 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugmenting Image Annotation: A Human-LMM Collaborative Framework for Efficient Object Selection and Label Generation
Mar 14, 2025Traditional image annotation tasks rely heavily on human effort for object selection and label assignment, making the process time-consuming and prone to decreased efficiency as annotators experience fatigue after extensive work. This paper introduces a novel framework that leverages the visual understanding capabilities of large multimodal models (LMMs), particularly GPT, to assist annotation workflows. In our proposed approach, human annotators focus on selecting objects via bounding boxes, while the LMM autonomously generates relevant labels. This human-AI collaborative framework enhances annotation efficiency by reducing the cognitive and time burden on human annotators. By analyzing the system's performance across various types of annotation tasks, we demonstrate its ability to generalize to tasks such as object recognition, scene description, and fine-grained categorization. Our proposed framework highlights the potential of this approach to redefine annotation workflows, offering a scalable and efficient solution for large-scale data labeling in computer vision. Finally, we discuss how integrating LMMs into the annotation pipeline can advance bidirectional human-AI alignment, as well as the challenges of alleviating the "endless annotation" burden in the face of information overload by shifting some of the work to AI.
Benchmarking Zero-Shot Facial Emotion Annotation with Large Language Models: A Multi-Class and Multi-Frame Approach in DailyLife
Feb 18, 2025This study investigates the feasibility and performance of using large language models (LLMs) to automatically annotate human emotions in everyday scenarios. We conducted experiments on the DailyLife subset of the publicly available FERV39k dataset, employing the GPT-4o-mini model for rapid, zero-shot labeling of key frames extracted from video segments. Under a seven-class emotion taxonomy ("Angry," "Disgust," "Fear," "Happy," "Neutral," "Sad," "Surprise"), the LLM achieved an average precision of approximately 50%. In contrast, when limited to ternary emotion classification (negative/neutral/positive), the average precision increased to approximately 64%. Additionally, we explored a strategy that integrates multiple frames within 1-2 second video clips to enhance labeling performance and reduce costs. The results indicate that this approach can slightly improve annotation accuracy. Overall, our preliminary findings highlight the potential application of zero-shot LLMs in human facial emotion annotation tasks, offering new avenues for reducing labeling costs and broadening the applicability of LLMs in complex multimodal environments.
Multi-Grained Preference Enhanced Transformer for Multi-Behavior Sequential Recommendation
Nov 19, 2024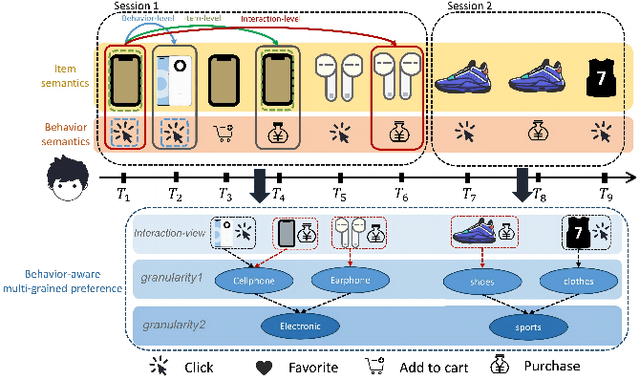
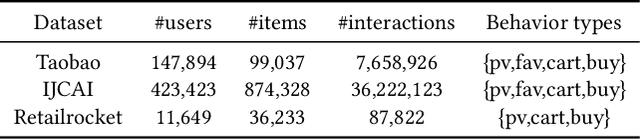
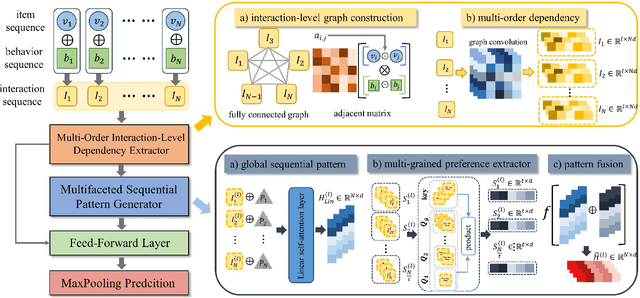
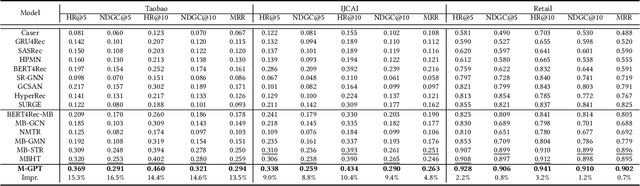
Sequential recommendation (SR) aims to predict the next purchasing item according to users' dynamic preference learned from their historical user-item interactions. To improve the performance of recommendation, learning dynamic heterogeneous cross-type behavior dependencies is indispensable for recommender system. However, there still exists some challenges in Multi-Behavior Sequential Recommendation (MBSR). On the one hand, existing methods only model heterogeneous multi-behavior dependencies at behavior-level or item-level, and modelling interaction-level dependencies is still a challenge. On the other hand, the dynamic multi-grained behavior-aware preference is hard to capture in interaction sequences, which reflects interaction-aware sequential pattern. To tackle these challenges, we propose a Multi-Grained Preference enhanced Transformer framework (M-GPT). First, M-GPT constructs a interaction-level graph of historical cross-typed interactions in a sequence. Then graph convolution is performed to derive interaction-level multi-behavior dependency representation repeatedly, in which the complex correlation between historical cross-typed interactions at specific orders can be well learned. Secondly, a novel multi-scale transformer architecture equipped with multi-grained user preference extraction is proposed to encode the interaction-aware sequential pattern enhanced by capturing temporal behavior-aware multi-grained preference . Experiments on the real-world datasets indicate that our method M-GPT consistently outperforms various state-of-the-art recommendation methods.
