 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo-Only ToM: Enhancing Theory of Mind in Multimodal Large Language Models
Mar 25, 2026As large language models (LLMs) continue to advance, there is increasing interest in their ability to infer human mental states and demonstrate a human-like Theory of Mind (ToM). Most existing ToM evaluations, however, are centered on text-based inputs, while scenarios relying solely on visual information receive far less attention. This leaves a gap, since real-world human-AI interaction typically requires multimodal understanding. In addition, many current methods regard the model as a black box and rarely probe how its internal attention behaves in multiple-choice question answering (QA). The impact of LLM hallucinations on such tasks is also underexplored from an interpretability perspective. To address these issues, we introduce VisionToM, a vision-oriented intervention framework designed to strengthen task-aware reasoning. The core idea is to compute intervention vectors that align visual representations with the correct semantic targets, thereby steering the model's attention through different layers of visual features. This guidance reduces the model's reliance on spurious linguistic priors, leading to more reliable multimodal language model (MLLM) outputs and better QA performance. Experiments on the EgoToM benchmark-an egocentric, real-world video dataset for ToM with three multiple-choice QA settings-demonstrate that our method substantially improves the ToM abilities of MLLMs. Furthermore, results on an additional open-ended generation task show that VisionToM enables MLLMs to produce free-form explanations that more accurately capture agents' mental states, pushing machine-human collaboration toward greater alignment.
CustomTex: High-fidelity Indoor Scene Texturing via Multi-Reference Customization
Mar 19, 2026The creation of high-fidelity, customizable 3D indoor scene textures remains a significant challenge. While text-driven methods offer flexibility, they lack the precision for fine-grained, instance-level control, and often produce textures with insufficient quality, artifacts, and baked-in shading. To overcome these limitations, we introduce CustomTex, a novel framework for instance-level, high-fidelity scene texturing driven by reference images. CustomTex takes an untextured 3D scene and a set of reference images specifying the desired appearance for each object instance, and generates a unified, high-resolution texture map. The core of our method is a dual-distillation approach that separates semantic control from pixel-level enhancement. We employ semantic-level distillation, equipped with an instance cross-attention, to ensure semantic plausibility and ``reference-instance'' alignment, and pixel-level distillation to enforce high visual fidelity. Both are unified within a Variational Score Distillation (VSD) optimization framework. Experiments demonstrate that CustomTex achieves precise instance-level consistency with reference images and produces textures with superior sharpness, reduced artifacts, and minimal baked-in shading compared to state-of-the-art methods. Our work establishes a more direct and user-friendly path to high-quality, customizable 3D scene appearance editing.
Near-Field Multiuser Beam Training for XL-MIMO: An End-to-End Interference-Aware Approach with Pilot Limitations
Mar 12, 2026Near-field propagation in extremely large-scale MIMO (XL-MIMO) enlarges the beam training (BT) search space by introducing an additional range dimension, which makes conventional codebook-based beam sweeping prohibitively expensive under limited pilot resources, especially for multiuser sub-connected hybrid architectures. This letter proposes a deep-learning-based interference-aware multiuser BT framework (DL-IABT) that directly predicts analog beam indices from a small number of uplink sensing measurements. By exploiting a subarray-level approximation, a far-field codebook is adopted to represent each subarray response with negligible mismatch. To enable end-to-end (E2E) learning, we derive a variant-MSE surrogate loss by eliminating the digital precoder through a closed-form MMSE solution from KKT conditions, which implicitly accounts for multiuser interference (MUI). The proposed network integrates a complex-valued sensing front-end, a shared complex-valued encoder, a Transformer-based multiuser predictor, and a scalable Gumbel--Softmax beam selection head. Simulation results show that DL-IABT achieves near-optimal sum-rate performance while providing markedly higher effective throughput under pilot overhead constraints.
Indirect and Direct Multiuser Hybrid Beamforming for Far-Field and Near-Field Communications: A Deep Learning Approach
Mar 12, 2026Hybrid beamforming for extremely large-scale multiple-input multiple-output (XL-MIMO) systems is challenging in the near field because the channel depends jointly on angle and distance, and the multiuser interference (MUI) is strong. Existing deep learning methods typically follow either a decoupled design that optimizes analog beamforming without explicitly accounting for MUI, or an end-to-end (E2E) joint analog-digital optimization that can be unstable under nonconvex constant-modulus (CM), pronounced analog-digital coupling, and gradient pattern of sum-rate loss. To address both issues, we develop a complex-valued E2E framework based on a variant minimum mean square error (variant-MMSE) criterion, where the digital precoder is eliminated in closed form via Karush-Kuhn-Tucker (KKT) conditions so that analog learning is trained with a stable objective. The network employs a grouped complex-convolution sensing front-end for uplink (UL) measurements, a shared complex multi-layer perceptron (MLP) for per-user feature extraction, and a merged constant-modulus head to output the analog precoder. In the indirect mode, the network designs hybrid beamformers from estimated channel state information (CSI). In the direct mode where explicit CSI is unavailable, the network learns the sensing operator and the analog mapping from short pilots, after which additional pilots estimate the equivalent channel and enable a KKT closed-form digital precoder. Simulations show that the indirect mode approaches the performance of iterative variant-MMSE optimization with a complexity reduction proportional to the antenna number. In the direct mode, the proposed method improves spectral efficiency over sparse-recovery pipelines and recent deep learning baselines under the same pilot budget.
