 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePACT: Proactive Asking for Continual Task Assistance in Human-Robot Collaboration
May 23, 2026Robotic assistants in long-term human-robot collaboration need to assist users under partial observations while leveraging cross-day interaction history. However, human traits and routines are often unknown at the beginning of collaboration, making passive infer-then-act assistance ineffective and inefficient. To address this challenge, we study a cross-day proactive asking setting for continual task assistance and propose PACT (Proactive Asking for Continual Task Assistance), an ask-or-act framework that determines whether clarification should be sought before taking action. PACT leverages current observations together with accumulated interaction history to evaluate contextual sufficiency, enabling the robot to provide more reliable assistance and progressively adapt to the user over time. We implement its primary learned instantiation using reinforcement learning and evaluate alternative instantiations under the same framework. To assess such behavior, we further introduce a clarification utility metric that quantifies the trade-off between assistance accuracy and the frequency of clarification requests. Experiments in multi-day embodied collaboration scenarios demonstrate that, compared with passive inference baselines, PACT consistently improves both assistance accuracy and clarification utility, highlighting the importance of proactive asking in continual human-robot collaboration.
Unposed-to-3D: Learning Simulation-Ready Vehicles from Real-World Images
Apr 21, 2026Creating realistic and simulation-ready 3D assets is crucial for autonomous driving research and virtual environment construction. However, existing 3D vehicle generation methods are often trained on synthetic data with significant domain gaps from real-world distributions. The generated models often exhibit arbitrary poses and undefined scales, resulting in poor visual consistency when integrated into driving scenes. In this paper, we present Unposed-to-3D, a novel framework that learns to reconstruct 3D vehicles from real-world driving images using image-only supervision. Our approach consists of two stages. In the first stage, we train an image-to-3D reconstruction network using posed images with known camera parameters. In the second stage, we remove camera supervision and use a camera prediction head that directly estimates the camera parameters from unposed images. The predicted pose is then used for differentiable rendering to provide self-supervised photometric feedback, enabling the model to learn 3D geometry purely from unposed images. To ensure simulation readiness, we further introduce a scale-aware module to predict real-world size information, and a harmonization module that adapts the generated vehicles to the target driving scene with consistent lighting and appearance. Extensive experiments demonstrate that Unposed-to-3D effectively reconstructs realistic, pose-consistent, and harmonized 3D vehicle models from real-world images, providing a scalable path toward creating high-quality assets for driving scene simulation and digital twin environments.
FreqPhys: Repurposing Implicit Physiological Frequency Prior for Robust Remote Photoplethysmography
Apr 01, 2026Remote photoplethysmography (rPPG) enables contactless physiological monitoring by capturing subtle skin-color variations from facial videos. However, most existing methods predominantly rely on time-domain modeling, making them vulnerable to motion artifacts and illumination fluctuations, where weak physiological clues are easily overwhelmed by noise. To address these challenges, we propose FreqPhys, a frequency-guided rPPG framework that explicitly leverages physiological frequency priors for robust signal recovery. Specifically, FreqPhys first applies a Physiological Bandpass Filtering module to suppress out-of-band interference, and then performs Physiological Spectrum Modulation together with adaptive spectral selection to emphasize pulse-related frequency components while suppress residual in-band noise. A Cross-domain Representation Learning module further fuses these spectral priors with deep time-domain features to capture informative spatial--temporal dependencies. Finally, a frequency-aware conditional diffusion process progressively reconstructs high-fidelity rPPG signals. Extensive experiments on six benchmarks demonstrate that FreqPhys yields significant improvements over state-of-the-art approaches, particularly under challenging motion conditions. It highlights the importance of explicitly modeling physiological frequency priors. The source code will be released.
