 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSliceLens: Fine-Grained and Grounded Error Slice Discovery for Multi-Instance Vision Tasks
Dec 31, 2025Systematic failures of computer vision models on subsets with coherent visual patterns, known as error slices, pose a critical challenge for robust model evaluation. Existing slice discovery methods are primarily developed for image classification, limiting their applicability to multi-instance tasks such as detection, segmentation, and pose estimation. In real-world scenarios, error slices often arise from corner cases involving complex visual relationships, where existing instance-level approaches lacking fine-grained reasoning struggle to yield meaningful insights. Moreover, current benchmarks are typically tailored to specific algorithms or biased toward image classification, with artificial ground truth that fails to reflect real model failures. To address these limitations, we propose SliceLens, a hypothesis-driven framework that leverages LLMs and VLMs to generate and verify diverse failure hypotheses through grounded visual reasoning, enabling reliable identification of fine-grained and interpretable error slices. We further introduce FeSD (Fine-grained Slice Discovery), the first benchmark specifically designed for evaluating fine-grained error slice discovery across instance-level vision tasks, featuring expert-annotated and carefully refined ground-truth slices with precise grounding to local error regions. Extensive experiments on both existing benchmarks and FeSD demonstrate that SliceLens achieves state-of-the-art performance, improving Precision@10 by 0.42 (0.73 vs. 0.31) on FeSD, and identifies interpretable slices that facilitate actionable model improvements, as validated through model repair experiments.
Guiding Cross-Modal Representations with MLLM Priors via Preference Alignment
Jun 08, 2025Despite Contrastive Language-Image Pretraining (CLIP)'s remarkable capability to retrieve content across modalities, a substantial modality gap persists in its feature space. Intriguingly, we discover that off-the-shelf MLLMs (Multimodal Large Language Models) demonstrate powerful inherent modality alignment properties. While recent MLLM-based retrievers with unified architectures partially mitigate this gap, their reliance on coarse modality alignment mechanisms fundamentally limits their potential. In this work, We introduce MAPLE (Modality-Aligned Preference Learning for Embeddings), a novel framework that leverages the fine grained alignment priors inherent in MLLM to guide cross modal representation learning. MAPLE formulates the learning process as reinforcement learning with two key components: (1) Automatic preference data construction using off-the-shelf MLLM, and (2) a new Relative Preference Alignment (RPA) loss, which adapts Direct Preference Optimization (DPO) to the embedding learning setting. Experimental results show that our preference-guided alignment achieves substantial gains in fine-grained cross-modal retrieval, underscoring its effectiveness in handling nuanced semantic distinctions.
Let All be Whitened: Multi-teacher Distillation for Efficient Visual Retrieval
Dec 15, 2023



Visual retrieval aims to search for the most relevant visual items, e.g., images and videos, from a candidate gallery with a given query item. Accuracy and efficiency are two competing objectives in retrieval tasks. Instead of crafting a new method pursuing further improvement on accuracy, in this paper we propose a multi-teacher distillation framework Whiten-MTD, which is able to transfer knowledge from off-the-shelf pre-trained retrieval models to a lightweight student model for efficient visual retrieval. Furthermore, we discover that the similarities obtained by different retrieval models are diversified and incommensurable, which makes it challenging to jointly distill knowledge from multiple models. Therefore, we propose to whiten the output of teacher models before fusion, which enables effective multi-teacher distillation for retrieval models. Whiten-MTD is conceptually simple and practically effective. Extensive experiments on two landmark image retrieval datasets and one video retrieval dataset demonstrate the effectiveness of our proposed method, and its good balance of retrieval performance and efficiency. Our source code is released at https://github.com/Maryeon/whiten_mtd.