Clean-image Backdoor Attacks
Mar 26, 2024



To gather a significant quantity of annotated training data for high-performance image classification models, numerous companies opt to enlist third-party providers to label their unlabeled data. This practice is widely regarded as secure, even in cases where some annotated errors occur, as the impact of these minor inaccuracies on the final performance of the models is negligible and existing backdoor attacks require attacker's ability to poison the training images. Nevertheless, in this paper, we propose clean-image backdoor attacks which uncover that backdoors can still be injected via a fraction of incorrect labels without modifying the training images. Specifically, in our attacks, the attacker first seeks a trigger feature to divide the training images into two parts: those with the feature and those without it. Subsequently, the attacker falsifies the labels of the former part to a backdoor class. The backdoor will be finally implanted into the target model after it is trained on the poisoned data. During the inference phase, the attacker can activate the backdoor in two ways: slightly modifying the input image to obtain the trigger feature, or taking an image that naturally has the trigger feature as input. We conduct extensive experiments to demonstrate the effectiveness and practicality of our attacks. According to the experimental results, we conclude that our attacks seriously jeopardize the fairness and robustness of image classification models, and it is necessary to be vigilant about the incorrect labels in outsourced labeling.
PromptKD: Unsupervised Prompt Distillation for Vision-Language Models
Mar 09, 2024Prompt learning has emerged as a valuable technique in enhancing vision-language models (VLMs) such as CLIP for downstream tasks in specific domains. Existing work mainly focuses on designing various learning forms of prompts, neglecting the potential of prompts as effective distillers for learning from larger teacher models. In this paper, we introduce an unsupervised domain prompt distillation framework, which aims to transfer the knowledge of a larger teacher model to a lightweight target model through prompt-driven imitation using unlabeled domain images. Specifically, our framework consists of two distinct stages. In the initial stage, we pre-train a large CLIP teacher model using domain (few-shot) labels. After pre-training, we leverage the unique decoupled-modality characteristics of CLIP by pre-computing and storing the text features as class vectors only once through the teacher text encoder. In the subsequent stage, the stored class vectors are shared across teacher and student image encoders for calculating the predicted logits. Further, we align the logits of both the teacher and student models via KL divergence, encouraging the student image encoder to generate similar probability distributions to the teacher through the learnable prompts. The proposed prompt distillation process eliminates the reliance on labeled data, enabling the algorithm to leverage a vast amount of unlabeled images within the domain. Finally, the well-trained student image encoders and pre-stored text features (class vectors) are utilized for inference. To our best knowledge, we are the first to (1) perform unsupervised domain-specific prompt-driven knowledge distillation for CLIP, and (2) establish a practical pre-storing mechanism of text features as shared class vectors between teacher and student. Extensive experiments on 11 datasets demonstrate the effectiveness of our method.
VRMN-bD: A Multi-modal Natural Behavior Dataset of Immersive Human Fear Responses in VR Stand-up Interactive Games
Jan 22, 2024



Understanding and recognizing emotions are important and challenging issues in the metaverse era. Understanding, identifying, and predicting fear, which is one of the fundamental human emotions, in virtual reality (VR) environments plays an essential role in immersive game development, scene development, and next-generation virtual human-computer interaction applications. In this article, we used VR horror games as a medium to analyze fear emotions by collecting multi-modal data (posture, audio, and physiological signals) from 23 players. We used an LSTM-based model to predict fear with accuracies of 65.31% and 90.47% under 6-level classification (no fear and five different levels of fear) and 2-level classification (no fear and fear), respectively. We constructed a multi-modal natural behavior dataset of immersive human fear responses (VRMN-bD) and compared it with existing relevant advanced datasets. The results show that our dataset has fewer limitations in terms of collection method, data scale and audience scope. We are unique and advanced in targeting multi-modal datasets of fear and behavior in VR stand-up interactive environments. Moreover, we discussed the implications of this work for communities and applications. The dataset and pre-trained model are available at https://github.com/KindOPSTAR/VRMN-bD.
