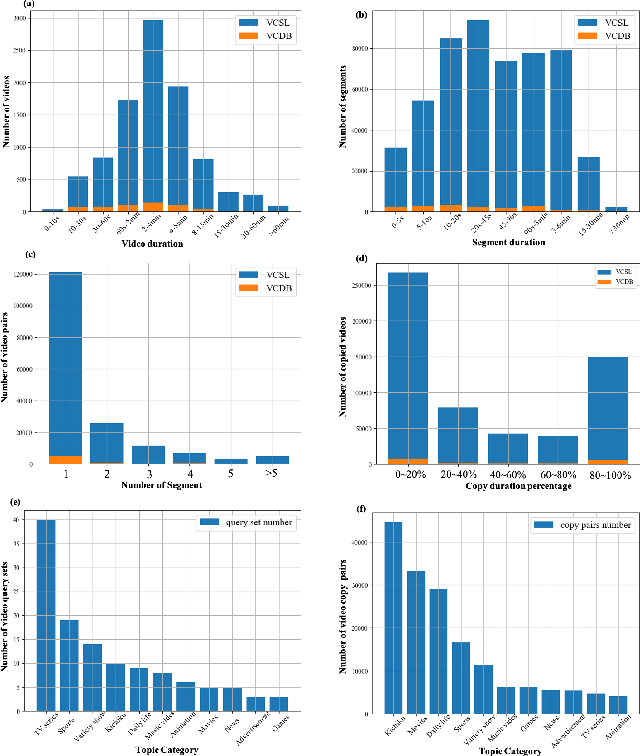
In this paper, we introduce VCSL (Video Copy Segment Localization), a new comprehensive segment-level annotated video copy dataset. Compared with existing copy detection datasets restricted by either video-level annotation or small-scale, VCSL not only has two orders of magnitude more segment-level labelled data, with 160k realistic video copy pairs containing more than 280k localized copied segment pairs, but also covers a variety of video categories and a wide range of video duration. All the copied segments inside each collected video pair are manually extracted and accompanied by precisely annotated starting and ending timestamps. Alongside the dataset, we also propose a novel evaluation protocol that better measures the prediction accuracy of copy overlapping segments between a video pair and shows improved adaptability in different scenarios. By benchmarking several baseline and state-of-the-art segment-level video copy detection methods with the proposed dataset and evaluation metric, we provide a comprehensive analysis that uncovers the strengths and weaknesses of current approaches, hoping to open up promising directions for future works. The VCSL dataset, metric and benchmark codes are all publicly available at https://github.com/alipay/VCSL.