Video-Only ToM: Enhancing Theory of Mind in Multimodal Large Language Models
Mar 25, 2026As large language models (LLMs) continue to advance, there is increasing interest in their ability to infer human mental states and demonstrate a human-like Theory of Mind (ToM). Most existing ToM evaluations, however, are centered on text-based inputs, while scenarios relying solely on visual information receive far less attention. This leaves a gap, since real-world human-AI interaction typically requires multimodal understanding. In addition, many current methods regard the model as a black box and rarely probe how its internal attention behaves in multiple-choice question answering (QA). The impact of LLM hallucinations on such tasks is also underexplored from an interpretability perspective. To address these issues, we introduce VisionToM, a vision-oriented intervention framework designed to strengthen task-aware reasoning. The core idea is to compute intervention vectors that align visual representations with the correct semantic targets, thereby steering the model's attention through different layers of visual features. This guidance reduces the model's reliance on spurious linguistic priors, leading to more reliable multimodal language model (MLLM) outputs and better QA performance. Experiments on the EgoToM benchmark-an egocentric, real-world video dataset for ToM with three multiple-choice QA settings-demonstrate that our method substantially improves the ToM abilities of MLLMs. Furthermore, results on an additional open-ended generation task show that VisionToM enables MLLMs to produce free-form explanations that more accurately capture agents' mental states, pushing machine-human collaboration toward greater alignment.
Boosting Micro-Expression Analysis via Prior-Guided Video-Level Regression
Aug 26, 2025Micro-expressions (MEs) are involuntary, low-intensity, and short-duration facial expressions that often reveal an individual's genuine thoughts and emotions. Most existing ME analysis methods rely on window-level classification with fixed window sizes and hard decisions, which limits their ability to capture the complex temporal dynamics of MEs. Although recent approaches have adopted video-level regression frameworks to address some of these challenges, interval decoding still depends on manually predefined, window-based methods, leaving the issue only partially mitigated. In this paper, we propose a prior-guided video-level regression method for ME analysis. We introduce a scalable interval selection strategy that comprehensively considers the temporal evolution, duration, and class distribution characteristics of MEs, enabling precise spotting of the onset, apex, and offset phases. In addition, we introduce a synergistic optimization framework, in which the spotting and recognition tasks share parameters except for the classification heads. This fully exploits complementary information, makes more efficient use of limited data, and enhances the model's capability. Extensive experiments on multiple benchmark datasets demonstrate the state-of-the-art performance of our method, with an STRS of 0.0562 on CAS(ME)$^3$ and 0.2000 on SAMMLV. The code is available at https://github.com/zizheng-guo/BoostingVRME.
ME-TST+: Micro-expression Analysis via Temporal State Transition with ROI Relationship Awareness
Aug 11, 2025Micro-expressions (MEs) are regarded as important indicators of an individual's intrinsic emotions, preferences, and tendencies. ME analysis requires spotting of ME intervals within long video sequences and recognition of their corresponding emotional categories. Previous deep learning approaches commonly employ sliding-window classification networks. However, the use of fixed window lengths and hard classification presents notable limitations in practice. Furthermore, these methods typically treat ME spotting and recognition as two separate tasks, overlooking the essential relationship between them. To address these challenges, this paper proposes two state space model-based architectures, namely ME-TST and ME-TST+, which utilize temporal state transition mechanisms to replace conventional window-level classification with video-level regression. This enables a more precise characterization of the temporal dynamics of MEs and supports the modeling of MEs with varying durations. In ME-TST+, we further introduce multi-granularity ROI modeling and the slowfast Mamba framework to alleviate information loss associated with treating ME analysis as a time-series task. Additionally, we propose a synergy strategy for spotting and recognition at both the feature and result levels, leveraging their intrinsic connection to enhance overall analysis performance. Extensive experiments demonstrate that the proposed methods achieve state-of-the-art performance. The codes are available at https://github.com/zizheng-guo/ME-TST.
From Black Boxes to Transparent Minds: Evaluating and Enhancing the Theory of Mind in Multimodal Large Language Models
Jun 17, 2025As large language models evolve, there is growing anticipation that they will emulate human-like Theory of Mind (ToM) to assist with routine tasks. However, existing methods for evaluating machine ToM focus primarily on unimodal models and largely treat these models as black boxes, lacking an interpretative exploration of their internal mechanisms. In response, this study adopts an approach based on internal mechanisms to provide an interpretability-driven assessment of ToM in multimodal large language models (MLLMs). Specifically, we first construct a multimodal ToM test dataset, GridToM, which incorporates diverse belief testing tasks and perceptual information from multiple perspectives. Next, our analysis shows that attention heads in multimodal large models can distinguish cognitive information across perspectives, providing evidence of ToM capabilities. Furthermore, we present a lightweight, training-free approach that significantly enhances the model's exhibited ToM by adjusting in the direction of the attention head.