Deeper detection limits in astronomical imaging using self-supervised spatiotemporal denoising
Feb 19, 2026The detection limit of astronomical imaging observations is limited by several noise sources. Some of that noise is correlated between neighbouring image pixels and exposures, so in principle could be learned and corrected. We present an astronomical self-supervised transformer-based denoising algorithm (ASTERIS), that integrates spatiotemporal information across multiple exposures. Benchmarking on mock data indicates that ASTERIS improves detection limits by 1.0 magnitude at 90% completeness and purity, while preserving the point spread function and photometric accuracy. Observational validation using data from the James Webb Space Telescope (JWST) and Subaru telescope identifies previously undetectable features, including low-surface-brightness galaxy structures and gravitationally-lensed arcs. Applied to deep JWST images, ASTERIS identifies three times more redshift > 9 galaxy candidates, with rest-frame ultraviolet luminosity 1.0 magnitude fainter, than previous methods.
Real-Time Multi-Target Detection and Tracking with mmWave 5G NR Waveforms on RFSoC
Dec 27, 2025We demonstrate a real-time implementation of multi-target detection and tracking using 5G New Radio (NR) physical downlink shared channel (PDSCH) waveform with 400 MHz bandwidth at 28 GHz carrier frequency. The hardware platform is built on a radio frequency system-on-chip (RFSoC) 4x2 board connected with a pair of Sivers EVK02001 mmWave beamformers for transmission and reception. The entire sensing transceiver processing and fast beam control are realized purely in the programmable logic (PL) part of the RFSoC, enabling low-latency and fully hardware-accelerated operation. The continuously acquired sensing data constitute 3D range-angle (RA) tensors, which are processed on a host PC using adaptive background subtraction, cell-averaging constant false alarm rate (CA-CFAR) detection with density-based spatial clustering of applications with noise (DBSCAN) clustering, and extended Kalman filtering (EKF), to detect and track targets in the environment. Our software-defined radio (SDR) testbed integrates heterogeneous computing resources, including CPUs, GPUs, and FPGAs, thereby providing design flexibility for a wide range of tasks.
Variational Secret Common Randomness Extraction
Oct 02, 2025This paper studies the problem of extracting common randomness (CR) or secret keys from correlated random sources observed by two legitimate parties, Alice and Bob, through public discussion in the presence of an eavesdropper, Eve. We propose a practical two-stage CR extraction framework. In the first stage, the variational probabilistic quantization (VPQ) step is introduced, where Alice and Bob employ probabilistic neural network (NN) encoders to map their observations into discrete, nearly uniform random variables (RVs) with high agreement probability while minimizing information leakage to Eve. This is realized through a variational learning objective combined with adversarial training. In the second stage, a secure sketch using code-offset construction reconciles the encoder outputs into identical secret keys, whose secrecy is guaranteed by the VPQ objective. As a representative application, we study physical layer key (PLK) generation. Beyond the traditional methods, which rely on the channel reciprocity principle and require two-way channel probing, thus suffering from large protocol overhead and being unsuitable in high mobility scenarios, we propose a sensing-based PLK generation method for integrated sensing and communications (ISAC) systems, where paired range-angle (RA) maps measured at Alice and Bob serve as correlated sources. The idea is verified through both end-to-end simulations and real-world software-defined radio (SDR) measurements, including scenarios where Eve has partial knowledge about Bob's position. The results demonstrate the feasibility and convincing performance of both the proposed CR extraction framework and sensing-based PLK generation method.