Learning Segment Similarity and Alignment in Large-Scale Content Based Video Retrieval
Sep 20, 2023With the explosive growth of web videos in recent years, large-scale Content-Based Video Retrieval (CBVR) becomes increasingly essential in video filtering, recommendation, and copyright protection. Segment-level CBVR (S-CBVR) locates the start and end time of similar segments in finer granularity, which is beneficial for user browsing efficiency and infringement detection especially in long video scenarios. The challenge of S-CBVR task is how to achieve high temporal alignment accuracy with efficient computation and low storage consumption. In this paper, we propose a Segment Similarity and Alignment Network (SSAN) in dealing with the challenge which is firstly trained end-to-end in S-CBVR. SSAN is based on two newly proposed modules in video retrieval: (1) An efficient Self-supervised Keyframe Extraction (SKE) module to reduce redundant frame features, (2) A robust Similarity Pattern Detection (SPD) module for temporal alignment. In comparison with uniform frame extraction, SKE not only saves feature storage and search time, but also introduces comparable accuracy and limited extra computation time. In terms of temporal alignment, SPD localizes similar segments with higher accuracy and efficiency than existing deep learning methods. Furthermore, we jointly train SSAN with SKE and SPD and achieve an end-to-end improvement. Meanwhile, the two key modules SKE and SPD can also be effectively inserted into other video retrieval pipelines and gain considerable performance improvements. Experimental results on public datasets show that SSAN can obtain higher alignment accuracy while saving storage and online query computational cost compared to existing methods.
Video Infringement Detection via Feature Disentanglement and Mutual Information Maximization
Sep 13, 2023The self-media era provides us tremendous high quality videos. Unfortunately, frequent video copyright infringements are now seriously damaging the interests and enthusiasm of video creators. Identifying infringing videos is therefore a compelling task. Current state-of-the-art methods tend to simply feed high-dimensional mixed video features into deep neural networks and count on the networks to extract useful representations. Despite its simplicity, this paradigm heavily relies on the original entangled features and lacks constraints guaranteeing that useful task-relevant semantics are extracted from the features. In this paper, we seek to tackle the above challenges from two aspects: (1) We propose to disentangle an original high-dimensional feature into multiple sub-features, explicitly disentangling the feature into exclusive lower-dimensional components. We expect the sub-features to encode non-overlapping semantics of the original feature and remove redundant information. (2) On top of the disentangled sub-features, we further learn an auxiliary feature to enhance the sub-features. We theoretically analyzed the mutual information between the label and the disentangled features, arriving at a loss that maximizes the extraction of task-relevant information from the original feature. Extensive experiments on two large-scale benchmark datasets (i.e., SVD and VCSL) demonstrate that our method achieves 90.1% TOP-100 mAP on the large-scale SVD dataset and also sets the new state-of-the-art on the VCSL benchmark dataset. Our code and model have been released at https://github.com/yyyooooo/DMI/, hoping to contribute to the community.
Boundary-aware Backward-Compatible Representation via Adversarial Learning in Image Retrieval
May 04, 2023Image retrieval plays an important role in the Internet world. Usually, the core parts of mainstream visual retrieval systems include an online service of the embedding model and a large-scale vector database. For traditional model upgrades, the old model will not be replaced by the new one until the embeddings of all the images in the database are re-computed by the new model, which takes days or weeks for a large amount of data. Recently, backward-compatible training (BCT) enables the new model to be immediately deployed online by making the new embeddings directly comparable to the old ones. For BCT, improving the compatibility of two models with less negative impact on retrieval performance is the key challenge. In this paper, we introduce AdvBCT, an Adversarial Backward-Compatible Training method with an elastic boundary constraint that takes both compatibility and discrimination into consideration. We first employ adversarial learning to minimize the distribution disparity between embeddings of the new model and the old model. Meanwhile, we add an elastic boundary constraint during training to improve compatibility and discrimination efficiently. Extensive experiments on GLDv2, Revisited Oxford (ROxford), and Revisited Paris (RParis) demonstrate that our method outperforms other BCT methods on both compatibility and discrimination. The implementation of AdvBCT will be publicly available at https://github.com/Ashespt/AdvBCT.