DeCoDe: Defer-and-Complement Decision-Making via Decoupled Concept Bottleneck Models
May 25, 2025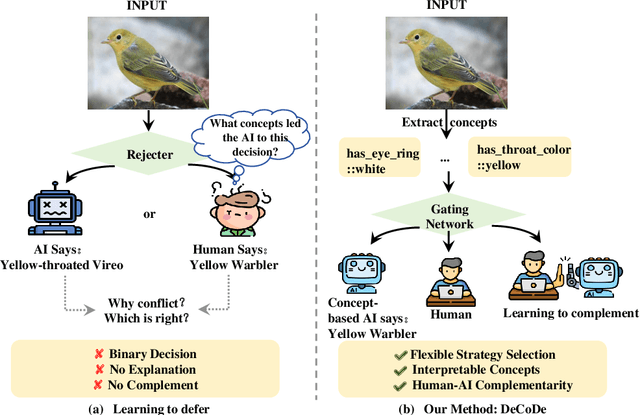
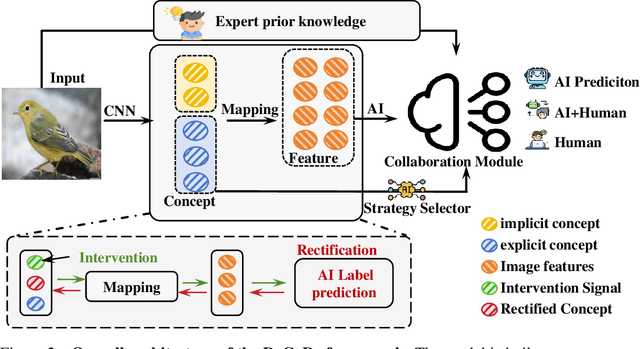
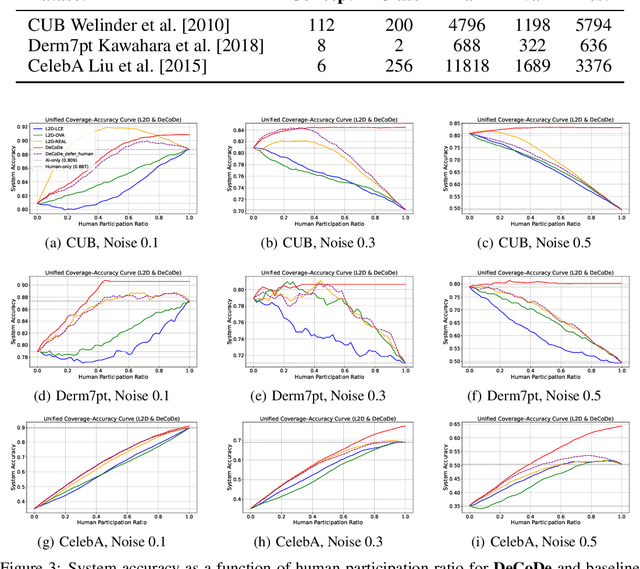

In human-AI collaboration, a central challenge is deciding whether the AI should handle a task, be deferred to a human expert, or be addressed through collaborative effort. Existing Learning to Defer approaches typically make binary choices between AI and humans, neglecting their complementary strengths. They also lack interpretability, a critical property in high-stakes scenarios where users must understand and, if necessary, correct the model's reasoning. To overcome these limitations, we propose Defer-and-Complement Decision-Making via Decoupled Concept Bottleneck Models (DeCoDe), a concept-driven framework for human-AI collaboration. DeCoDe makes strategy decisions based on human-interpretable concept representations, enhancing transparency throughout the decision process. It supports three flexible modes: autonomous AI prediction, deferral to humans, and human-AI collaborative complementarity, selected via a gating network that takes concept-level inputs and is trained using a novel surrogate loss that balances accuracy and human effort. This approach enables instance-specific, interpretable, and adaptive human-AI collaboration. Experiments on real-world datasets demonstrate that DeCoDe significantly outperforms AI-only, human-only, and traditional deferral baselines, while maintaining strong robustness and interpretability even under noisy expert annotations.