JCo-MVTON: Jointly Controllable Multi-Modal Diffusion Transformer for Mask-Free Virtual Try-on
Aug 25, 2025
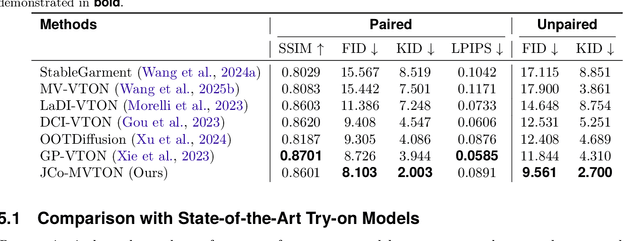
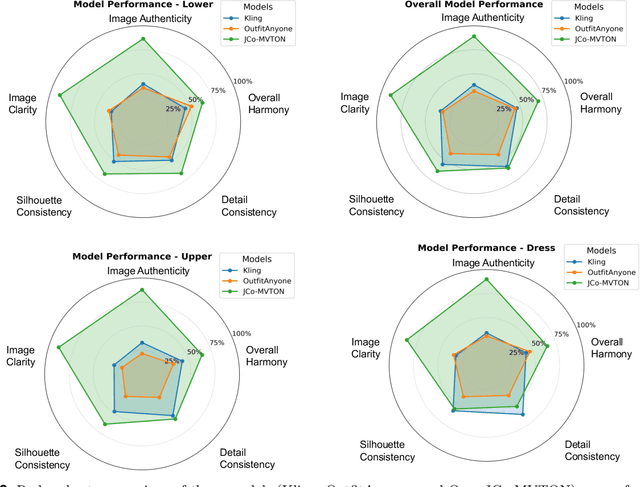
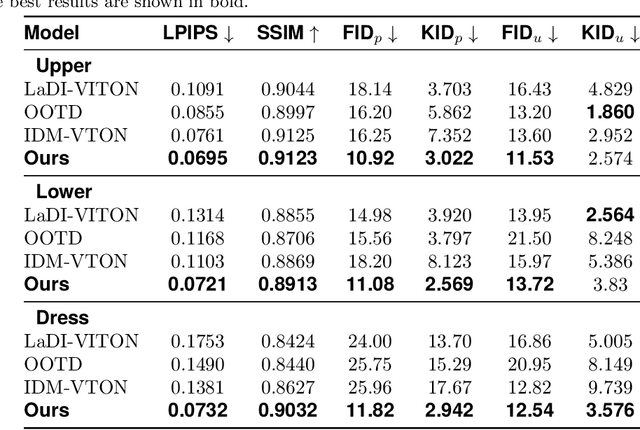
Virtual try-on systems have long been hindered by heavy reliance on human body masks, limited fine-grained control over garment attributes, and poor generalization to real-world, in-the-wild scenarios. In this paper, we propose JCo-MVTON (Jointly Controllable Multi-Modal Diffusion Transformer for Mask-Free Virtual Try-On), a novel framework that overcomes these limitations by integrating diffusion-based image generation with multi-modal conditional fusion. Built upon a Multi-Modal Diffusion Transformer (MM-DiT) backbone, our approach directly incorporates diverse control signals -- such as the reference person image and the target garment image -- into the denoising process through dedicated conditional pathways that fuse features within the self-attention layers. This fusion is further enhanced with refined positional encodings and attention masks, enabling precise spatial alignment and improved garment-person integration. To address data scarcity and quality, we introduce a bidirectional generation strategy for dataset construction: one pipeline uses a mask-based model to generate realistic reference images, while a symmetric ``Try-Off'' model, trained in a self-supervised manner, recovers the corresponding garment images. The synthesized dataset undergoes rigorous manual curation, allowing iterative improvement in visual fidelity and diversity. Experiments demonstrate that JCo-MVTON achieves state-of-the-art performance on public benchmarks including DressCode, significantly outperforming existing methods in both quantitative metrics and human evaluations. Moreover, it shows strong generalization in real-world applications, surpassing commercial systems.
XSpecMesh: Quality-Preserving Auto-Regressive Mesh Generation Acceleration via Multi-Head Speculative Decoding
Jul 31, 2025Current auto-regressive models can generate high-quality, topologically precise meshes; however, they necessitate thousands-or even tens of thousands-of next-token predictions during inference, resulting in substantial latency. We introduce XSpecMesh, a quality-preserving acceleration method for auto-regressive mesh generation models. XSpecMesh employs a lightweight, multi-head speculative decoding scheme to predict multiple tokens in parallel within a single forward pass, thereby accelerating inference. We further propose a verification and resampling strategy: the backbone model verifies each predicted token and resamples any tokens that do not meet the quality criteria. In addition, we propose a distillation strategy that trains the lightweight decoding heads by distilling from the backbone model, encouraging their prediction distributions to align and improving the success rate of speculative predictions. Extensive experiments demonstrate that our method achieves a 1.7x speedup without sacrificing generation quality. Our code will be released.
DeOcc-1-to-3: 3D De-Occlusion from a Single Image via Self-Supervised Multi-View Diffusion
Jun 26, 2025Reconstructing 3D objects from a single image is a long-standing challenge, especially under real-world occlusions. While recent diffusion-based view synthesis models can generate consistent novel views from a single RGB image, they generally assume fully visible inputs and fail when parts of the object are occluded. This leads to inconsistent views and degraded 3D reconstruction quality. To overcome this limitation, we propose an end-to-end framework for occlusion-aware multi-view generation. Our method directly synthesizes six structurally consistent novel views from a single partially occluded image, enabling downstream 3D reconstruction without requiring prior inpainting or manual annotations. We construct a self-supervised training pipeline using the Pix2Gestalt dataset, leveraging occluded-unoccluded image pairs and pseudo-ground-truth views to teach the model structure-aware completion and view consistency. Without modifying the original architecture, we fully fine-tune the view synthesis model to jointly learn completion and multi-view generation. Additionally, we introduce the first benchmark for occlusion-aware reconstruction, encompassing diverse occlusion levels, object categories, and mask patterns. This benchmark provides a standardized protocol for evaluating future methods under partial occlusions. Our code is available at https://github.com/Quyans/DeOcc123.