Privacy-preserving design of graph neural networks with applications to vertical federated learning
Oct 31, 2023



The paradigm of vertical federated learning (VFL), where institutions collaboratively train machine learning models via combining each other's local feature or label information, has achieved great success in applications to financial risk management (FRM). The surging developments of graph representation learning (GRL) have opened up new opportunities for FRM applications under FL via efficiently utilizing the graph-structured data generated from underlying transaction networks. Meanwhile, transaction information is often considered highly sensitive. To prevent data leakage during training, it is critical to develop FL protocols with formal privacy guarantees. In this paper, we present an end-to-end GRL framework in the VFL setting called VESPER, which is built upon a general privatization scheme termed perturbed message passing (PMP) that allows the privatization of many popular graph neural architectures.Based on PMP, we discuss the strengths and weaknesses of specific design choices of concrete graph neural architectures and provide solutions and improvements for both dense and sparse graphs. Extensive empirical evaluations over both public datasets and an industry dataset demonstrate that VESPER is capable of training high-performance GNN models over both sparse and dense graphs under reasonable privacy budgets.
Differentially Private Learning with Per-Sample Adaptive Clipping
Dec 01, 2022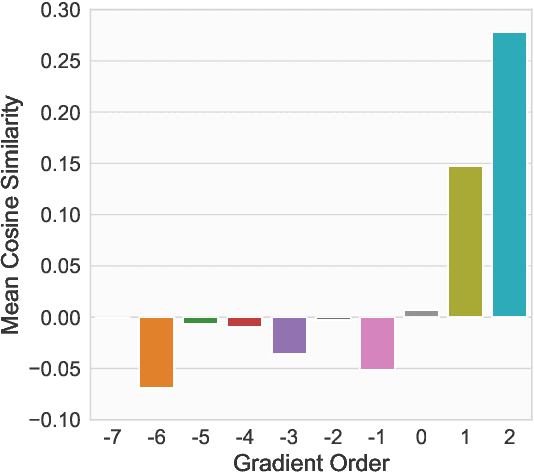

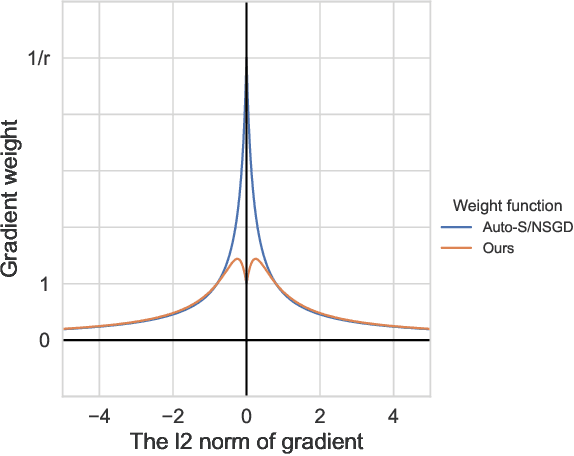
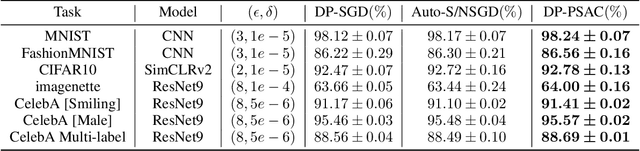
Privacy in AI remains a topic that draws attention from researchers and the general public in recent years. As one way to implement privacy-preserving AI, differentially private learning is a framework that enables AI models to use differential privacy (DP). To achieve DP in the learning process, existing algorithms typically limit the magnitude of gradients with a constant clipping, which requires carefully tuned due to its significant impact on model performance. As a solution to this issue, latest works NSGD and Auto-S innovatively propose to use normalization instead of clipping to avoid hyperparameter tuning. However, normalization-based approaches like NSGD and Auto-S rely on a monotonic weight function, which imposes excessive weight on small gradient samples and introduces extra deviation to the update. In this paper, we propose a Differentially Private Per-Sample Adaptive Clipping (DP-PSAC) algorithm based on a non-monotonic adaptive weight function, which guarantees privacy without the typical hyperparameter tuning process of using a constant clipping while significantly reducing the deviation between the update and true batch-averaged gradient. We provide a rigorous theoretical convergence analysis and show that with convergence rate at the same order, the proposed algorithm achieves a lower non-vanishing bound, which is maintained over training iterations, compared with NSGD/Auto-S. In addition, through extensive experimental evaluation, we show that DP-PSAC outperforms or matches the state-of-the-art methods on multiple main-stream vision and language tasks.