Enhancing LLM Reasoning with Multi-Path Collaborative Reactive and Reflection agents
Jan 03, 2025



Agents have demonstrated their potential in scientific reasoning tasks through large language models. However, they often face challenges such as insufficient accuracy and degeneration of thought when handling complex reasoning tasks, which impede their performance. To overcome these issues, we propose the Reactive and Reflection agents with Multi-Path Reasoning (RR-MP) Framework, aimed at enhancing the reasoning capabilities of LLMs. Our approach improves scientific reasoning accuracy by employing a multi-path reasoning mechanism where each path consists of a reactive agent and a reflection agent that collaborate to prevent degeneration of thought inherent in single-agent reliance. Additionally, the RR-MP framework does not require additional training; it utilizes multiple dialogue instances for each reasoning path and a separate summarizer to consolidate insights from all paths. This design integrates diverse perspectives and strengthens reasoning across each path. We conducted zero-shot and few-shot evaluations on tasks involving moral scenarios, college-level physics, and mathematics. Experimental results demonstrate that our method outperforms baseline approaches, highlighting the effectiveness and advantages of the RR-MP framework in managing complex scientific reasoning tasks.
A2RNet: Adversarial Attack Resilient Network for Robust Infrared and Visible Image Fusion
Dec 18, 2024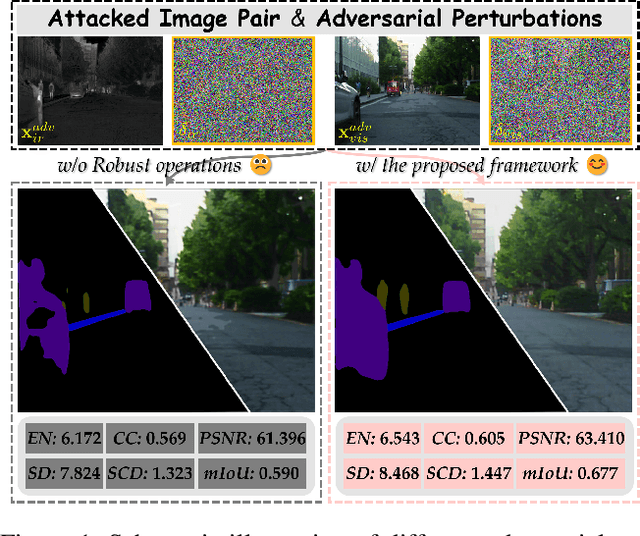

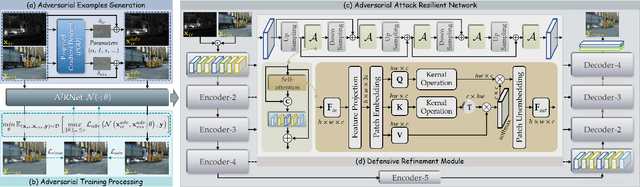

Infrared and visible image fusion (IVIF) is a crucial technique for enhancing visual performance by integrating unique information from different modalities into one fused image. Exiting methods pay more attention to conducting fusion with undisturbed data, while overlooking the impact of deliberate interference on the effectiveness of fusion results. To investigate the robustness of fusion models, in this paper, we propose a novel adversarial attack resilient network, called $\textrm{A}^{\textrm{2}}$RNet. Specifically, we develop an adversarial paradigm with an anti-attack loss function to implement adversarial attacks and training. It is constructed based on the intrinsic nature of IVIF and provide a robust foundation for future research advancements. We adopt a Unet as the pipeline with a transformer-based defensive refinement module (DRM) under this paradigm, which guarantees fused image quality in a robust coarse-to-fine manner. Compared to previous works, our method mitigates the adverse effects of adversarial perturbations, consistently maintaining high-fidelity fusion results. Furthermore, the performance of downstream tasks can also be well maintained under adversarial attacks. Code is available at https://github.com/lok-18/A2RNet.