 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Unsupervised Task-driven Models of Ventral Visual Stream via Relative Position Predictivity
May 13, 2025Based on the concept that ventral visual stream (VVS) mainly functions for object recognition, current unsupervised task-driven methods model VVS by contrastive learning, and have achieved good brain similarity. However, we believe functions of VVS extend beyond just object recognition. In this paper, we introduce an additional function involving VVS, named relative position (RP) prediction. We first theoretically explain contrastive learning may be unable to yield the model capability of RP prediction. Motivated by this, we subsequently integrate RP learning with contrastive learning, and propose a new unsupervised task-driven method to model VVS, which is more inline with biological reality. We conduct extensive experiments, demonstrating that: (i) our method significantly improves downstream performance of object recognition while enhancing RP predictivity; (ii) RP predictivity generally improves the model brain similarity. Our results provide strong evidence for the involvement of VVS in location perception (especially RP prediction) from a computational perspective.
Preventing the Popular Item Embedding Based Attack in Federated Recommendations
Feb 18, 2025



Privacy concerns have led to the rise of federated recommender systems (FRS), which can create personalized models across distributed clients. However, FRS is vulnerable to poisoning attacks, where malicious users manipulate gradients to promote their target items intentionally. Existing attacks against FRS have limitations, as they depend on specific models and prior knowledge, restricting their real-world applicability. In our exploration of practical FRS vulnerabilities, we devise a model-agnostic and prior-knowledge-free attack, named PIECK (Popular Item Embedding based Attack). The core module of PIECK is popular item mining, which leverages embedding changes during FRS training to effectively identify the popular items. Built upon the core module, PIECK branches into two diverse solutions: The PIECKIPE solution employs an item popularity enhancement module, which aligns the embeddings of targeted items with the mined popular items to increase item exposure. The PIECKUEA further enhances the robustness of the attack by using a user embedding approximation module, which approximates private user embeddings using mined popular items. Upon identifying PIECK, we evaluate existing federated defense methods and find them ineffective against PIECK, as poisonous gradients inevitably overwhelm the cold target items. We then propose a novel defense method by introducing two regularization terms during user training, which constrain item popularity enhancement and user embedding approximation while preserving FRS performance. We evaluate PIECK and its defense across two base models, three real datasets, four top-tier attacks, and six general defense methods, affirming the efficacy of both PIECK and its defense.
Blockchain-based Federated Recommendation with Incentive Mechanism
Sep 03, 2024


Nowadays, federated recommendation technology is rapidly evolving to help multiple organisations share data and train models while meeting user privacy, data security and government regulatory requirements. However, federated recommendation increases customer system costs such as power, computational and communication resources. Besides, federated recommendation systems are also susceptible to model attacks and data poisoning by participating malicious clients. Therefore, most customers are unwilling to participate in federated recommendation without any incentive. To address these problems, we propose a blockchain-based federated recommendation system with incentive mechanism to promote more trustworthy, secure, and efficient federated recommendation service. First, we construct a federated recommendation system based on NeuMF and FedAvg. Then we introduce a reverse auction mechanism to select optimal clients that can maximize the social surplus. Finally, we employ blockchain for on-chain evidence storage of models to ensure the safety of the federated recommendation system. The experimental results show that our proposed incentive mechanism can attract clients with superior training data to engage in the federal recommendation at a lower cost, which can increase the economic benefit of federal recommendation by 54.9\% while improve the recommendation performance. Thus our work provides theoretical and technological support for the construction of a harmonious and healthy ecological environment for the application of federal recommendation.
Speed-enhanced Subdomain Adaptation Regression for Long-term Stable Neural Decoding in Brain-computer Interfaces
Jul 25, 2024



Brain-computer interfaces (BCIs) offer a means to convert neural signals into control signals, providing a potential restoration of movement for people with paralysis. Despite their promise, BCIs face a significant challenge in maintaining decoding accuracy over time due to neural nonstationarities. However, the decoding accuracy of BCI drops severely across days due to the neural data drift. While current recalibration techniques address this issue to a degree, they often fail to leverage the limited labeled data, to consider the signal correlation between two days, or to perform conditional alignment in regression tasks. This paper introduces a novel approach to enhance recalibration performance. We begin with preliminary experiments that reveal the temporal patterns of neural signal changes and identify three critical elements for effective recalibration: global alignment, conditional speed alignment, and feature-label consistency. Building on these insights, we propose the Speed-enhanced Subdomain Adaptation Regression (SSAR) framework, integrating semi-supervised learning with domain adaptation techniques in regression neural decoding. SSAR employs Speed-enhanced Subdomain Alignment (SeSA) for global and speed conditional alignment of similarly labeled data, with Contrastive Consistency Constraint (CCC) to enhance the alignment of SeSA by reinforcing feature-label consistency through contrastive learning. Our comprehensive set of experiments, both qualitative and quantitative, substantiate the superior recalibration performance and robustness of SSAR.
Clean-image Backdoor Attacks
Mar 26, 2024