Web Photo Source Identification based on Neural Enhanced Camera Fingerprint
Feb 18, 2023With the growing popularity of smartphone photography in recent years, web photos play an increasingly important role in all walks of life. Source camera identification of web photos aims to establish a reliable linkage from the captured images to their source cameras, and has a broad range of applications, such as image copyright protection, user authentication, investigated evidence verification, etc. This paper presents an innovative and practical source identification framework that employs neural-network enhanced sensor pattern noise to trace back web photos efficiently while ensuring security. Our proposed framework consists of three main stages: initial device fingerprint registration, fingerprint extraction and cryptographic connection establishment while taking photos, and connection verification between photos and source devices. By incorporating metric learning and frequency consistency into the deep network design, our proposed fingerprint extraction algorithm achieves state-of-the-art performance on modern smartphone photos for reliable source identification. Meanwhile, we also propose several optimization sub-modules to prevent fingerprint leakage and improve accuracy and efficiency. Finally for practical system design, two cryptographic schemes are introduced to reliably identify the correlation between registered fingerprint and verified photo fingerprint, i.e. fuzzy extractor and zero-knowledge proof (ZKP). The codes for fingerprint extraction network and benchmark dataset with modern smartphone cameras photos are all publicly available at https://github.com/PhotoNecf/PhotoNecf.
TransVCL: Attention-enhanced Video Copy Localization Network with Flexible Supervision
Nov 24, 2022



Video copy localization aims to precisely localize all the copied segments within a pair of untrimmed videos in video retrieval applications. Previous methods typically start from frame-to-frame similarity matrix generated by cosine similarity between frame-level features of the input video pair, and then detect and refine the boundaries of copied segments on similarity matrix under temporal constraints. In this paper, we propose TransVCL: an attention-enhanced video copy localization network, which is optimized directly from initial frame-level features and trained end-to-end with three main components: a customized Transformer for feature enhancement, a correlation and softmax layer for similarity matrix generation, and a temporal alignment module for copied segments localization. In contrast to previous methods demanding the handcrafted