 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Infringement Detection via Feature Disentanglement and Mutual Information Maximization
Sep 13, 2023



The self-media era provides us tremendous high quality videos. Unfortunately, frequent video copyright infringements are now seriously damaging the interests and enthusiasm of video creators. Identifying infringing videos is therefore a compelling task. Current state-of-the-art methods tend to simply feed high-dimensional mixed video features into deep neural networks and count on the networks to extract useful representations. Despite its simplicity, this paradigm heavily relies on the original entangled features and lacks constraints guaranteeing that useful task-relevant semantics are extracted from the features. In this paper, we seek to tackle the above challenges from two aspects: (1) We propose to disentangle an original high-dimensional feature into multiple sub-features, explicitly disentangling the feature into exclusive lower-dimensional components. We expect the sub-features to encode non-overlapping semantics of the original feature and remove redundant information. (2) On top of the disentangled sub-features, we further learn an auxiliary feature to enhance the sub-features. We theoretically analyzed the mutual information between the label and the disentangled features, arriving at a loss that maximizes the extraction of task-relevant information from the original feature. Extensive experiments on two large-scale benchmark datasets (i.e., SVD and VCSL) demonstrate that our method achieves 90.1% TOP-100 mAP on the large-scale SVD dataset and also sets the new state-of-the-art on the VCSL benchmark dataset. Our code and model have been released at https://github.com/yyyooooo/DMI/, hoping to contribute to the community.
FedRecAttack: Model Poisoning Attack to Federated Recommendation
Apr 01, 2022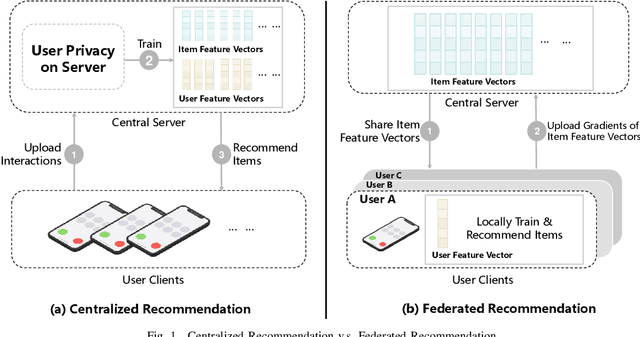
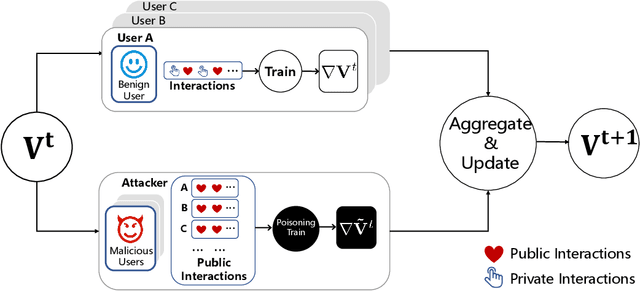
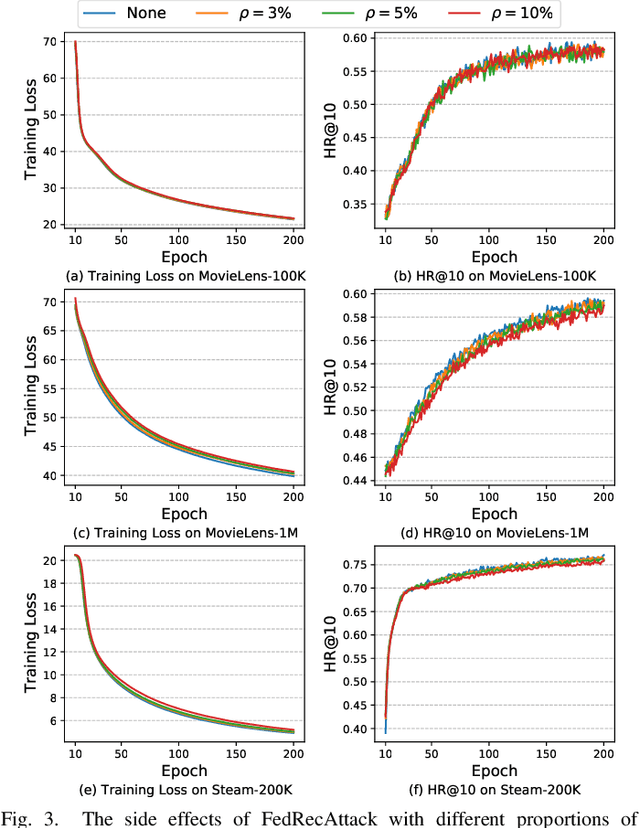

Federated Recommendation (FR) has received considerable popularity and attention in the past few years. In FR, for each user, its feature vector and interaction data are kept locally on its own client thus are private to others. Without the access to above information, most existing poisoning attacks against recommender systems or federated learning lose validity. Benifiting from this characteristic, FR is commonly considered fairly secured. However, we argue that there is still possible and necessary security improvement could be made in FR. To prove our opinion, in this paper we present FedRecAttack, a model poisoning attack to FR aiming to raise the exposure ratio of target items. In most recommendation scenarios, apart from private user-item interactions (e.g., clicks, watches and purchases), some interactions are public (e.g., likes, follows and comments). Motivated by this point, in FedRecAttack we make use of the public interactions to approximate users' feature vectors, thereby attacker can generate poisoned gradients accordingly and control malicious users to upload the poisoned gradients in a well-designed way. To evaluate the effectiveness and side effects of FedRecAttack, we conduct extensive experiments on three real-world datasets of different sizes from two completely different scenarios. Experimental results demonstrate that our proposed FedRecAttack achieves the state-of-the-art effectiveness while its side effects are negligible. Moreover, even with small proportion (3%) of malicious users and small proportion (1%) of public interactions, FedRecAttack remains highly effective, which reveals that FR is more vulnerable to attack than people commonly considered.