To gather a significant quantity of annotated training data for high-performance image classification models, numerous companies opt to enlist third-party providers to label their unlabeled data. This practice is widely regarded as secure, even in cases where some annotated errors occur, as the impact of these minor inaccuracies on the final performance of the models is negligible and existing backdoor attacks require attacker's ability to poison the training images. Nevertheless, in this paper, we propose clean-image backdoor attacks which uncover that backdoors can still be injected via a fraction of incorrect labels without modifying the training images. Specifically, in our attacks, the attacker first seeks a trigger feature to divide the training images into two parts: those with the feature and those without it. Subsequently, the attacker falsifies the labels of the former part to a backdoor class. The backdoor will be finally implanted into the target model after it is trained on the poisoned data. During the inference phase, the attacker can activate the backdoor in two ways: slightly modifying the input image to obtain the trigger feature, or taking an image that naturally has the trigger feature as input. We conduct extensive experiments to demonstrate the effectiveness and practicality of our attacks. According to the experimental results, we conclude that our attacks seriously jeopardize the fairness and robustness of image classification models, and it is necessary to be vigilant about the incorrect labels in outsourced labeling.
CoMeta: Enhancing Meta Embeddings with Collaborative Information in Cold-start Problem of Recommendation
Mar 14, 2023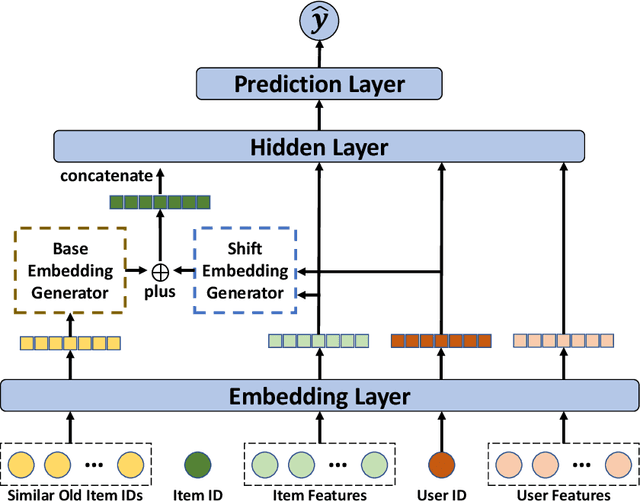

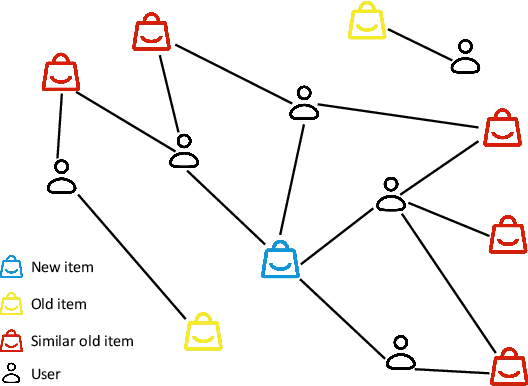
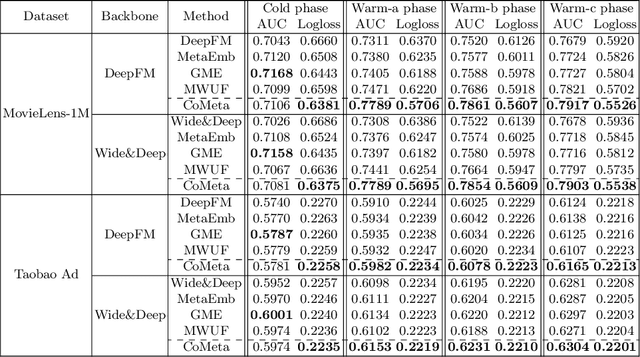
The cold-start problem is quite challenging for existing recommendation models. Specifically, for the new items with only a few interactions, their ID embeddings are trained inadequately, leading to poor recommendation performance. Some recent studies introduce meta learning to solve the cold-start problem by generating meta embeddings for new items as their initial ID embeddings. However, we argue that the capability of these methods is limited, because they mainly utilize item attribute features which only contain little information, but ignore the useful collaborative information contained in the ID embeddings of users and old items. To tackle this issue, we propose CoMeta to enhance the meta embeddings with the collaborative information. CoMeta consists of two submodules: B-EG and S-EG. Specifically, for a new item: B-EG calculates the similarity-based weighted sum of the ID embeddings of old items as its base embedding; S-EG generates its shift embedding not only with its attribute features but also with the average ID embedding of the users who interacted with it. The final meta embedding is obtained by adding up the base embedding and the shift embedding. We conduct extensive experiments on two public datasets. The experimental results demonstrate both the effectiveness and the compatibility of CoMeta.
Poisoning Deep Learning based Recommender Model in Federated Learning Scenarios
Apr 26, 2022