similarity matrix, TransVCL incorporates long-range temporal information between feature sequence pair using self- and cross- attention layers. With the joint design and optimization of three components, the similarity matrix can be learned to present more discriminative copied patterns, leading to significant improvements over previous methods on segment-level labeled datasets (VCSL and VCDB). Besides the state-of-the-art performance in fully supervised setting, the attention architecture facilitates TransVCL to further exploit unlabeled or simply video-level labeled data. Additional experiments of supplementing video-level labeled datasets including SVD and FIVR reveal the high flexibility of TransVCL from full supervision to semi-supervision (with or without video-level annotation). Code is publicly available at https://github.com/transvcl/TransVCL.
A Large-scale Comprehensive Dataset and Copy-overlap Aware Evaluation Protocol for Segment-level Video Copy Detection
Mar 05, 2022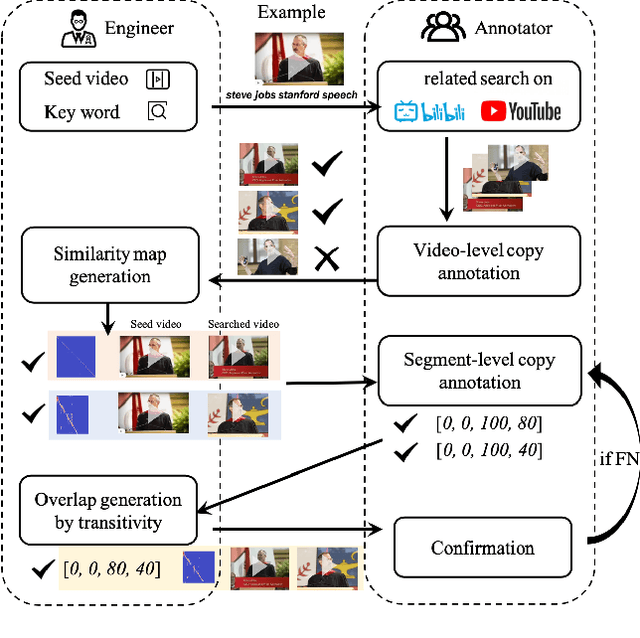
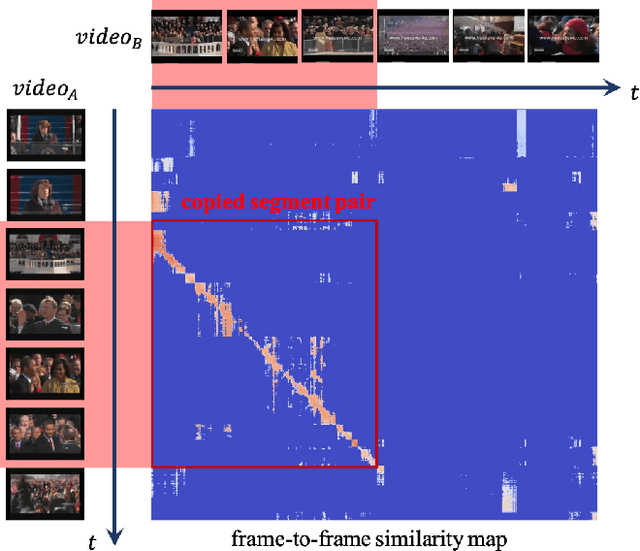
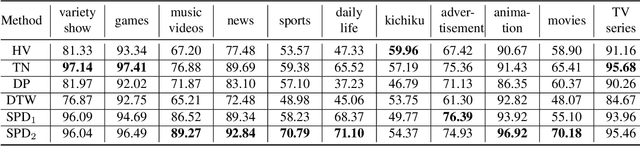
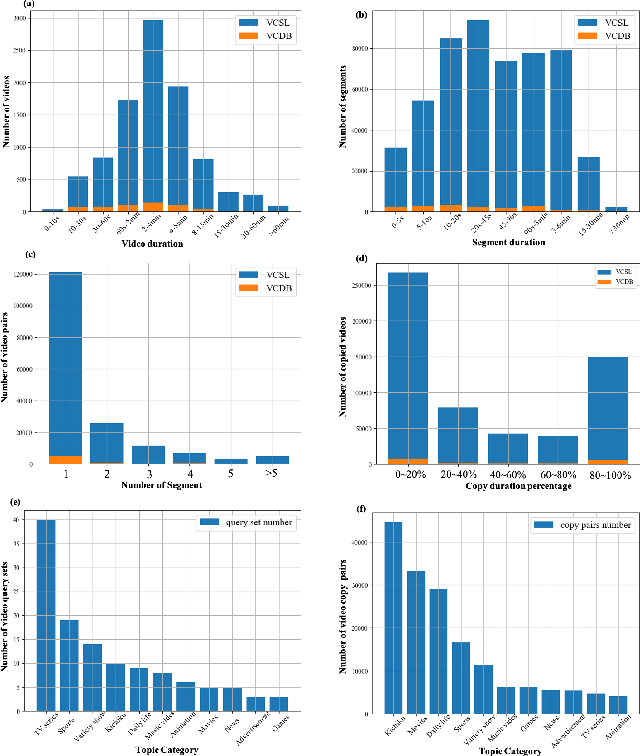
In this paper, we introduce VCSL (Video Copy Segment Localization), a new comprehensive segment-level annotated video copy dataset. Compared with existing copy detection datasets restricted by either video-level annotation or small-scale, VCSL not only has two orders of magnitude more segment-level labelled data, with 160k realistic video copy pairs containing more than 280k localized copied segment pairs, but also covers a variety of video categories and a wide range of video duration. All the copied segments inside each collected video pair are manually extracted and accompanied by precisely annotated starting and ending timestamps. Alongside the dataset, we also propose a novel evaluation protocol that better measures the prediction accuracy of copy overlapping segments between a video pair and shows improved adaptability in different scenarios. By benchmarking several baseline and state-of-the-art segment-level video copy detection methods with the proposed dataset and evaluation metric, we provide a comprehensive analysis that uncovers the strengths and weaknesses of current approaches, hoping to open up promising directions for future works. The VCSL dataset, metric and benchmark codes are all publicly available at https://github.com/alipay/VCSL.
Brain MRI Image Super Resolution using Phase Stretch Transform and Transfer Learning
Jul 31, 2018A hallucination-free and computationally efficient algorithm for enhancing the resolution of brain MRI images is demonstrated.