Various attack methods against recommender systems have been proposed in the past years, and the security issues of recommender systems have drawn considerable attention. Traditional attacks attempt to make target items recommended to as many users as possible by poisoning the training data. Benifiting from the feature of protecting users' private data, federated recommendation can effectively defend such attacks. Therefore, quite a few works have devoted themselves to developing federated recommender systems. For proving current federated recommendation is still vulnerable, in this work we probe to design attack approaches targeting deep learning based recommender models in federated learning scenarios. Specifically, our attacks generate poisoned gradients for manipulated malicious users to upload based on two strategies (i.e., random approximation and hard user mining). Extensive experiments show that our well-designed attacks can effectively poison the target models, and the attack effectiveness sets the state-of-the-art.
FedRecAttack: Model Poisoning Attack to Federated Recommendation
Apr 01, 2022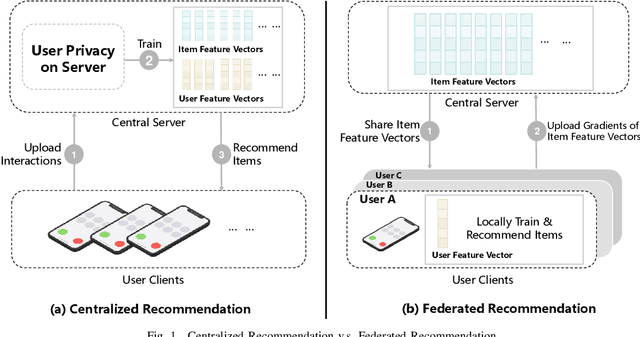
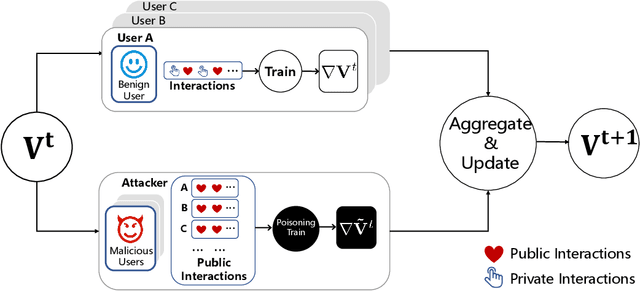
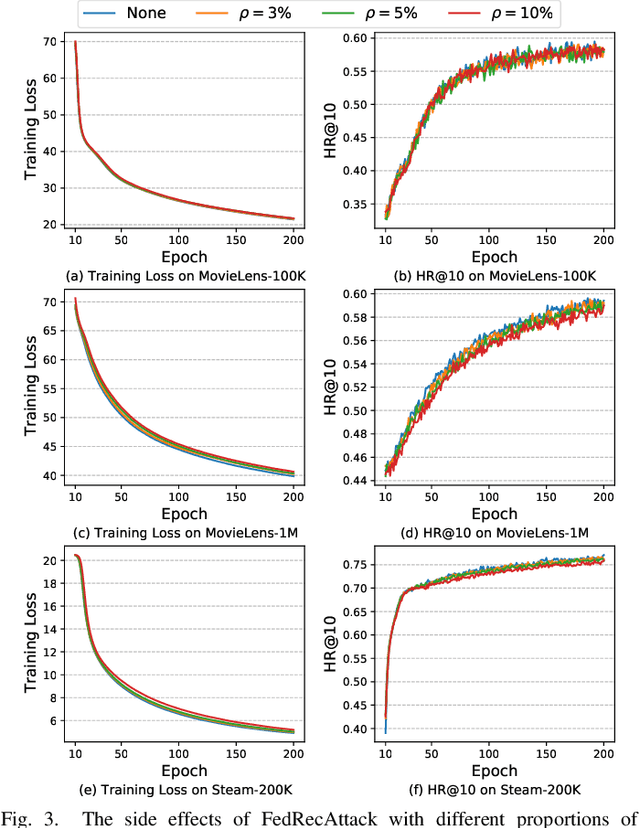

Federated Recommendation (FR) has received considerable popularity and attention in the past few years. In FR, for each user, its feature vector and interaction data are kept locally on its own client thus are private to others. Without the access to above information, most existing poisoning attacks against recommender systems or federated learning lose validity. Benifiting from this characteristic, FR is commonly considered fairly secured. However, we argue that there is still possible and necessary security improvement could be made in FR. To prove our opinion, in this paper we present FedRecAttack, a model poisoning attack to FR aiming to raise the exposure ratio of target items. In most recommendation scenarios, apart from private user-item interactions (e.g., clicks, watches and purchases), some interactions are public (e.g., likes, follows and comments). Motivated by this point, in FedRecAttack we make use of the public interactions to approximate users' feature vectors, thereby attacker can generate poisoned gradients accordingly and control malicious users to upload the poisoned gradients in a well-designed way. To evaluate the effectiveness and side effects of FedRecAttack, we conduct extensive experiments on three real-world datasets of different sizes from two completely different scenarios. Experimental results demonstrate that our proposed FedRecAttack achieves the state-of-the-art effectiveness while its side effects are negligible. Moreover, even with small proportion (3%) of malicious users and small proportion (1%) of public interactions, FedRecAttack remains highly effective, which reveals that FR is more vulnerable to attack than people commonly considered.